언제 다음편이 올라올지 모르는 ARM Architecture 이야기 #1

#1. ARM 아키텍처 소개 Part.1
ARM의 역사
대부분 이런 류의 책이나 글을 거창하게 시작할 때는 역사 혹은 지금까지 발전해온 길을 쭉 훑으면서 시작한다. 물론 나도 이 글이 책으로 나오게 된다면 그 부분을 어떻게 해서든 찾아서 채워 놓을 것이다. 하지만 이 글에서는 그렇게 하지 않을 것이다. KLDP 블로그에 올리는 이 글은 원고의 초고이며 그렇기 때문에 나는 보다 자유롭고 편안하게 쓰고 싶다. 이 글을 읽는 여러분께 이야기하듯 쓰고 싶다. 따라서 아무리 내가 애를 써도 이해가 안되거나 쓰기 싫거나 불필요하다고 생각되는 내용은 쓰지 않을 것이다. ARM의 역사 같은 것은 위키페디아의 관련 페이지만 구글링해서 들어가면 아주 잘 설명되어 있다. 내가 굳이 여기에 또 옮겨 적을 필요는 없다고 생각한다.
이 글의 원본 텍스트는 Cortex-R5 Technical Reference Manual과 Cortex-A5 Technical Reference Manual 및 ARM Architecture Reference Manual이다. 따라서 기본적인 내용은 원본 텍스트의 통합 번역본이 될 것같다. 기본적인 순서는 이들 문서의 순서를 따르되 서술에 있어서 같은 내용은 묶고 다른 내용은 별도로 설명하여 이 글 하나만 읽으면 참조한 세 문서를 모두 읽은 효과가 나오길 기대하는 바람을 가지고 있다. 그리고 기계적인 번역보다는 참조 문서의 설명과 내가 가지고 있는 지식에서 부언 설명을 더해 더 읽기 편한 문서를 만들고자 노력할 것이다.
32비트 ARM 프로세서
일반적으로 Cortex-R5는 Cortex-R 계열을 대변하는 설명이 될 것이고, Cortex-A5에 관련한 내용은 Cortex-A 계열에 대한 공통적인 내용이 될 것이다. 아무래도 Cortex-R 계열이 하위 계열이므로 기본적인 내용이 될 것이고, Cortex-A 계열은 추가되는 기능 위주로 설명을 덧붙일 예정이다. 따라서 이 글의 모든 내용은 ARMv7-AR 아키텍처가 기본이 된다.
Cortex-R5와 Cortex-A5 두 코어는 모두 32비트 프로세서이다. 따라서 기본 버스 크기인 1 워드는 32비트로 4바이트이다. 당연히 하프워드는 16비트로 2바이트이다. 그리고 모든 레지스터의 크기도 32비트가 기준이다.
소프트웨어 프로그래머에게
나는 소프트웨어 프로그래머이다. 물론 복잡하지 않은 수준의 회로도를 보고 아주 초보적인 수준의 납땜을 할 줄 안다. 하지만 그걸 가지고 내가 하드웨어와 소프트웨어를 둘 다 잘한다고 할 순 없다. 난 소프트웨어만 할 줄 안다. 그나마도 잘 하지도 못한다. 그래서 ARM 아키텍처도 철저히 소프트웨어 프로그래머적 시점에서 바라보고 있고 이해하고 있다. 그리고 이 글도 소프트웨어 프로그래머를 대상으로 쓸 것이다.
ARM 아키텍처를 소프트웨어 프로그래머 시점에서 쓴다는 것은 다시 말해 펌웨어 개발자들에게 도움이 되는 글을 쓴다는 말이다. 우리나라를 포함해 전세계적으로 한글을 읽는 사람들 중 ARM 펌웨어 개발자가 몇 명이나 되는지 알 순 없지만, 그래도 난 그들을 위해 글을 쓰겠다. 따라서 ARM의 하드웨어적 구성에 대해서는 큰 비중을 두고 설명하지 않을 것이다. 소프트웨어적 관점에서 이해할 필요가 있는 하드웨어 모듈에 대해서는 설명할 것이지만 전혀 소프트웨어와는 상관없이 소프트웨어 수준에서는 완전히 추상화되어 그 존재가 가려지는 하드웨어 모듈에 대해서는 전혀 언급이 없을 것이다.
명령어 집합, 명령어 집합 상태, 동작 모드
ARM, Thumb instruction set
ARM은 ARM instruction set과 Thumb instruction set이라는 두 종류의 명령어 집합(instruction set)을 지원한다. ARM instruction set에 속하는 명령어들은 모두 32비트 명령어이다. Thumb instruction set에 속하는 명령어들은 모두 16비트 명령어이다. 따라서 동일한 C언어 소스코드로 작성된 프로그램을 ARM 명령어 집합으로 컴파일 했을 때와 Thumb 명령어 집합으로 컴파일 했을 때에 생성되는 바이너리 이미지의 크기는 이상적인 상황에서 ARM 명령어 집합으로 컴파일하는 것이 Thumb 명령어 집합으로 컴파일 하는 것 보다 정확히 두 배 커야 한다. 물론 여러가지 최적화 기법을 컴파일러가 적용하기 때문에 실제로 ARM 명령어 집합의 바이너리 이미지가 Thumb 명령어 집합의 바이너리 이미지보다 두 배 큰 경우는 거의 생기지 않는다.
Instruction Set State
ARM은 명령어 집합이 두 개이므로 해당 명령어 집합을 실행하는 프로세서의 상태도 이에 연동되어 두 개이다. ARM 명령어 집합에 해당하는 32비트 명령어를 실행하는 프로세서의 상태를 ARM 상태(ARM state)라고 하고 마찬가지로, Thumb 명령어 집합에 해당하는 16비트 명령어를 실행하는 상태를 Thumb 상태(Thumb state)라고 한다.
당연히 ARM 상태와 Thumb 상태는 프로세서가 동작하는 중간에 서로 변경 가능하다. ARM 명령어 중에 BX나 BLX를 사용해서 ARM 상태에서 Thumb 상태로 변경할 수 있다. 서로 상태를 바꾸어가며 변경이 가능할 뿐 두 명령어 집합을 섞어서 사용할 순 없다. ARM 상태에서 ARM 명령어 집합의 명령을 수행하다가 Thumb 명령어가 나오면 반드시 프로세서의 명령어 수행 상태를 변경해야 한다.
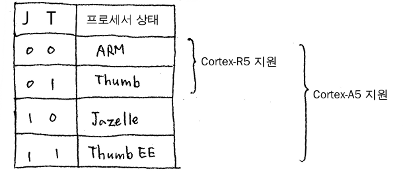
Cortex-A5에서는 추가로 두 가지 프로세서 상태가 더 존재 한다. ThumbEE 상태와 Jazelle 상태이다. ThumbEE 상태는 Thumb 명령어와는 다른 명령어로 프로그램이 실행되는 중간에 실행코드를 만들어낸다. 일종의 바이트 코드의 형태라고 보면 된다. Jazelle 상태는 1바이트 단위로 정렬되고 길이가 가변적인 Java 바이트 코드를 해석하기 위한 프로세서 동작 상태이다.
각 프로세서 상태는 CPSR의 J비트 플래그와 T비트 플래그의 조합으로 알 수 있다.

Operating Mode
명령어 집합을 실행하는 프로세서 상태와 별개로 ARM 프로세서는 동작 모드(Operation Mode)라는 것을 두고 있다. 동작 모드는 일곱 개이다.
* User 모드(USR): 일반적으로 사용하는 모드로 ARM 상태와 Thumb 상태로 모두 동작 가능하다. 운영체제가 관여한다면 사용자 프로그램은 USR 모드에서 동작시키는 것이 일반적이다.
* Fast interrupt 모드(FIQ): ARM에서 지원하는 fast interrupt 신호가 하드웨어에서 발생했을 때 소프트웨어는 FIQ 모드로 변경된다.
* Interrupt 모드(IRQ): 일반적인 interrupt 신호가 하드웨어에서 발생하면 소프트웨어는 IRQ 모드로 변경된다.
* Supervisor 모드(SVC): 운영체제 등에서 시스템 코드를 수행하기 위한 보호 모드이다. 보통 운영체제의 시스템 콜(System Call)을 실행할 때 SVC 모드에서 실행한다.
* Abort 모드(ABT): 메모리에서 데이터나 명령어를 읽어오다가 하드웨어에서 발견 가능한 문제가 생기면 소프트웨어는 ABT 모드로 변경된다.
* System 모드(SYS): 운영체제 등에서 사용자 프로세스가 특권 모드를 획득해야 할 필요가 있을 경우가 있는데, 이때 SYS 모드를 사용한다. 그래서 SYS 모드는 하드웨어가 아닌 소프트웨어에 의해서만 진입할 수 있는 모드이다.
* Undefined 모드(UND): ARM 상태 일 때 ARM 명령어 집합에 없는 명령어를 읽어오거나, Thumb 상태일 때 Thumb 명령어 집합에 없는 명령어를 읽어오게 되면 UND 모드로 진입한다. 펌웨어의 코딩을 잘 못한 경우가 아니라면 코프로세서를 사용할 때 UND 모드를 사용한다.
명령어 집합 실행 상태와 동작 모드의 관계
위 글에서 이미 별개로 존재하는 것이라고 언급했으므로 다시 쓸 필요가 있을까 싶다만, 헛갈려 하는 분이 있을 것 같아서 별도의 문단으로 다시 설명한다.
명령어 집합 실행 상태는 말 그대로 어떤 명령어 집합을 실행할 수 있는 상태인지를 나타낸다. ARM 상태에서는 ARM 명령어 집합에 해당하는 명령어를 실행할 수 있고, Thumb 상태에서는 Thumb 명령어 집합에 해당하는 명령어를 실행할 수 있다. 그리고 명령어 집합 실행 상태가 바뀐다고 동작 모드에 영향을 주진 않는다. 하지만 동작 모드가 바뀔 때는 명령어 집합 실행 상태가 바뀐다. 이것에 대해서는 이후에 다시 자세히 설명할 것이다.
레지스터
ARM 프로세서는 레지스터를 모두 37개 가지고 있다. 32비트의 범용 레지스터 31개와 32비트의 상태 레지스터 6개이다. 레지스터가 37개나 되지만 동시에 37개를 모두 사용할 수는 없다. 프로세서 상태와 동작 모드에 따라 사용할 수 있는 레지스터가 다르고 따라서 사용할 수 있는 레지스터의 개수도 다르다.
동작 모드 별로 범용 레지스터 16개와 상태 레지스터 2개를 사용할 수 있다. 그런데 동작 모드는 7개이고 범용 레지스터는 31개이다. 동작 모드 별로 범용 레지스터가 16개라면 범용 레지스터는 112개가 있어야 한다. 그리고 상태 레지스터도 각 동작 모드 별로 2개씩 14개가 있어야 하지만 ARM 프로세서에는 상태 레지스터가 모두 6개만 있다. ARM 프로세서에서 단순 계산 했을 때 필요로 하는 레지스터의 개수보다 실제로 존재하는 레지스터의 개수가 적은 이유는 레지스터를 공유하기 때문이다. 대부분의 범용 레지스터는 거의 공유하고 일부 상태 레지스터는 각 동작 모드별로 독립적으로 가지고 있다.

공유하는 레지스터를 포함해서 각 동작 모드 별로 직접 접근 가능한 레지스터로 R0-R15가 있고, 프로세서의 상태 플래그, 상태 비트, 동작 모드 비트를 가지고 있는 Current Program Status Register(CPSR)이 있다. R0부터 R12까지 레지스터는 범용(general-purpose) 레지스터로 데이터나 메모리 주소를 값으로 가질 수 있다. 그리고 R13, R14, R15는 일반적으로 아래와 같은 특수 목적으로 사용한다. 물론 펌웨어 개발자에 따라서 R13, R14, R15를 특수 목적으로 사용하지 않고 R0-R12와 같이 범용 레지스터로 사용할 수도 있지만, ARM 아키텍처에서는 R13, R14, R15에 특별한 기능을 부여하고 있으므로 어떻게 사용할 것인가에 대해서는 개발자가 잘 판단해야 한다.
* R13: 스택 포인터(Stack Pointer) - 스택 구조를 사용하는 소프트웨어에서 스택의 꼭대기(Stack Top)을 표시하기 위한 용도로 스택 포인터(SP)를 사용한다. 만약 스택을 사용하지 않는 간단한 구조의 소프트웨어를 개발한다면 R13을 범용 레지스터로 사용해도 무방하다.
* R14: 링크 레지스터(Link Register) - C언어의 함수 호출(Function Call) 등 서브 루틴 분기가 발생하는 소프트웨어에서 서브 루틴 수행이 끝난 후 돌아갈 위치(Return Address)의 저장을 위해 링크 레지스터(LR)을 사용한다. 이후에 설명할 명령어 중 BL, BLX 등 분기(Branch) 명령어는 분기 동작을 하면서 동시에 리턴 어드레스를 R14에 자동으로 저장한다. 그리고 인터럽트나 익셉션(exception)이 발생 했을 때에도 ARM 프로세서는 리턴 어드레스를 자동으로 R14에 저장한다. 따라서 R14를 범용 레지스터로 사용할 때는 분기 명령어나 인터럽트, 익셉션 등이 자동으로 입력하는 주소 값이 유실되지 않도록 주위를 기울여야 한다. 필자가 추천하는 가장 좋은 방법은 R14는 범용 레지스터로 사용하지 않고 링크 레지스터로만 사용하는 방법이다.
* R15: 프로그램 카운터(Program Counter) - 메모리에서 명령어를 읽어서 실행하는 프로세서는 현재 실행 중인 명령어의 위치를 가리키는 프로그램 카운터(PC)를 유지하고 있어야 한다. ARM은 이 프로그램 카운터로 R15를 사용한다. 명령어 한 개를 실행하고 나면 PC는 다음 명령어를 가리키기 위해 명령어 하나 크기만큼 증가해야 한다. 따라서 ARM 상태일 때는 워드(word) 단위로 명령어들이 정렬되어 있고, Thumb 상태일 때는 하프 워드(halfword) 단위로 명령어들이 정렬되어 있으므로 명령어 하나를 해석할 때마다 ARM 상태에서는 4바이트가 증가하고 Thumb 상태에서 2바이트가 증가한다.
FIQ, IRQ, SVC, ABT, UND 모드는 특권 모드이다. 특권 모드에는 CPSR의 데이터를 저장, 백업하는 용도로 Saved Program Status Register(SPSR)을 두고 있다. SPSR의 구성은 CPSR과 동일하다.
SP, LR, SPSR은 각 모드에 별도로 가지고 있다. 그리고 FIQ 모드에는 R8-R12까지 범용 레지스터도 별도로 가지고 있다. 레지스터를 공유하게 되면 동작 모드가 변했을 때 이전 동작 모드의 데이터를 백업하고 레지스터를 사용해야 한다. 왜냐하면 동작 모드의 변경은 일종의 인터럽트이기 때문에 이전 동작 모드에서의 컨텍스트 흐름을 보장해야 하기 때문이다. FIQ 모드에는 조금이라도 빠른 수행 속도를 만들어 주기 위해 R8-R12까지를 전용 범용 레지스터로 추가 배정이 되어 있어서 레지스터 백업 절차 없이 바로 사용이 가능하다.
FIQ 모드의 R8-R12 레지스터와 FIQ, SVC, ABT, IRQ, UND 각 특권 모드의 R13(SP), R14(LR), SPSR 레지스터는 동작 모드가 바뀌면 다른 동작 모드의 레지스터 값과는 상관없이 해당 동작 모드에서만 사용할 수 있는 전용 레지스터로 변경된다. 이와 같이 각 동작 모드에서 공유하지 않고 전용으로 사용하는 레지스터를 ARM에서는 뱅크드 레지스터(Banked Register)라고 부른다.
Thumb 상태에서는 R8-R15까지 높은 번호 레지스터의 사용이 제한되어 있다. R13, R14, R15는 SP, LR, PC로만 고정적으로 사용할 수 있고, R8-R12의 범용 레지스터는 몇 가지 명령어만 사용할 수 있다. 이에 대해서는 이후에 다시 설명하겠다.
프로그램 상태 레지스터(Program Status Registers)
레지스터 이름에 Program Status Register(PSR)이 들어가는 레지스터는 ARM에 두 개가 있다. CPSR과 SPSR이다. CPSR은 한 개이고 SPSR은 각 익셉션 핸들러(exception handler)마다 한 개씩 5개가 있다. 프로그램 상태 레지스터는 크게 아래 세 가지 정보를 포함하고 있다.
* ALU 계산 결과에 따른 각종 상태 정보 플래그
* 인터럽트를 활성화, 비활성화하는 제어 플래그
* 프로세서의 동작 모드를 표시하고 제어하는 플래그
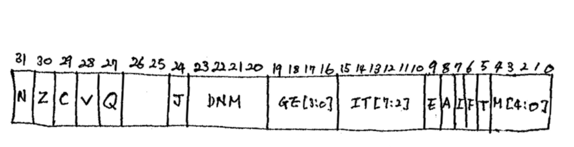
CPSR과 SPSR은 그 구조가 같다. SPSR은 CPSR의 복사본이기 때문에 당연히 구조가 같아야 한다. CPSR의 각 비트는 아래의 의미이다.
* N: 계산의 결과가 음수일 때 1로 체크된다.
* Z: 계산의 결과가 0일 때 1로 체크된다.
* C: 계산 결과에 캐리가 발생하거나, 나눗셈할 때 자리 빌림이 발생하면 1로 체크된다.
* V: 계산 결과에 오버플로우가 발생하면 1로 체크된다.
* Q: 곱셈을 계산할 때 32비트를 넘어가는 올림수에 이용한다.
* J: Cortex-A 이상 프로세서에서 Jazelle 상태로 변경시 1로 체크된다.
* DNM: Do Not Modify의 약자이다. 확장을 위해 비워두는 영역이다.
* GE: SIMD(Single Instruction Multiple Data: 하나의 명령으로 여러 개의 데이터를 동시에 처리) 명령을 사용해서 연산을 할 때 하프워드 단위로 크거나 같은지를 표시하는 비트
* IT: ITSTATE로 Thumb-2에 포함된 IT(If-then) 명령어를 위한 필드이다. 원래 Thumb 명령어는 conditional execution이 안되는데 이 명령어와 IT Field로 conditional execution을 할 수 있도록 만든 것이다.
* E: 데이터의 엔디언을 표시하는 비트
* A: 예측가능한 data abort만 발생하도록 체크, 이 비트를 끄면 예측 불가능한 asynchronous data abort의 발생을 허용한다.
* I: 이 비트가 켜져 있으면 IRQ 비활성화
* F: 이 비트가 켜져 있으면 FIQ 비활성화
* T: Thumb 상태일 때 1로 체크
* M: 모드 비트, 각 동작 모드 별로 모드 비트의 값은 아래와 같다.
* 10000: User
* 10001: FIQ
* 10010: IRQ
* 10011: Supervisor
* 10111: Abort
* 11011: Undefined
* 11111: System
익셉션(Exception)
익셉션(Exception)은 주변 장치(peripheral) 등으로부터 발생한 인터럽트 등을 처리하기위해 정상적인 프로그램 흐름이 끊기는 것을 말한다. 익셉션을 처리하기 전에 프로세서는 원래 진행되고 있던 프로그램으로 제대로 복귀할 수 있도록 중요한 작업을 미리 해 놓는다.
그 중요한 작업이란, 각 특권 모드별로 존재하는 R14(LR)에 복귀할 주소를 자동으로 저장해 놓는 작업이다. 예를 들어 USR 모드에서 프로그램이 잘 수행되고 있다가 인터럽트가 발생해서 IRQ 모드로 바뀐다면 프로세서는 자동으로 R14_irq에 현재 PC를 저장해 놓는다. 개발자는 IRQ 모드에서의 작업이 다 끝난 다음 R14_irq에 저장된 값을 이용해서 USR 모드의 원래 흐름으로 복귀할 수 있다. 다만 파이프라인 특성 때문에 각 익셉션 별로 정상 복귀를 위해 R14에 각기 다른 연산을 해 줘야 한다.

Undefined 익셉션은 익셉션이 발생한 명령어를 재실행 할지, 안할지에 따라 복귀 주소를 계산하기 위해 R14_und에서 빼야하는 크기가 결정된다. 만약 재실행을 하지 않는 다면 명령어의 크기만큼 뺀다.
익셉션이 발생했을 때 ARM 프로세서가 자동으로 수행하는 동작을 순서대로 나열하면 아래와 같다.
1. ARM 상태에서는 익셉션에 따라 PC+4 혹은 PC+8의 주소를 LR에 저장한다. Thumb 상태에서는 익셉션에 따라 PC+2, PC+4, PC+8의 주소를 LR에 저장한다.
2. CPSR을 각 익셉션에 따른 동작 모드에 할당되어 있는 SPSR에 복사한다.
3. CPSR의 프로세서 동작 모드 비트와 I, T 비트 값을 각 익셉션과 동작 모드에 맞게 변경한다. 이 동작 때문에 앞서 (2)번 단계에서 원래 프로그램 흐름(Normal Context)의 CPSR을 SPSR에 저장하는 것이다.
4. SCTLR(System Control Register)의 EE 비트 값에 따라 E비트를 설정한다.
5. SCTLR(System Control Register)의 TE 비트 값에 따라 T비트를 설정한다.
6. PC의 값을 익셉션 벡터 위치로 강제 변경한다.
익셉션의 처리를 다 끝내고 나면 위 표에 정해진 대로 LR에서 일정 오프셋을 뺀 다음 PC에 저장한다. PC에 값이 저장되면 저장된 주소로 프로그램 흐름이 변경된다.
보통 LDM 명령어에 pc를 포함하고 ^를 붙이거나 RFE 명령으로 SPSR과 PC의 이동을 동시에 처리한다. 이에 대한 내용은 이후에 자세히 설명하겠다.
인터럽트(Interrupt)
ARM 프로세서는 인터럽트 모드가 두 개이다. 하나는 IRQ 모드이고 다른 하나는 FIQ 모드이다. 인터럽트가 발생하면 앞서 익셉션 절에서 설명했던 과정이 수행되고 동작 모드가 각각 IRQ 모드와 FIQ 모드로 변경된다.
인터럽트라는 것은 필연적으로 인터럽트 지연(Latency)를 수반한다. 인터럽트 지연이란 인터럽트가 하드웨어적으로 발생해서 프로세서에 신호가 입력된 순간부터 소프트웨어적으로 인터럽트 핸들러가 수행되기 직전까지 걸리는 시간을 말한다. ARM은 기본적으로 Low Interrupt Latency(LIL) 기법을 적용하고 있고, ARM 프로세서의 종류에 따라 Vectored Interrupt Controller(VIC)를 사용하거나 Non-Maskable Fast Interrupts(NMFI)를 지원하기도 한다.
Interrupt Request
Interrupt Request는 보통 IRQ로 부른다. IRQ는 당연히 FIQ보다 우선 순위가 낮다. 따라서 FIQ로 설정된 인터럽트와 IRQ로 설정된 인터럽트가 동시에 발생하면 FIQ가 먼저 처리된다.
CPSR의 I 비트를 1로 설정하면 IRQ 익셉션이 비활성화된다. CPSR로 IRQ 익셉션이 비활성화되면 IRQ 인터럽트도 자동으로 비활성화된다. 따라서 CPSR의 I 비트 설정을 통해 인터럽트 처리를 1 단계로만 수행할 지, 중첩 인터럽트(Nested Interrupt)로 처리할 지 결정할 수 있다.
Fast Interrupt Request
Fast Interrupt Request는 FIQ로 부른다. FIQ는 IRQ와 비교해 익셉션 핸들러의 동작 시간을 약간 줄일 수 있도록 만든 인터럽트이다. FIQ가 IRQ에 비해 익셉션 핸들러의 수행이 빠른 이유는 FIQ 인터럽트와 연결되는 FIQ 동작 모드에 R8-R12 레지스터를 뱅크드 레지스터로 별도 할당해 놓고 있기 때문이다. 그래서 익셉션 핸들러에서 레지스터를 백업하고 복구하는 시간을 줄일 수 있기 때문에 익셉션 핸들러의 수행 시간이 줄어 든다. 이것을 컨텍스트 스위칭 오버헤드를 줄인다라고 말한다.
Non-Maskable Fast Interrupt(NMFI)가 없다면, IRQ와 마찬가지로 FIQ도 CPSR의 F 비트를 1로 설정해서 비활성화 할 수 있다. 당연히 IRQ와 마찬가지로 인터럽트 핸들러에 진입해서 CPSR의 F 비트를 0으로 설정하여 중첩 인터럽트를 처리할 수 있도록 만들 수 있다.
Non-maskable fast interrupt
NMFI가 활성화 되어 있으면, FIQ 인터럽트를 비활성화 시킬 수 없다. NMFI가 켜지면서 FIQ를 마스킹하는 CPSR의 F 비트를 0으로 클리어하기 때문이다. NMFI 동작을 켜는 것은 하드웨어적으로 이뤄지며, 소프트웨어는 SCTLR의 NMFI 비트를 읽어서 NMFI의 동작 유무를 알 수 있다. NMFI 비트가 0이면 FIQ를 마스킹 할 수 있다. 즉, CPSR의 F 비트를 1로 만들 수 있다. NMFI 비트가 1이면 소프트웨어는 FIQ를 끌 수 없다. NMFI가 켜져 있는 상태에서 CPSR의 F 비트가 1이 되는 경우는 오로지 FIQ나 reset 익셉션에 진입했을 경우 뿐이다.
Low interrupt latency
Low interrupt latency는 인터럽트 지연(interrupt latency)를 줄이기 위한 목적으로 ARM 프로세서의 기본 설정 기능이다. SCTLR의 21번째 FI 비트에서 항상 1로 설정되어 있다.
LIL은 인터럽트가 발생했을 때 현재 수행중인 명령어(instruction)의 실행이 끝나지 않았다 하더라도, 실행중인 명령을 취소해 버리고 인터럽트를 먼저 처리한다. 실행이 끝나지 않은 명령어는 인터럽트 핸들러의 처리가 모두 끝난 다음에 원래 프로그램 진행 흐름(normal context)으로 복귀할 때 SUBS pc, r14, #4로 LR에 저장된 PC에서 한 명령어 뒤로 다시 돌아가도록 하여 한 번 더 실행하는 것으로 수행을 완료한다. 이말은 인터럽트 처리를 위해 어떤 경우에는 같은 메모리 주소에 두 번 접근해서 명령어를 수행한다는 뜻이지만, 빠른 인터럽트 처리를 위해 줄인 시간을 인터럽트 처리 후에 보상한다고 넓은 마음으로 이해할 수 밖에 없다.
ARM에서는 메모리 타입을 Strongly Ordered로 설정할 수 있는데, Strongly Ordered로 설정된 메모리나 장치는 읽기, 쓰기 동작을 수행한 순서와 횟수를 보장해야 한다. 따라서 Strongly Ordered로 설정된 메모리나 장치는 메모리 접근을 시작한 이후부터는 그 수행이 끝날 때까지 중간에 실행을 멈출 수 없다. 그리고 AXI로 연결된 주변 장치도 이와 동일하게 동작한다. 그래서 인터럽트 지연 시간을 최소화하기 위해서는 Strongly Ordered로 설정된 메모리나 장치 그리고 AXI 인터페이스에 연결된 주변 장치에 대해서는 멀티워드(multiword) 로드/스토어(load/store) 명령을 되도록이면 사용하지 않는 것이 좋다.
Interrupt Controller
VIC(Vectored Interrupt Controller)를 포함하여 인터럽트 컨트롤러는 프로세서에 연결되는 일종의 주변장치(Peripheral)이다. 프로세서에는 인터럽트를 감지하는 핀이 IRQ 한 개, FIQ 한 개이다. 따라서 인터럽트가 발생 했다는 것만 알 수 있을 뿐, 어떤 인터럽트가 발생했는지 알려면 인터럽트 컨트롤러를 이용해야 한다. 일반적으로 인터럽트 컨트롤러는 아래와 같은 기능을 가지고 있다.
* 여러 인터럽트를 받고 어떤 인터럽트가 들어왔는지를 레지스터에 기록한다.
* 인터럽트가 발생하면 프로세서의 인터럽트 입력 핀으로 신호을 출력한다.
* 특정 인터럽트를 골라서 마스킹(masking)할 수 있다. 마스킹된 인터럽트는 발생하지 않는다.
* 여러 인터럽트들 간에 우선순위를 설정할 수 있다.
인터럽트가 발생하면 통상적으로 아래 세 단계를 소프트웨어적으로 처리해서 인터럽트 서비스 루틴으로 진입하게 된다.
1. 인터럽트 컨트롤러로부터 인터럽트 소스가 어떤 것인지를 판별한다.
2. 인터럽트 소스에 따라 실행해야 할 인터럽트 서비스 루틴을 판별한다.
3. 해당 인터럽트 소스에 마스킹을하고 인터럽트 서비스 루틴으로 진입한다. 중첩 인터럽트(nested interrupt) 처리를 한다면 마스킹을 하지 않고 인터럽트 서비스 루틴으로 진입한다.
VIC를 사용하면 위 세 작업을 하드웨어로 처리하여 인터럽트 지연 시간을 줄일 수 있다. VIC는 우선순위가 높은 인터럽트 몇 개 혹은 전부에 대해서 인터럽트 서비스 루틴의 시작 주소를 직접 레지스터에 저장하고 있다. 인터럽트가 발생하면 프로세서에서 해당 인터럽트에 맞춰 저장되어 있는 인터럽트 서비스 루틴의 시작 주소로 직접 진입힌다. ARM에서는 PL192 VIC 컨트롤러가 최신 버전의 VIC 컨트롤러이다.
Abort
인터럽트와 함께 익셉션의 또 다른 형태로 Abort가 있다. 이름에서도 알 수 있듯, Abort는 프로세서가 동작을 수행하다가 무언가 잘못되었을 때 발생하는 익셉션이다. ARM에서는 프로세서가 메모리 접근을 수행할 때 그것이 성공적으로 끝나지 못했을 때 발생한다. 그런 경우는 다음의 세 가지이다.
* MPU로 보호되는 영역에 접근 권한 없이 접근 했을 때
* AMBA 메모리 버스에서 에러를 응답했을 때
* ECC 로직에서 에러가 발견되었을 때
프로세서가 메모리에서 데이터를 읽는 경우는 두 가지이다. 명령어를 읽는 것과 데이터를 읽는 것이다. 명령어를 읽을 때 Abort가 발생하면 prefetch abort라고 부른다. 데이터를 읽을 때 Abort가 발생하면 data abort라고 부른다.
Prefetch abort나 data abort가 발생하면 ARM 프로세서는 동작모드를 ABT 모드로 변경한다. 같은 동작모드이지만, 두 abort는 다른 현상이기 때문에 핸들러는 구분되어야 한다. Prefetch abort와 data abort의 익셉션 핸들러는 각각 존재한다. 이것에 대해서는 이후 익셉션 벡터 테이블을 설명할 때 다시 다루도록 하겠다.
Prefetch abort는 명령어(instruction)을 메모리에서 읽는 과정에서 앞서 설명한 세 가지 중 한 가지가 생겼을 때. 쉽게 말해 에러가 생겼을 때 발생한다. 하지만 명령어를 읽으면서 에러가 생긴다고 바로 익셉션을 발생시키지는 않는다. 해당 명령어를 읽다가 에러가 발생하면 일단 명령어에 invalid라고 표시를 해 둔다. 그리고 그 명령어가 실행(excute) 될 순서에 왔을 때에 익셉션을 발생시킨다. 만약 파이프라인(pipeline)에서 바로 직전 명령어가 브렌치(branch) 명령어일 경우 브렌치 하고 나면 파이프라인을 비우는데, 이러면 파이프라인에 대기하고 있던 invalid 표시가 붙은 명령어는 실행되지 않는다. 이렇게 실제로 prefetch 과정에서 에러가 발생했더라도 실행이 되지 않으면 익셉션은 발생하지 않는다. Data Abort 역시 명령어에 의해서 메모리 접근이 실제로 실행될 때만 익셉션을 발생시킨다. 따라서 조건문등으로 해당 메모리 접근 명령어가 실행되지 않는다면 익셉션이 발생하지 않는다.
Undefined Instruction
Undefined Instruction 익셉션은 이름 그대로 정의되지 않은 명령어가 읽혀져서 디코드 단계에서 디코딩을 할 수 없을 때 발생한다. 이 익셉션은 오류이기도 하지만 익셉션 핸들링을 통해서 ARM에서 지원하지 않는 명령어를 확장할 수 있다. 확장하는 방법은 코프로세서같은 별도의 프로세서를 연결해서 프로세서의 메모리 영역으로 디코딩하지 못한 명령어를 넘겨서 처리 결과를 받는 방법과 익셉션 핸들러에서 명령어를 소프트웨어적으로 에뮬레이션해서 확장하는 방법이 있다.
Breakpoint instruction
디버깅을 할 때 필수적으로 사용하는 브레이크포인트(breakpoint) 기능도 일종의 익셉션으로 동작한다. 동작하는 익셉션은 prefetch abort인데, 따라서 동작 방식이 prefetch abort와 동일하다. 브레이크포인트 명령이 위치하는 주소가 프로세서에의해 실행되지 않으면 prefetch abort가 발생하지 않고 따라서 브레이크포인트도 동작하지 않는다. 이것은 당연한 동작 방식이다.
Exception Vector
익셉션이 발생했을 때 최종적으로 프로세서가 하는 동작은 PC를 익셉션 벡터 테이블의 특정 위치로 바꾸는 것이다. 그 이후는 소프트웨어 개발자의 영역으로 브렌치 명령을 한 번 더 써서 핸들러로 진입하거나 익셉션 벡터 테이블 자리에 그대로 익셉션 처리 코드를 작성할 수도 있다.
익셉션 벡터 시작 주소는 두 가지로 사용할 수 있다. CP15 레지스터의 c1 System Control Register의 V 비트를 켜면 HIVECS가 켜지는데 이렇게 되면 높은 주소의 익셉션 벡터 시작 주소를 설정할 수 있다. 익셉션 벡터의 기본 시작 주소는 0x00000000이다. HIVECS를 사용하면 0xFFFF0000이 익셉션 벡터 시작 주소가 된다.
익셉션 벡터는 각 익셉션 별로 진입하는 주소가 다르고 이들 주소는 4바이트씩 연속된 주소로 할당되어 있다. 그래서 각 익셉션의 벡터를 모아놓은 주소 영역을 익셉션 벡터 테이블이라고 한다. 익셉션 벡터 테이블 구성은 아래와 같다.

확장 기능
Jazzelle extension
Cortex-R5는 소프트웨어적으로 Jazelle 확장 명령어를 지원하고, Cortex-A5는 하드웨어적으로 Jazelle 확장 명령어를 지원한다. Jazelle 확장이란 Java 바이트 코드에 대한 처리를 프로세에서 하드웨어 가속해주는 기능이다. 그렇다고 모든 바이트 코드에서 대해서 하드웨어 확장을 지원하는 것은 아니기 때문에 일부 명령은 여전히 소프트웨어적으로 처리된다.
NEON technology
NEON 확장 기술은 미디어와 신호처리를 위한 명령어 집합을 추가 지원한다. 그래서 오디오, 비디오, 3D, 이미지, 음성 인식등의 처리를 프로세서 수준에서 빠르게 수행해 준다. 인텔 계열을 예를 들면 오래전에 나왔던 MMX 기술과 비슷한 것이라고 생각하면 된다.
Cortex-A5의 메모리 어드레싱
Cortex-A5에서 Memory Management Unit(MMU)를 사용하면, 기본적으로 소프트웨어에서 가상 주소(Virtual Address:VA)를 사용한다. MMU는 물리 주소(Physical Address:PA)로 바꿔준다. MMU에 대해서도 이후에 자세히 설명할 것이다.
참고자료
Cortex-R5 and Cortex-R5F Technical Reference Manual
Cortex-A5 Technical Reference Manual
| 첨부 | 파일 크기 |
|---|---|
| 13.78 KB | |
| 46.45 KB | |
| 21.8 KB | |
| 23.66 KB | |
| 39.32 KB |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
댓글
이 글을 쓴다고 저질러 놓고서는 거의 한 달이 넘게
이 글을 쓴다고 저질러 놓고서는 한 달이 넘게(거의 두달..-_-) 지나고서 다음편을 올리네요.
역시 이 다음편도 언제 올라올지 모르겠습니다.
이러다가 이 글 끝나기도 전에 ARMv8 나오는거 아닐런지...ㅠㅠ
하루에 한 단락 쓰기도 힘든 판이니....
(게으름 + 회사일 + 부족한 영어 실력의 복합적 문제...ㅠㅠ)
오류가 있으면 지적해 주시고,
혹시라도 뭔가 빠진것 같거나, 다루었으면 좋은 내용 있으면 댓글로 달아주시기 바랍니다.
100% 반영하겠습니다...^^
PS. 그림은 손으로 그려서 스캔한다음 김프에서 보정한건데, 아직 스캐너 사용이 익숙치 않아서 그런지 김프 실력이 딸려서 그런지.. 그림판에서 날로 그린것 처럼 보이네요..-_-; 차차 좋아질거라 믿습니다..하하하...-_-;;
----------------------
얇은 사 하이얀 고깔은 고이 접어서 나빌레라
쓸데없는 소리지만 표를 손으로 그린 게 귀여워요 :)
쓸데없는 소리지만 표를 손으로 그린 게 귀여워요 :) 학생이 잘 정리해놓은 공부 노트를 보는 것 같달까
아무튼 잘 읽었습니다.
책으로 내시면 저 표의 디테일은 살려주셨으면
책으로 내시면 저 표의 디테일은 살려주셨으면 좋겠습니다. :)
피할 수 있을때 즐겨라! http://melotopia.net/b
뭔가 더 예쁘장한 모양을 기대했는데, 이상하게
뭔가 더 예쁘장한 모양을 기대했는데,
이상하게 거칠고 허접한 모양이 되었어요..
언제 올라올지 모르지만, 다음 편에서는 조금더 미려한 그림을 기대해 주세요..ㅎㅎㅎ
----------------------
얇은 사 하이얀 고깔은 고이 접어서 나빌레라
CPSR의 IT Field는 ITSTATE로
CPSR의 IT Field는 ITSTATE로 Thumb-2에 포함된 IT(If-then) 명령어를 위한 필드입니다.
원래 Thumb 명령어는 conditional execution이 안되는데 이 명령어와 IT Field로 conditional execution을 할 수 있도록 만든것이죠.
IT명령어는 http://en.wikipedia.org/wiki/ARM_architecture#Thumb-2 요기를 참조하세요.
오오!!! 완전 감사합니다..^^; 텍스트로
오오!!! 완전 감사합니다..^^;
텍스트로 레퍼런스 메녈만 보고, 나중에 아키텍처 메녈에 나오면 추가 설명하려고 했었는데,
위키페디아도 있었군요!
다시한번 감사드립니다.
넙죽~
----------------------
얇은 사 하이얀 고깔은 고이 접어서 나빌레라
뭘요, 제가 더 감사합니다. 앞으로도 좋은 컬럼
뭘요, 제가 더 감사합니다.
앞으로도 좋은 컬럼 계속 써주시면 감사하겠습니다.
.
혹시 또 책 쓰시는 건가요...?
너무 기대되고 반갑네요
개인적으로 올리시는 글들 너무 좋아합니다
이전에 연재로 올리션던 글들도 그렇고
궁금했던 내용들을 쉽고 자세하게 알려주셔서요
-----------------------------------------------------------------------
근데 항상 보는 거지만 옆에 고아라 사진인지...
고아라 사진을 올리시는 이유는 무엇인가요?
마치 고아라가 나빌레라라는 이름으로 글을 올리고 있는 느낌이 들어서
읽을때 가슴이 콩닥콩닥 해져서
별로 안좋네요
ㅎㅎㅎ 농담입니다 죄송합니다
사진 너무 예쁘네요
지금 미친듯이 느린 속도로 연재하고 있는 이 글도
지금 미친듯이 느린 속도로 연재하고 있는 이 글도 언젠간 책을 쓰고 싶다는 생각에 쓰고 있긴 합니다만,
과연 끝가지 쓸 수 있을지 조차 잘 모르겠어요..-_-;
제 프로필 사진은 고아라가 맞습니다.
KLDP가 개편하면서 프로필 사진을 쓸 수 있게 되었을 때에..(한 10년쯤 전인가..-_-)
고아라가 좋아서 설정해 놓고..
귀찮다는 이유로 계속 안바꾸고 있는 중입니다.
그래서 구글에서 '나빌레라'를 검색하면 고아라 사진이 나온다능...-_-;;;
----------------------
얇은 사 하이얀 고깔은 고이 접어서 나빌레라
arm으로 개발을 해야하는 상황인데...가능할까요?
저희 회사가 이번에 암을 사용하여 프로젝트를 수행할 상황이 되었는데...
저는 그저 C를 좀 할 줄 아는 정도인데...
가능할까요?
지금부터 배워서?
가능하려면 어느 분야에 어느정도의 지식이 필요한건지....ㅠ.ㅠ
어디에 어떻게 참여하시는지가 중요.
플랫폼은 완성되어있고 애플리케이션 레벨에서 프로그램만 작성하는 상황이라면 큰 문제는 되지 않을 겁니다.
시행착오가 생기겠지만 대부분은 이미 누군가 해결해놨을테고 말이죠.
그 밑으로 내려갈수록 애로사항이 조금씩 더 생기겠지요. OS와 하드웨어에 더 관여할수록 말이지요.
--
댓글 달기