hunspell에서 동작하는 맞춤법 검사
글쓴이: cwryu / 작성시간: 목, 2009/03/19 - 11:37오전
현재 hunspell에서 동작하는 한국어 맞춤법 검사 사전을 만들고 있습니다.
http://code.google.com/p/spellcheck-ko/
KTS 등 다른 형태소 분석기나 맞춤법 프로그램과 다른 점은, 품질은 어떨지 몰라도 지금 이 순간에 다른 응용프로그램과 연동해 동작한다는 점입니다. 프로그램을 직접 구현하지 않고 기존의 hunspell에 맞춰 동작하는 데이터를 만들었기 때문입니다.
데비안 패키지는 제가 만들었고 지금 unstable의 NEW queue에 들어 있어서 pass되면 우분투 등 deb을 사용하는 다른 배포판에서도 가져다 사용할 수 있을 겁니다. 편의상 http://groups.google.com/group/spellcheck-ko/web/hunspell-ko_0.2.0-1_all.deb 여기에 임시로 올려 놓습니다. 설치한 hunspell 버전이 1.2.8 미만이면 충돌해서 설치되지 않고, 억지로 깔아도 동작하지도 않습니다. (여담이지만 postgreqsl이 깔려 있을 때 사전 패키지를 깔면 트리거에 따라 postgresql 사전을 빌드하는데 대체 DBMS가 맞춤법 검사를 어디에 써 먹는 지 모르겠군요.)
이 프로젝트는 개발자가 어느 순간 관심이 멀어지거나 트럭에 치이더라도 계속 돌아가도록 만들고 싶군요. 지금 데이터를 개선하는 데 관심 있으면서 파이썬 코딩 및 유니코드 처리에 익숙하신 분들은 프로젝트 페이지에 안내한 github를 통해 참여해 주세요.
File attachments:
| 첨부 | 파일 크기 |
|---|---|
| 72.91 KB |
{kind=link}
Forums:
창우씨 안녕하세요.^^
창우씨 안녕하세요.^^ 정말 멋진 프로젝트 진행하시는 것 같아 존경스럽습니다.
국립국어원에서 지난 몇년간 진행한 "세종계획"의 일환으로 만들어진 말뭉치 데이터가 있는데 이것이 적용 가능할지 궁금합니다. 일단 hunspell-ko 에서 필요한 정보는 모두 포함하고 있는 말뭉치인데요.. ( http://www.sejong.or.kr/ )
문제는 이 "세종계획" 결과물의 사용 라이센스가 비상용/연구 목적으로만 사용 가능하다고 명시가 된 점이 문제라면 문제입니다. 이 데이터를 가공하여 나온 결과물 까지 그 라이센스의 적용을 받을지는 모르겠지만요.. 3rd party 데이터 추가하시는 것에 대해 보수적인 입장이신거 같으니 이정도만 언급하고 넘어가겠습니다.
Postgresql에서 hunspell을 시용하는 이유는 아마 full text search 때문에 그런 것 같습니다. hunspell-ko 들어가면 이제 postgresql에서 한글 full text search 가 알아서 되려나요?? ㅎㅎ
저 개인적으로 hunspell-ko 에 관심이 많은 이유도 이런 형태소 분석이 가능하기 때문인데요.. (사실 어제 이런 프로젝트가 있었다는 사실을 알았습니다. 먼지분투 글을 보다가 말이지요. --;;) 지금 제가 만드는 검색엔진 프로젝트에서 유일하게 오픈소스가 아닌 부분이 형태소 분석기 였는데, 이걸로 대체할 수 있을 것 같습니다.
앗.. 기왕 하는거 프로젝트 홍보나 해야겠네요. 100% 파이썬으로 만드는 웹 검색엔진 프로젝트를 진행하고 있습니다. 많은 관심 부탁드립니다. 굽신굽신..
http://project.sparcs.org/ksearch/
관심있으시면 serialx at serialx dot net 으로 연락 부탁드립니다.~
저도 먼지분투 보고
저도 먼지분투 보고 오늘 알았습니다.
리눅스 쓸 때 정말 아쉬운 부분 중의 하나가 해소 될 기미가 보여서 정말 짜릿했습니다.
세종 성과물이 안타까운 것이, 나라에서 돈 댄 사업으로 알고 있는데, 굳이 그렇게 제한적인 라이선스와 배포 정책을 선택하도록 했는지 모르겠습니다.
MIT License 수준으로 하고 쉽게 다운 받을 수 있게 하는 것이 성과를 더 살리는 방법일 것 같은데 말입니다.
(예전에 자료 다운 받으면서 속이 터진 경험이 있어서요. 받아 보신 분들은 무슨 얘기인지 아실 것입니다.)
세종 사전 데이터의 목록 만으로도 충분히 좋은 자료가 될 수 있습니다만, 표제어(명사쪽)가 사투리들을 포함하고 있기 때문에 그리 간단하지 만은 않습니다.
물론 사전 내용에 방언이라고 표시가 되어 있던 것으로 기억하기 때문에 정말 원한다면 표준어의 목록만을 구하는 것이 어려운 일은 아닐 것입니다.
다만, 라이선스가 신경쓰이는 관계로 때문에 그냥 묵혀 두는 것이 더 속 편한 방법인 것 같다는 생각이 듭니다.
(3rd party(?) 데이터 추가에 보수적인 류창우님의 선택이 이해가 됩니다.)
여튼 멋진 프로젝트, 잘 진행되었으면 좋겠구요.
도울 수 있는 일이 있다면 도와드리렵니다.
http://hj-lee.github.io/
다 조사한
다 조사한 내용입니다. 쓸 수 있는 데이터는 인터넷 어디에도 없습니다. 세종코퍼스는 라이선스도 사용 불가능이지만 코퍼스를 가공해 봤자 hunspell에서 쓸 만한 수준의 데이터를 만드는 데 도움이 되지 않습니다.
검색 용도로는 (특히 인터넷 검색으로는) 사실 도움이 안 될 것 같네요. 맞는 단어가 무엇인지 판단하는 맞춤법 검사 데이터와 검색에서 어근을 찾는 용도의 데이터는 성격이 다릅니다.
그렇긴 하지만,
그렇긴 하지만, hunspell 에 stem 추출 기능이 있기도 하고, 요즘같이 띄어쓰기나 맞춤법 틀리는 사람이 한둘이 아닌 시대에는 오히려 맞춤법 교정 candidate 도 같이 indexing 해버리면 접근성이 더 좋아질지도 모른다는 생각조차 한답니다. ㅎㅎ
그리고 결정적으로, 지금 당장 쓸 수 있는 오픈소스 한글 분석기라는게 가장 큰 장점이지요.
프로젝트 내에서는 pluggable 한 인터페이스로 추가될 것 같습니다. ^^;
ps. 세종 코퍼스에서 POS tagging 된 녀석들도 쓸모가 없었나요?
어떤 데이터가
어떤 데이터가 필요한지 몰라서 질문드립니다.
국어사전에 나오는 표제어 같은 것은 도움이 안 되나요...
저작권 없는 표제어를 수만개 가지고 있거든요.
그 데이터도 결국
그 데이터도 결국 외부의 다른 데이터에서 온 것이죠. 어떤 근거로 저작권이 없다고 믿고 계신지 모르겠습니다만 흔히 알려진 돌아다니는 데이터는 저작권이 있고 심지어 불법 추출된 데이터도 있습니다. 결국 저작권 논란이 됩니다. 이런 데이터는 받아들이지 않겠다는 겁니다.
이게 저작권을 주장할 수가 있냐 없냐 여러가지 얘기가 끝도 없이 있을 수 있는데 그런 논란을 아예 일으키고 싶지 않습니다.
인용: 국어사전에
cwryu님 무슨 뜻인지 알겠습니다.
제가...맞춤법 원리를 잘 몰라서 국어사전의 표제어를 예를 들었습니다.
소스를 보긴 봤는데...Python이라 이해가 안 되더군요.
(창피합니다만, 제가 Python을 모릅니다.)
대강 어떤 형식의 데이터가 필요한지 알려주시면,,
직접 만들 궁리를 해보던가(예를 들면 bnf로..), 저작권이 소멸된 한국문학에서 추출해보던가...
'고려'만이라도 해보려고 그럽니다.
(실제로, 할지 안할지는 잘모르고요, 가능한가 검토라도 해보려고요.)
PS, 그리고 수만개 가지고 있는 표제어는 bot 이 수집하듯이 여기저기 인터넷 문서를 가공한 것입니다. 이 자료 안쓰겠습니다.
칼퀴라고
칼퀴라고 있었군요....
http://galkwi.appspot.com/
전...칼퀴라고 해서...무슨..게임 사이트인가..했는데..ㅋㅋ
알려달라고 귀찮게 해서 죄송;
데이터 형식 확인했습니다.
인용:"갈퀴"는 사전
- cwryu님의 설명 중..
갈퀴에 대한 더 자세한 내용은 다음 문서를 참조하세요.
http://groups.google.com/group/spellcheck-ko/web/%EC%82%AC%EC%A0%84%20%ED%98%91%EC%97%85%20%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4
자진삭제합니다.
자진삭제합니다.
stardict 라는 사전
stardict 라는 사전 프로그램에서 사용하는 사전 데이터를 보면, 한국어 사전이 몇 개 있습니다. 이 사전들의 라이센스를 보면 "Free to use" 라는 것도 있고, "GPL" 이라는 것도 있지요. 그런데 과연 그 데이터가 정말 GPL 데이터일까요?
제가 알기로는 가장 많이 쓰이는 "quick_english-korean" 사전 데이터의 경우, 모 사의 PDA 용 사전 데이터 파일을 변환한 것입니다. 이것이 저작권 개념없이 떠돌다가, 어느날 누가 "공개된 자료"라고 생각하고 GPL 이라고 붙여놓은 것이겠지요. 공개된 자료와 GPL 도 엄연히 다른 것인데..
여튼 이런 식으로 "자유롭게 사용할 수 있다." 라고 여겨지는 많은 자료들이 실상은 그렇지 않은 경우가 많습니다. 그래서 cwryu 님은 처음부터 그런 것을 상당히 경계하시고 "완전히 스크래치부터 시작하자." 라고 하셨습니다. 그래서 도움이 되었는지 어땠는지는 몰라도 한글 위키백과 8만 페이지를 뒤져서 최초 기초 데이터를 만들었습니다.
여러 가지로 같이 고민하고, 좋은 의견을 주시는 것은 감사하고 앞으로도 지속적으로 필요한 부분이지만, 저작권에 관해서는 "100% 확신할 수 없는 것은" 철저히 배제하고 간다라는 암묵적(?) 룰이 있음을 이해해 주셨으면 합니다. :)
음 위키백과 단어
음 위키백과 단어 목록은 hunspell 개발자가 제안한 방법으로 잘 되나 실험을 했을 뿐이고 지금 있는 데이터는 다 수동 입력입니다. 사전 용량은 크고 속도는 느린데 성능은 떨어져서 완전 통계적인 접근은 교착어에 별 도움이 되지 않는다는 것만 증명했습니다.
좋은 프로그램
좋은 프로그램 감사합니다. 하루 빨리 자유롭게 사용할 수 있는 우리나라가 되었으면 합니다.
--------------------------------------------------------
남이 가르쳐주는 것만 받아들이는 것이 아니라, 스스로 만들고, 고쳐가는 사람을 '해커'라고 부른다.
그리고 자신이 쌓아온 노하우를 거리낌없이 나눌 줄 아는 사람을 '진정한' 해커라고 한다.
-Rob Flickenger 'Linux server hacks'
http://heuno
-----------------------------------------------------
남이 가르쳐주는 것만 받아들이는 것이 아니라, 스스로 만들고, 고쳐가는 사람을 '해커'라고 부른다.
그리고 자신이 쌓아온 노하우를 거리낌없이 나눌 줄 아는 사람을 '진정한' 해커라고 한다.
-Rob Flickenger 'Linux server hacks'
DEBIAN TESTING, KDE...
debpolaris.blogspot.kr
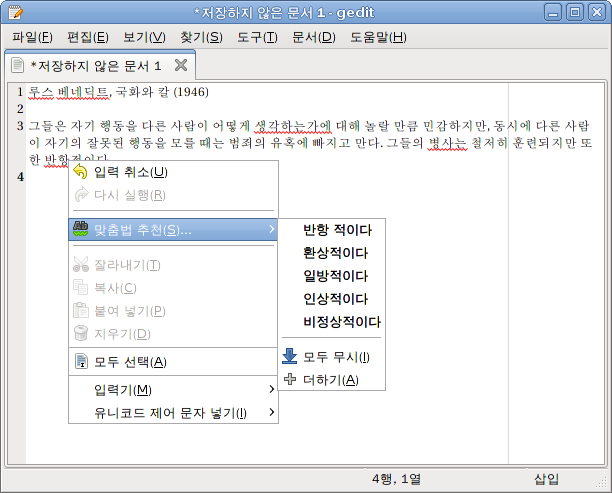
gedit도 hunspell로 동작하나요?
소스의 utils에 있는 파이썬 프로그램들을 이용하여
맞춤법 검사가 되는 것은 커멘드라인에서 확인해 보았는데...
$ cat sample.txt | hunspell-dict-ko-0.2.2/utils/syl2jamo.py | hunspell -d ko_KR | hunspell-dict-ko-0.2.2/utils/jamo2syl.py
gedit에서는 전부 빨간줄이 생기고 동작하지 않는거 같은데...
짤방처럼 동작하게 하려면 어떻게 해야 할까요?
우분투 9.04에서 해보았습니다.
위에서 창우님이
위에서 창우님이 말씀하셨듯이 hunspell 과 libhunspell 이 모두 1.2.8 이상이 되지 않으면 정확하게 동작하지 않습니다.
ubuntu-ko ppa 를 이용하시면 업그레이드를 하실 수 있습니다.
https://launchpad.net/~ubuntu-ko/+archive/ppa
감사합니다.
확인해 보니 우분투 9.04의 hunspell이 1.2.6이었군요...
따끈따끈한 우분투라 버젼이 낮으리라고는 미처 생각지 못했습니다.
굉장히 잘 동작합니다. ^^
멋지군요.
테슷흐라고 잘 못
테슷흐라고 잘 못 쓴걸 테스트 테라스 텍사스까지 찾아내는걸 보면 자소를 모두 분해/재조합하여 찾아는낸 방식인가보네요 @@~
온갖 참된 삶은 만남이다 --Martin Buber
정말 멋진 일입니다.
오랜 숙원인 공개 맞춤법검사기!!
정말 감사드리고 계속 응원하고 있습니다.
위에서 이미 말씀하신대로 그놈환경에서 맞춤법 검사되는 모든 어플에 적용되며,
이를 사용한 외부 프로그램도 쉽게 만들수 있습니다.
다음은 pyenchant를 사용한 예제.
>>> import enchant >>> d = enchant.Dict("ko_KR") >>> d.check("팩휘지") False >>> d.check("패키지") True아! 너무나 멋진 일입니다. +_+
......
(오프토픽; 동문서답..)
파이썬 만세~!!! ==3
--
이 아이디는 이제 쓰이지 않습니다.
DOS용 세종계획 말뭉치 프로그램 ▲ 문서표준형
DOS용 세종계획 말뭉치 프로그램
▲ 문서표준형 점검 프로그램
▲ 자소․음절 빈도 조사 프로그램
▲ 대규모 코퍼스 대상의 어절 빈도 조사 프로그램
▲ 한자․한자어 빈도 조사 프로그램
▲ <글> 내부코드 자료 순차배열 프로그램
▲ 교정목록에 의한 말뭉치 자동교정 프로그램
▲ 말뭉치 계량 및 분포 측정 프로그램
각 응용 프로그램마다의 역할 및 기능은
H2B.EXE HWP 파일을 <글>의 내부코드 파일(H2B)로 변환.
H2K.EXE HWP 파일과 KSSM 코드 파일의 상호 변환.
WDcount.EXE HWP, H2B, 텍스트 파일들의 어절 수 측정.
WDC_TEI.EXE 21세기 세종계획 표준형 문서의 어절 수 측정.
CWORD.EXE 어절, 한자, 한자어 빈도 조사.
Jamo.EXE 한글 음절 사용 빈도 및 자소별 전이빈도 조사.
Hsort_H.EXE HWP, H2B 파일 자료의 순차배열 및 KSSM 코드 출력.
Correct.EXE 교정 어절 목록에 의한 대량의 텍스트 자동 교정.
Chk_TEI.EXE TEI 문서 형태(헤더와 마크업)의 기본 규칙 오류 검사.
http://cafe366.daum.net/_c21_/bbs_search_read?grpid=1M5Jn&fldid=WSjL&contentval=00009zzzzzzzzzzzzzzzzzzzzzzzzz&nenc=&fenc=&q=&nil_profile=cafetop&nil_menu=sch_updw
재벌 2세가 재벌이 될 확률과
금메달리스트 2세가 금메달을 딸 확률이 비슷해지도록
자유오픈소스 대안화폐를 씁시다.
아이디의 아이디어 무한도전
http://blog.aaidee.com
귀태닷컴
http://www.gwitae.com