제가 알고 있는 바로는 은자모* 류의 글꼴들은 이외 다른 은글꼴들과는 조합방법을 조금 달리해서 그벌수를 크게 줄인 점 외에는 특별히 다른 점이 없는 글꼴로 알고 있습니다. 물론 제가 잘못 알고 있을 수도 있습니다. 특별히 은자모바탕 글꼴에만 작업하신 이유가 있는건가요? 제가 알기로는 이쪽 영역 자모 글꼴들은 자형만 채워넣어서 되는 것이 아니라, 몇가지 추가 작업(GSUB 테이블 같은)을 글꼴에 해 주어야 하고, 또 그런 작업이 된 글꼴이라도 응용프로그램 및 관련 라이브러리에서 이에 대한 지원이 되어 있어야 제대로 사용할 수 있는 걸로 알고 있습니다.
혹시 이 글꼴을 실제로 어떤 작업에 사용하고 계신다면, 어떤 식으로 사용하고있는지 소개해 주신다면 고맙겠습니다. 이런 경우는 일반적인 상황이 아니라서 대부분의 사람들에게는 크게 와닿는 것이 없을 거 같습니다.
첫가끝 낱자의 정의가 글꼴 자형의 매트릭 정보를 조정해서 초성 코드 뒤에 중성, 종성 코드와 왔을때, 앞의 초성 자형에 중성, 종성 자형이 겹쳐서 표시되게 하여 결과적으로 하나의 조합된 한글글자처럼 보이게 하는 것을 말하나는가 보죠. 전 글꼴을 이렇게 설계한게 일종의 트릭이라고 생각하고 있었는데 첫가끝이라는 용어를 쓰는것 자체가 이런식의 방법을 쓴다는 말을 내포하는가보죠?
은자모바탕글꼴에서 유니코드 한글자모 영역을 표현한 자형은 그대로 은바탕 글꼴에도 적용되어 있습니다. 한번 확인해 보세요.
제 생각에는 어차피 은글꼴에서도 유니코드에 추가된 변화를 수용해야 할 것이기 때문에 이왕에 하는 작업이라면 원글꼴에 포함되는 것이, 리눅스 배포판에 적용등 여러모로 좋을 것이라고 생각해서 그렇 말씀을 드린 것입니다. 자칫 지금 하신 작업이 단발성 작업으로 끝나버릴 수 있으니까요.
이런 폰트가 있으면 사실 한글은 기본자모만 유니코드에 배정해도 충분합니다. 이를테면 ㄱㅅ 겹자모를 표현할 때 사용자는 단지 ㄱ과 ㅅ을 붙여 입력하기만 하면 됩니다. 이 경우 오픈타입을 지원하는 프로그램과 폰트가 주변의 자모를 파악하여 알아서 적절한 모양의 ㄱㅅ 자모로 전환시켜(glyph substitution: GSUB) 출력하게 됩니다.
제가 TeX 쪽에 관여하고 있어 잠시 언급하자면... 사실 TeX 계에서는 오픈타입 테이블을 지원하는 엔진들이 이미 나와있습니다. XeTeX이나 luaTeX 따위가 그런 것들입니다. 어플리케이션 쪽에서의 지원은 이미 되고 있는 셈이죠. 그런데 이것을 써먹을 수 있는 한글 오픈타입 폰트가 없습니다. 서양애들이 이거 이용해서 다양하게 원하는 모양의 문서를 만들어내는 걸 보면서 그저 부러워할 수밖에 없습니다. (예전에 신정식님과 박원규님이 테스트용으로 만들었던 UnBatangOdal 폰트는 뭐가 문제인지 작동하지 않더군요. 맥에서 이 폰트를 테스트해보려고 설치 시도하면 폰트에 에러가 있다면서 설치를 거부합니다.)
무엇보다 가독성 있는 출력물을 위해서라도 GSUB을 지원하는 폰트가 반드시 필요합니다. 빨래줄 글꼴을 출판에 사용할 수는 없겠지요.
유니코드 빈 자리에 새로운 글자 추가하는 것도 그리 나쁜 일은 아니지만 제대로 된 한글 폰트 쪽으로 노력하는 것이 더 실용적이라고 봅니다. 2008년에는 이런 기능을 제공하는 한글 오픈타입 폰트를 만나봤으면 하는 바랍입니다.
[ 수정 ] 잘못된 정보를 제공한 점 사과드립니다. 신정식·박원규님의 UnBatangOdal은 XeTeX 상에서 완벽히 의도한대로 작동함을 확인하였습니다.
see http://nomos.tistory.com/39
GTK2에서는 적어도 한글처리를 위해서 GSUB를 쓰지 않는 거 같습니다. 현대한글 첫가끝 코드를 한글음절영역의 자형으로 변환해서 보여주기는 합니다만, 이건 글꼴 정보를 사용하는 것이 아니라 Pango에서 내부적으로 처리하는 거 같습니다. 아무래도 제대로 GSUB 테이블을 가지고 있는 한글글꼴이 전무하다 보니 이렇게만 처리하는 거 같습니다.
TeX말고 간단히 GSUB를 테스트할 게 없는가 찾아보다, 박원규님의 글[1] 을 발견했습니다. 그 글과 김도현 님의 글을 참고해서 테스트한 결과를 올려봅니다.
$ cat fk050000000000.txt | ftstrtto -u -s hang -l KOR 24 UnBatangOdal_0428.ttf -
$ cat fk050000000000.txt | ftstrtto -u -s hang -l KOR -f ccmp 24 UnBatangOdal_0428.ttf -
$ cat fk050000000000.txt | ftstrtto -u -s hang -l KOR -f ccmp -f ljmo -f vjmo -f tjmo 24 UnBatangOdal_0428.ttf -
세번째 그림이 김도현님께서 테스트한 것과는 약간 다른데, 이건 좀 살펴봐야 할 거 같습니다.
ftstrtto는 데비안에서는 freetype1-tools 안에 포함되어 있습니다.
산업자원부 기술표준원 홈페이지 공지사항을 보니까, "2007년 11월 27일에 열렸던 한글코드처리 국가표준(KS) 공청회 개최"에 관한 소식이 공지사항에 나와 있더군요. 첨부된 파일을 열어보니 아래와 같은 내용이 있어서, 국가표준종합정보센터 홈페이지에서 해당 pdf파일을 찾아보았는데, 찾을 수 없었습니다. 혹시 에멜무지로님께서 이 자료를 가지고 있으신가요?
Quote:
※국가표준종합정보센터 홈페이지(www.standard.go.kr)의 “국가표준/한국산업규격(KS)/KS예고고시” 페이지에서 ‘고시번호 2007-0834’을 찾아 보시면 KS X 1026-1의 pdf 파일을 받아보실 수 있습니다.
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
지금 그 규격을 봤는데, '첫소리 글자와 끝소리 글자만의 조합은 허용하지 않는다'고 적혀 있군요.
그러면 초성이 빠진 미완성 한글은 허용되고, 중성이 빠진 미완성 한글은 허용되지 않겠군요. 좀 어이가 없습니다.
또한 ㄱ이나 ㅏ 같은 낱자를 단독으로 표시할 수는 없고, 반드시 앞이나 뒤에 채움 문자가 있어야 합니다.
(초성 ㄱ은 1100으로 끝나는 게 아니라 1100 1160, ㅏ는 1161로 끝나는 게 아니라 115F 1161, 종성 ㄱ은 11A8로 끝나는 게 아니라 1100 1160 11A8)
조합형 한글 글자 마디를 표현할 때 다음 사항을 주의해야 합니다.
1. 낱자 여러 개를 써서 겹낱자를 표현하면 안 됩니다.
예: ㄱㄱ (1100 1100, 틀림) → ㄲ (1101, 맞음)
2. 완성형 한글 글자 마디와 조합 한글 낱자를 다시 조합해 한글 글자 마디를 표현하면 안 됩니다.
예: 가ㅿ (AC00 11EB, 틀림) → ㄱㅏㅿ (1100 1161 11EB, 맞음)
3. 현대 한글은 반드시 완성형 한글 글자 마디로 표기해야 합니다.
예: ㄱㅏ (1100 1161, 틀림) → 가 (AC00, 맞음)
방점은 단독으로 표현할 수 없고, 반드시 한글 글자 마디 뒤에 와야 합니다. (거성 302E, 상성 302F) 방점 둘을 동시에 써서는 안 되고, 한번에 하나만 나타나야 합니다.
그런데 방점은 UCS에서 합성 기호(combining mark)로 쓰이기 때문에 글자 마디를 처리할 때에는 방점을 직접적으로 포함하지 않고 별도로 처리합니다.
바뀐 한글 낱자의 순서와 이름: 이 부분 굉장히 중요합니다.http://std.dkuug.dk/jtc1/sc2/wg2/docs/n3242.pdf 이 문서에 나와 있지 않아서 저도 몰랐군요.
11EC ᇬ: ㅇㄱ → ㆁㄱ
11ED ᇭ: ㅇㄱㄱ → ㆁㄱㄱ
11EE ᇮ: ㅇㅇ → ㆁㆁ
11EF ᇯ: ㅇㅋ → ㆁㅋ
이는 ㅇ(이응)으로 시작하는 잘못된 옛한글 낱자의 이름을 ㆁ(옛이응)으로 바로잡은 것으로서, 이 네 낱자는 ㅇ에 속하는 게 아니라 ㆁ에 속하는 걸로 구현하고 처리해야 합니다. 따라서 한글 글꼴을 만들 때에는 글꼴 모양을 ㆁ으로 만들어야 하며, 정렬을 할 때도 ㆁ 뒤쪽으로 순서가 지정돼야 합니다.
KS규격은 지적재산권 문제가 걸려 있기 때문에, 무료로 배포를 할 수 없어, 판매나 열람하는 형식으로 제공한다고 하였습니다. 열람하는 과정에서 인쇄나 복제가 불가능하고 열람만 가능하도록 서비스를 제공하려고 하였는데, 리눅스나 맥에서 이런 기능을 제공하는 업체가 없었기 때문에 윈도우에서 밖에 제공할 수 밖에 없었다고 하더라고요.
그리고 파이어폭스에서 홈페이지 회원가입 문제는 홈페이지 관리 업체에 문의해서 해결하겠다는 답변을 받았습니다.
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
홈페이지에 가입하려고 하니까, nProject가 설치되면서 블루스크린이 뜨더군요. 아무래도 새나루입력기와 충돌이 일어나는 것 같아서, 윈도우 기본 IME로 바꾸었더니 문제 없이 진행되었습니다. KS규격검색에서 KSX1026-1를 검색해서 해당 자료는 찾았는데, 이런 경고문이 있네요.
Quote:
※ 본 사이트에서는 KS규격 내용의 열람만 가능하며, 인쇄나 파일복사는 한국표준협회를 통하여 규격을
구입하셔야만 합니다.
※ 공공목적이 아닌 영리를 목적으로 하는 경우에는 KS규격 무료열람 서비스를 제공할 수 없음을 알려드립니다.
파일 열람했더니, ActiveX가 설치 되면서 브라우져내에서 열람이되더라고요. 국가표준종합정보센터는 아무래도 국가 표준을 보급하는 목적보다는, 규격 판매를 위한 목적에 적합하도록 만들어 졌다는 느낌을 받았습니다. 불편하게 ActiveX로 보지말고 사서봐라는 거죠 -_-
어쨌거나, 문서의 내용을 요악하자면, 옛한글은 한글 자모 영역으로만 사용해서 나타내야하며, (초성낱자)(중성낱자)(종성낱자)(방점)을 각각 하나의 코드만을 사용하여 표현한 형태만을 허용하며, (종성낱자)와 (방점)은 없어도 되지만, (초성낱자)와 (중성낱자)가 없을 경우에는 항상 (초성채움문자)와 (중성채움문자)로 빈곳을 채워야합니다.
따라서, 다음과 같은 조합은 허용되지 않으며, 프로그램 내부적으로 올바른 표현으로 수정하여 출력해야 합니다.
초성과, 종성만 있는 글자:
(초성낱자)(중성채움)(종성낱자) -> 아마도 (초성낱자)(중성채움)(초성채움)(종성낱자)으로 수정되어 출력될 것 같은데, 이러한 조합 자체를 금지합니다.
낱자를 단독으로 쓰는 경우:
(초성낱자) -> (초성낱자)(중성채움)이 올바른 표현이고, 이런식으로 수정되어 출력됩니다.
(중성낱자) -> (초성채움)(중성낱자)이 올바른 표현이고, 이런식으로 수정되어 출력됩니다.
(종성낱자) -> (초성채움)(중성채움)(종성낱자)이 올바른 표현이고, 이런식으로 수정되어 출력됩니다.
모든 완성형 한글, 호환자모, 반각자모, 원문자, 괄호문자 등 과의 조합:
(완성형 한글)(종성낱자) -> (완성형 한글)(초성채움)(중성채움)(종성낱자)형태로 즉 처음 의도와 다른 형태로 수정되어 출력되는데, 이런 글자는 (초성낱자)(중성낱자)(종성낱자)형태로 표현해야 합니다. 이 부분은 지금의 정규화 알고리즘이 잘못되어 있기 때문에 유니코드 5.1 정규화 알고리즘에서 수정되겠지요.
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
답이 왔습니다. 아래는 답장 내용을 추린 것입니다. 원 답장은 위 URL을 누르시면 볼 수 있습니다.
Quote:
KS X 1026-1은 “한양 PUA 옛한글”이라고 부르시는 비표준 코드와는 연관 관계가 없으며, 따라서 공식적인 매핑 테이블 같은 것도 없음을 알려드립니다. 다만, 민원인의 궁금증 해소를 위하여 문자 코드 전문 위원회의 검토 견해를 아래와 같이 전달해 드리오니 참고하시기 바랍니다.
<문의에 따른 검토 의견>
1. U+11EC~U+11EF가 모두 ㅇ으로 시작하는 것이 아니라 ㆁ으로 시작하도록 수정되었던데, 왜 그렇게 정정되었습니까? 기존 ㅇ으로 시작하는 것이 잘못되었다는 확실한 이유가 있습니까?
→ 답변: 꼭지가 없는 이응은 초성의 빈 자리를 채우기 위해서 사용되는 것이고, 꼭지가 있는 이응(/ŋ/, ㆁ, 옛이응)은 음가가 있는 이응입니다. 따라서 질문하신 자리의 이응은 모두 옛이응으로 되어 있어야 합니다.
(제가 저렇게 질문하고 나서 ㅇ은 소리가 없으니 소리가 있는 ㆁ이 맞을 거라고 개인적으로 추측을 했었는데, 딱 제 추측이 맞아떨어지는군요.)
2. 중성과 종성만의 결합은 허용하지만, 초성과 종성만의 결합은 허용하지 않는 이유가 무엇입니까?
→ 답변: 초성과 종성만의 결합은 소리로써 표현할 수 없습니다. 초성과 종성이 결합되어야 하는 특별한 이유가 있을까요? 현재 맞춤법 규정에 말씀하신 것 같은 조합은 없으며, 오로지 컴퓨터 상에서만 만들어지는 글자입니다.
3. 한양 PUA의 U+F8D9~U+F8DF, U+F8E1~U+F8E5는 다음과 같습니다.
ㅇㄱ, ㅇㄱㄱ, ㅇㅁ, ㅇㅅ, ㅇㅇ, ㅇㅋ, ㅇㅎ
ㆁㄱ, ㆁㅅ, ㆁㅿ, ㆁㅋ, ㆁㅎ
3. 1. 한양 PUA의 ㅇㄱ(U+F8D9), ㆁㄱ(U+F8E1) 모두 유니코드 5.1의 U+11EC(ㆁㄱ)에 대응됩니까?
3. 2. 한양 PUA의 ㅇㄱㄱ(U+F8DA)은 유니코드 5.1의 U+11ED(ㆁㄱㄱ)에 대응됩니까?
3. 3. 한양 PUA의 ㅇㅁ(U+F8DB)은 유니코드 5.1의 ㆁㅁ(U+D7F5)에 대응됩니까?
3. 4. 한양 PUA의 ㅇㅅ(U+F8DC), ㆁㅅ(U+F8E2) 모두 U+11F1(ᇱ)에 대응됩니까?
3. 5. 한양 PUA의 ㅇㅇ(U+F8DD)은 유니코드 5.1의 U+11EE(ㆁㆁ)에 대응됩니까?
3. 6. 한양 PUA의 ㅇㅋ(U+F8DE), ㆁㅋ(U+F8E4) 모두 유니코드 5.1의 U+11EF(ㆁㅋ)에 대응됩니까?
3. 7. 한양 PUA의 ㅇㅎ(U+F8DF), ㆁㅎ(U+F8E5) 모두 유니코드 5.1의 ㆁㅎ(U+D7F6)에 대응됩니까?
→ 답변: 3. 1부터 3. 7에 대한 대답은 모두 '그렇습니다.'입니다.
<문의에 따른 검토의견>
1. 미완성 음절 중에서, 초성이 없으며, 중성과 종성만 있는 음절은 허용하면서, 초성과 종성만 있는 음절을
허용하지 않는 이유는 무엇입니까?
답변 : 초성과 종성만의 결합은 소리로서 표현 할 수 없습니다. 현재 맞춤법 규정에 말씀하신 것 같은 조합은
없으며, 오로지 컴퓨터상에서만 만들어지는 글자입니다.
1.1 기존의 초성과 종성만 있는 미완성 음절은 어떻게 수정하여야 합니까?
답변 : 그러한 글자가 존재한다면 출전과 용도를 먼저 밝혀 주셨으면 감사하겠습니다. 널리 범용으로 사용되
지 않으며, 존재 근거가 없는 모든 글자를 표준화 하는 것은 현실상으로 어려운 실정입니다. 다만 민원인께
서 제안하신 글자가 사용되고 있다면 근거 자료를 전달해주시면 문자코드 전문위원회, 국립국어원 등 관련
기관들과 검토해 보겠습니다.
2. 한글 자모 영역에 존재하지 않는 조합의 자모는 어떻게 표현해야 합니까?
답변 : 그런 자모는 국립국어원과, 문자코드 전문위원회와 검토를 거쳐, ISO에 제출하여 글자 추가를 승인
받아서 사용하여야 합니다. 문헌에 자주 나타나는 글자의 경우 글자의 종류와 나타난 문헌들의 종류, 사용된
시기 등의 자료를 준비하여 문자코드 전문위원회에 제출하여 주십시오.
3. 방점을 단독으로 표현하고 싶을 경우에는 어떻게 표현해야 합니까?
답변 : “초성채움(U+115F) 중성채움(U+1160) 방점”의 순으로 사용하시면 되겠습니다.
4. 옛한글이 입력 가능한 표준 자판을 만들 계획은 없습니까?
답변 : 먼저 옛한글 입력기(표준자판)는 문자코드 전문위원회의 업무영역이 아님을 알려드립니다. 이에 본 사
항에 대해서 아직까지 논의된바 없으며 향후 필요에 따라 검토 할수도 있음을 알려드리는 바입니다.
다시한번 KS에 대한 관심에 감사드리며 추가 문의사항 있으시면 아래에 연락처로 연락주십시요
* 담당자 : 배진석, 연락처 : 02-509-7264, e-mail : jsbae@kats.go.kr
추가 문의사항있으시면 전화 또는 이메일로 연락하시기 바랍니다.
몇가지 빠진 질문이 있어서, E-mail로 추가 질문 하였습니다.
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
옛한글이 실제로 사용 되기 위해서는 코드를 확정하고 글꼴을 만드는 것도 중요하지만, 그것은 전문가들이 해야할 일이고, 일반 사용자에게는 얼마나 편리하게 옛한글을 입력할 수 있는가가 중요하다고 생각합니다. 그러니까 자판을 어떻게 만들고, 어떤 식으로 입력하는가가 중요한 것이죠.
3벌식은 자판은 지금도 옛 한글 자판이 있긴 하지만, 기존 글쇠를 없애고 옛자모를 넣어야 하기 때문에, 기존의 현대 한글에 최적화된 자판과 호환이 되지 않는 어려움이 있습니다. 2벌식의 경우에는 Shift키로 입력하는 글쇠에 빈 자리가 있기 때문에, 그곳에 옛한글을 배치하면 되니, 기존 자판과의 호환성에는 문제가 없겠지만, 받침과 첫소리를 구분하여 처리하는데 새로운 방법이 필요할 것입니다.
하지만 지금 KS표준은 2벌식 밖에 없으니, 옛한글 활동을 추진하는 산업자원부 기술표준원에서는 2벌식 자판을 기준으로 만들지 않을까 생각합니다.
자판을 만든 이후에는 입력기를 보급하는 것이 중요할 것인데, 이것은 어떻게 진행 될까요? 설마 익스플로러에서만 사용할 수 있는 Active X 입력기를 만들어 내진 않겠죠...
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
옛한글 정보화를 문자코드연구센터라는 곳에서 하고 있는 것 같더군요. 문자코드연구센터 소식지를 보시면 제18호와 제19호에 옛한글 정보화에 관한 소식이 실려 있으니, 관심 있으시면 읽어보시기 바랍니다. 옛한글에 관한 질문은 기술표준원보다는 여기에 직접 물어보는 것이 어떨까요?
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
옛한글 글꼴이라고 해서 현대 한글을 지원하지 않는 건 아닙니다. 옛한글만 지원하는 글꼴이 아니라 옛한글도 지원하는 글꼴이죠.
기술적인 문제는 어느 정도 노하우가 쌓여 있는 것 같습니다. UnBatangOdal만 봐도 그렇죠. 새로 조합규칙을 확장하고, 자형을 예쁘게 그려넣는 과정이 계속되어야 하는데, 그렇지 못했죠. 메일링 리스트의 여러글을 읽어 보니 2000~2004년 경에 상당히 활발히 논의되었더군요. 시간이 흘러 다들 생업에 바쁘시다 보니 그렇게 된거 같습니다.
좀 다른 이야기로,,,
은글꼴은 몇몇 문제가 해결이 되지 않아 페도라 코어에 아직 포함되지 않은 걸로 알고 있는데, 리눅스용 대표글꼴로 밀려면 차라리 백묵 글꼴을 개선하는 것이 나을 듯 합니다. 이 경우 그냥 버전업되는 것으로 적용되어질 테니까요.
수고하셨습니다
수고하셨습니다 :)
제가 알고 있는 바로는 은자모* 류의 글꼴들은 이외 다른 은글꼴들과는 조합방법을 조금 달리해서 그벌수를 크게 줄인 점 외에는 특별히 다른 점이 없는 글꼴로 알고 있습니다. 물론 제가 잘못 알고 있을 수도 있습니다. 특별히 은자모바탕 글꼴에만 작업하신 이유가 있는건가요? 제가 알기로는 이쪽 영역 자모 글꼴들은 자형만 채워넣어서 되는 것이 아니라, 몇가지 추가 작업(GSUB 테이블 같은)을 글꼴에 해 주어야 하고, 또 그런 작업이 된 글꼴이라도 응용프로그램 및 관련 라이브러리에서 이에 대한 지원이 되어 있어야 제대로 사용할 수 있는 걸로 알고 있습니다.
혹시 이 글꼴을 실제로 어떤 작업에 사용하고 계신다면, 어떤 식으로 사용하고있는지 소개해 주신다면 고맙겠습니다. 이런 경우는 일반적인 상황이 아니라서 대부분의 사람들에게는 크게 와닿는 것이 없을 거 같습니다.
또 별도로 ~Ex 글꼴보다는 원래 은글꼴에 포함되는 것이 좋지 않을까 생각합니다.
은 글꼴 중 은 자모
은 글꼴 중 은 자모 바탕만 유일하게 첫가끝 낱자를 포함하고 있기 때문에 은 자모 바탕만 수정한 것입니다.
또한 GSUB 테이블 같은 건 미려한 모양을 출력하기 위해서(타자기 글꼴 모양이 아니라 네모꼴 모양) 필요한 것이기 때문에 반드시 필요한 것은 아닙니다. (또한 전 GSUB 테이블 같은 걸 만들 실력까지는 못 됩니다.)
글꼴 이름을 '은 자모 바탕 확장'으로 한 것은 원 은 자모 바탕에 유니코드 5.1 첫가끝 낱자를 추가했기 때문입니다. (제가 임의로 낱자들을 더한 게 아니라 곧 나올 유니코드 5.1을 따른 것입니다. http://kldp.org/node/89864 글을 참고하세요.)
첫가끝 낱자의
첫가끝 낱자의 정의가 글꼴 자형의 매트릭 정보를 조정해서 초성 코드 뒤에 중성, 종성 코드와 왔을때, 앞의 초성 자형에 중성, 종성 자형이 겹쳐서 표시되게 하여 결과적으로 하나의 조합된 한글글자처럼 보이게 하는 것을 말하나는가 보죠. 전 글꼴을 이렇게 설계한게 일종의 트릭이라고 생각하고 있었는데 첫가끝이라는 용어를 쓰는것 자체가 이런식의 방법을 쓴다는 말을 내포하는가보죠?
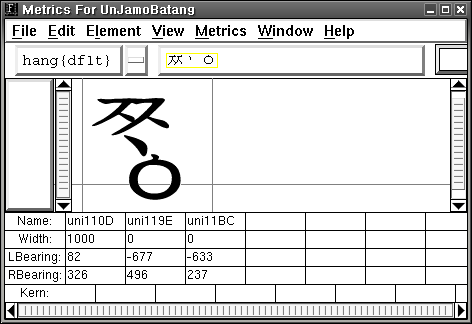
은자모바탕글꼴에서 유니코드 한글자모 영역을 표현한 자형은 그대로 은바탕 글꼴에도 적용되어 있습니다. 한번 확인해 보세요.
제 생각에는 어차피 은글꼴에서도 유니코드에 추가된 변화를 수용해야 할 것이기 때문에 이왕에 하는 작업이라면 원글꼴에 포함되는 것이, 리눅스 배포판에 적용등 여러모로 좋을 것이라고 생각해서 그렇 말씀을 드린 것입니다. 자칫 지금 하신 작업이 단발성 작업으로 끝나버릴 수 있으니까요.
첫가끝 글꼴은
첫가끝 글꼴은 그렇게 만드는 것이 맞다고 알고 있습니다(초성만 폭이 있고 중성, 종성은 앞에 달라붙게). 유니코드의 방침도 그렇다고 알고 있고요.
다른 은 글꼴에 추가하는 것은 생각해 보겠습니다. (은 글꼴은 제가 만든 게 아니라 다른 분이 만드신 거고, 전 은 자모 바탕을 '확장'한 것에 지나지 않습니다.)
그나저나
그나저나 폰트포지에선 키보드가 안 먹히는데, 이건 어떻게 해야 하나요?
예, 저도 그래서 다른
예, 저도 그래서 다른 곳에서 입력된 걸 복사해서, 붙여넣기(Ctrl+v)했습니다.
그나저나 유니코드
그나저나 유니코드 5.1엔 없고 한양 PUA에만 있는 종성 ㅇㅁ, ㅇㅅ, ㅇㅎ, ㆁㄱ, ㆁㅋ은 어떻게 표현해야 할까요?
그래서 더욱 GSUB
그래서 더욱 GSUB 테이블을 담고 있는 오픈타입 한글 폰트가 필요합니다.
이런 폰트가 있으면 사실 한글은 기본자모만 유니코드에 배정해도 충분합니다. 이를테면 ㄱㅅ 겹자모를 표현할 때 사용자는 단지 ㄱ과 ㅅ을 붙여 입력하기만 하면 됩니다. 이 경우 오픈타입을 지원하는 프로그램과 폰트가 주변의 자모를 파악하여 알아서 적절한 모양의 ㄱㅅ 자모로 전환시켜(glyph substitution: GSUB) 출력하게 됩니다.
제가 TeX 쪽에 관여하고 있어 잠시 언급하자면... 사실 TeX 계에서는 오픈타입 테이블을 지원하는 엔진들이 이미 나와있습니다. XeTeX이나 luaTeX 따위가 그런 것들입니다. 어플리케이션 쪽에서의 지원은 이미 되고 있는 셈이죠. 그런데 이것을 써먹을 수 있는 한글 오픈타입 폰트가 없습니다. 서양애들이 이거 이용해서 다양하게 원하는 모양의 문서를 만들어내는 걸 보면서 그저 부러워할 수밖에 없습니다. (예전에 신정식님과 박원규님이 테스트용으로 만들었던 UnBatangOdal 폰트는 뭐가 문제인지 작동하지 않더군요. 맥에서 이 폰트를 테스트해보려고 설치 시도하면 폰트에 에러가 있다면서 설치를 거부합니다.)
무엇보다 가독성 있는 출력물을 위해서라도 GSUB을 지원하는 폰트가 반드시 필요합니다. 빨래줄 글꼴을 출판에 사용할 수는 없겠지요.
유니코드 빈 자리에 새로운 글자 추가하는 것도 그리 나쁜 일은 아니지만 제대로 된 한글 폰트 쪽으로 노력하는 것이 더 실용적이라고 봅니다. 2008년에는 이런 기능을 제공하는 한글 오픈타입 폰트를 만나봤으면 하는 바랍입니다.
[ 수정 ] 잘못된 정보를 제공한 점 사과드립니다. 신정식·박원규님의 UnBatangOdal은 XeTeX 상에서 완벽히 의도한대로 작동함을 확인하였습니다.
see http://nomos.tistory.com/39
XeTeX상에서는 GSUB가
XeTeX상에서는 GSUB가 잘 작동하나 보군요. 훌륭합니다. 제반 환경은 다 갖추어져 있는 거군요.
아래 GTK2프로그램에서 이 글꼴을 어떻게 처리하나 살펴본 내용을 줄줄이 적었었는데 지워버렸네요. 섣불리 살펴보고 적은 글이 장님 코끼리 만지는 식이더군요.
GSUB Test
GTK2에서는 적어도 한글처리를 위해서 GSUB를 쓰지 않는 거 같습니다. 현대한글 첫가끝 코드를 한글음절영역의 자형으로 변환해서 보여주기는 합니다만, 이건 글꼴 정보를 사용하는 것이 아니라 Pango에서 내부적으로 처리하는 거 같습니다. 아무래도 제대로 GSUB 테이블을 가지고 있는 한글글꼴이 전무하다 보니 이렇게만 처리하는 거 같습니다.
TeX말고 간단히 GSUB를 테스트할 게 없는가 찾아보다, 박원규님의 글[1] 을 발견했습니다. 그 글과 김도현 님의 글을 참고해서 테스트한 결과를 올려봅니다.
세번째 그림이 김도현님께서 테스트한 것과는 약간 다른데, 이건 좀 살펴봐야 할 거 같습니다.
ftstrtto는 데비안에서는 freetype1-tools 안에 포함되어 있습니다.
박원규님의 글꼴 페이지 [2] 는 정말 여러가지 정보의 보고!!! 인거 같습니다. 그런데 이곳은 작업공간을 그대로 옮겨 놓은 성격이라서 뭔가를 참고해보려면, 결코 친절하지는 않군요. 그래도 아주 소중한 공간임에는 틀림없습니다.
----
[1] http://lists.kldp.net/pipermail/kle-dev/2003-March/001364.html
[2] http://chem.skku.ac.kr/~wkpark/project/font/
산업자원부
산업자원부 기술표준원 홈페이지 공지사항을 보니까, "2007년 11월 27일에 열렸던 한글코드처리 국가표준(KS) 공청회 개최"에 관한 소식이 공지사항에 나와 있더군요. 첨부된 파일을 열어보니 아래와 같은 내용이 있어서, 국가표준종합정보센터 홈페이지에서 해당 pdf파일을 찾아보았는데, 찾을 수 없었습니다. 혹시 에멜무지로님께서 이 자료를 가지고 있으신가요?
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
지금 그 규격을
지금 그 규격을 봤는데, '첫소리 글자와 끝소리 글자만의 조합은 허용하지 않는다'고 적혀 있군요.
그러면 초성이 빠진 미완성 한글은 허용되고, 중성이 빠진 미완성 한글은 허용되지 않겠군요. 좀 어이가 없습니다.
또한 ㄱ이나 ㅏ 같은 낱자를 단독으로 표시할 수는 없고, 반드시 앞이나 뒤에 채움 문자가 있어야 합니다.
(초성 ㄱ은 1100으로 끝나는 게 아니라 1100 1160, ㅏ는 1161로 끝나는 게 아니라 115F 1161, 종성 ㄱ은 11A8로 끝나는 게 아니라 1100 1160 11A8)
조합형 한글 글자 마디를 표현할 때 다음 사항을 주의해야 합니다.
1. 낱자 여러 개를 써서 겹낱자를 표현하면 안 됩니다.
예: ㄱㄱ (1100 1100, 틀림) → ㄲ (1101, 맞음)
2. 완성형 한글 글자 마디와 조합 한글 낱자를 다시 조합해 한글 글자 마디를 표현하면 안 됩니다.
예: 가ㅿ (AC00 11EB, 틀림) → ㄱㅏㅿ (1100 1161 11EB, 맞음)
3. 현대 한글은 반드시 완성형 한글 글자 마디로 표기해야 합니다.
예: ㄱㅏ (1100 1161, 틀림) → 가 (AC00, 맞음)
방점은 단독으로 표현할 수 없고, 반드시 한글 글자 마디 뒤에 와야 합니다. (거성 302E, 상성 302F) 방점 둘을 동시에 써서는 안 되고, 한번에 하나만 나타나야 합니다.
그런데 방점은 UCS에서 합성 기호(combining mark)로 쓰이기 때문에 글자 마디를 처리할 때에는 방점을 직접적으로 포함하지 않고 별도로 처리합니다.
바뀐 한글 낱자의 순서와 이름: 이 부분 굉장히 중요합니다. http://std.dkuug.dk/jtc1/sc2/wg2/docs/n3242.pdf 이 문서에 나와 있지 않아서 저도 몰랐군요.
11EC ᇬ: ㅇㄱ → ㆁㄱ
11ED ᇭ: ㅇㄱㄱ → ㆁㄱㄱ
11EE ᇮ: ㅇㅇ → ㆁㆁ
11EF ᇯ: ㅇㅋ → ㆁㅋ
이는 ㅇ(이응)으로 시작하는 잘못된 옛한글 낱자의 이름을 ㆁ(옛이응)으로 바로잡은 것으로서, 이 네 낱자는 ㅇ에 속하는 게 아니라 ㆁ에 속하는 걸로 구현하고 처리해야 합니다. 따라서 한글 글꼴을 만들 때에는 글꼴 모양을 ㆁ으로 만들어야 하며, 정렬을 할 때도 ㆁ 뒤쪽으로 순서가 지정돼야 합니다.
국가표준을
국가표준을 열람하려면...
가입하고 로그인 절차를 거쳐야 한다?
이 발상을 도무지 이해할 수 없습니다.
공공의식, 인권의식의 실종이라 할 수밖에...
제 컴퓨터에서는
제 컴퓨터에서는 리눅스 + 파이어폭스를 사용하고 있어서인지, 열람 자체가 안되는 것같은데, 에멜무지로님이 받으신 파일을 여기에 올려주셨으면합니다.
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
20일날 리눅스와
20일날 리눅스와 파이어폭스에서 지원문제에 관해 문의 했는데, 방금 리눅스 관련해서 저에게 전화로 연락이 왔네요.
KS규격은 지적재산권 문제가 걸려 있기 때문에, 무료로 배포를 할 수 없어, 판매나 열람하는 형식으로 제공한다고 하였습니다. 열람하는 과정에서 인쇄나 복제가 불가능하고 열람만 가능하도록 서비스를 제공하려고 하였는데, 리눅스나 맥에서 이런 기능을 제공하는 업체가 없었기 때문에 윈도우에서 밖에 제공할 수 밖에 없었다고 하더라고요.
그리고 파이어폭스에서 홈페이지 회원가입 문제는 홈페이지 관리 업체에 문의해서 해결하겠다는 답변을 받았습니다.
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
흠... KS X 1026-1 이
흠...
KS X 1026-1 이 어떤 용도를 위한 것인지 내용을 볼려고 들어가 보니, vmware를 통한 접속을 지원하지 않는다면서 끝내버리는군요. 굳이 가상 PC까지 막는 이유는 무엇일까요?
일단 화면에 보이는 정보는 어떤 식으로든 복제가 가능합니다.
홈페이지에
홈페이지에 가입하려고 하니까, nProject가 설치되면서 블루스크린이 뜨더군요. 아무래도 새나루입력기와 충돌이 일어나는 것 같아서, 윈도우 기본 IME로 바꾸었더니 문제 없이 진행되었습니다. KS규격검색에서 KSX1026-1를 검색해서 해당 자료는 찾았는데, 이런 경고문이 있네요.
파일 열람했더니, ActiveX가 설치 되면서 브라우져내에서 열람이되더라고요. 국가표준종합정보센터는 아무래도 국가 표준을 보급하는 목적보다는, 규격 판매를 위한 목적에 적합하도록 만들어 졌다는 느낌을 받았습니다. 불편하게 ActiveX로 보지말고 사서봐라는 거죠 -_-
어쨌거나, 문서의 내용을 요악하자면, 옛한글은 한글 자모 영역으로만 사용해서 나타내야하며, (초성낱자)(중성낱자)(종성낱자)(방점)을 각각 하나의 코드만을 사용하여 표현한 형태만을 허용하며, (종성낱자)와 (방점)은 없어도 되지만, (초성낱자)와 (중성낱자)가 없을 경우에는 항상 (초성채움문자)와 (중성채움문자)로 빈곳을 채워야합니다.
따라서, 다음과 같은 조합은 허용되지 않으며, 프로그램 내부적으로 올바른 표현으로 수정하여 출력해야 합니다.
초성과, 종성만 있는 글자:
(초성낱자)(중성채움)(종성낱자) -> 아마도 (초성낱자)(중성채움)(초성채움)(종성낱자)으로 수정되어 출력될 것 같은데, 이러한 조합 자체를 금지합니다.
낱자를 단독으로 쓰는 경우:
(초성낱자) -> (초성낱자)(중성채움)이 올바른 표현이고, 이런식으로 수정되어 출력됩니다.
(중성낱자) -> (초성채움)(중성낱자)이 올바른 표현이고, 이런식으로 수정되어 출력됩니다.
(종성낱자) -> (초성채움)(중성채움)(종성낱자)이 올바른 표현이고, 이런식으로 수정되어 출력됩니다.
모든 완성형 한글, 호환자모, 반각자모, 원문자, 괄호문자 등 과의 조합:
(완성형 한글)(종성낱자) -> (완성형 한글)(초성채움)(중성채움)(종성낱자)형태로 즉 처음 의도와 다른 형태로 수정되어 출력되는데, 이런 글자는 (초성낱자)(중성낱자)(종성낱자)형태로 표현해야 합니다. 이 부분은 지금의 정규화 알고리즘이 잘못되어 있기 때문에 유니코드 5.1 정규화 알고리즘에서 수정되겠지요.
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
그 규격 문서에는 (현
그 규격 문서에는 (현 초성)(현 중성)(옛 종성)의 경우 (완성형)(옛 종성)으로 처리되지 않는 방법도 싣고 있습니다. 또한 중성이 빠진 미완성 한글은 세벌식 모아치기 입력 과정에서 반드시 필요한데, 그런 조합 자체를 금지한다는 게 이상합니다.
위에 제가 쓴 종성 ᇬ, ᇭ, ᇮ, ᇯ에 대한 얘기는 읽어 보셨나요?
(저것 때문에 골치 아픈 문제가 생기겠더군요.)
한양 PUA와 유니코드
한양 PUA와 유니코드 5.1의 호환에 대해 기술 표준원에 질문했습니다.
http://www.kats.go.kr/fm_04/board_content.asp?board_idx=27167
답이 왔습니다.
답이 왔습니다. 아래는 답장 내용을 추린 것입니다. 원 답장은 위 URL을 누르시면 볼 수 있습니다.
제가 질문한 답변도 왔습니다.
http://www.kats.go.kr/fm_04/board_content.asp?board_idx=27169&page=7&
몇가지 빠진 질문이 있어서, E-mail로 추가 질문 하였습니다.
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
김도현님께서
김도현님께서 fontforge를 이용해서 GSUB 테이블을 집어넣는 좋은 글을 적어주셨습니다.
http://nomos.tistory.com/41
http://fontforge.sourceforge.net/featurefile.html
은 자모 바탕 확장이
은 자모 바탕 확장이 마지막으로 개정되었습니다. http://kldp.org/node/90361 글로 와 주십시오.
차라리 버전명이나
차라리 버전명이나 날짜를 붙여서 보급하시는건 어떨까요?
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
옛한글이 실제로
옛한글이 실제로 사용 되기 위해서는 코드를 확정하고 글꼴을 만드는 것도 중요하지만, 그것은 전문가들이 해야할 일이고, 일반 사용자에게는 얼마나 편리하게 옛한글을 입력할 수 있는가가 중요하다고 생각합니다. 그러니까 자판을 어떻게 만들고, 어떤 식으로 입력하는가가 중요한 것이죠.
3벌식은 자판은 지금도 옛 한글 자판이 있긴 하지만, 기존 글쇠를 없애고 옛자모를 넣어야 하기 때문에, 기존의 현대 한글에 최적화된 자판과 호환이 되지 않는 어려움이 있습니다. 2벌식의 경우에는 Shift키로 입력하는 글쇠에 빈 자리가 있기 때문에, 그곳에 옛한글을 배치하면 되니, 기존 자판과의 호환성에는 문제가 없겠지만, 받침과 첫소리를 구분하여 처리하는데 새로운 방법이 필요할 것입니다.
하지만 지금 KS표준은 2벌식 밖에 없으니, 옛한글 활동을 추진하는 산업자원부 기술표준원에서는 2벌식 자판을 기준으로 만들지 않을까 생각합니다.
자판을 만든 이후에는 입력기를 보급하는 것이 중요할 것인데, 이것은 어떻게 진행 될까요? 설마 익스플로러에서만 사용할 수 있는 Active X 입력기를 만들어 내진 않겠죠...
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
옛한글 정보화를
옛한글 정보화를 문자코드연구센터라는 곳에서 하고 있는 것 같더군요. 문자코드연구센터 소식지를 보시면 제18호와 제19호에 옛한글 정보화에 관한 소식이 실려 있으니, 관심 있으시면 읽어보시기 바랍니다. 옛한글에 관한 질문은 기술표준원보다는 여기에 직접 물어보는 것이 어떨까요?
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
저도 문자 코드 연구
저도 문자 코드 연구 센터 소식지 19호를 읽고 유니코드 5.1에 옛한글 낱자가 추가된 걸 알았습니다.
궁금한 점이 있는데,
궁금한 점이 있는데, 옛한글 글꼴은 왜 일반 글꼴과 따로 만드는 것이죠? 은 바탕 자체에서 현대한글과 옛한글을 모두 지원하면 좋을 텐데요... 기술적으로 불가능 한건가요?
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
____
The limits of my language mean the limits of my world. - Ludwig Wittgenstein
은글꼴이 현재
은글꼴이 현재 제대로 관리가 되지 않고 있기때문인 것이지 기술적으로 불가능하거나 하는 것은 없습니다.
옛한글 글꼴이라고
옛한글 글꼴이라고 해서 현대 한글을 지원하지 않는 건 아닙니다. 옛한글만 지원하는 글꼴이 아니라 옛한글도 지원하는 글꼴이죠.
기술적인 문제는 어느 정도 노하우가 쌓여 있는 것 같습니다. UnBatangOdal만 봐도 그렇죠. 새로 조합규칙을 확장하고, 자형을 예쁘게 그려넣는 과정이 계속되어야 하는데, 그렇지 못했죠. 메일링 리스트의 여러글을 읽어 보니 2000~2004년 경에 상당히 활발히 논의되었더군요. 시간이 흘러 다들 생업에 바쁘시다 보니 그렇게 된거 같습니다.
좀 다른 이야기로,,,
은글꼴은 몇몇 문제가 해결이 되지 않아 페도라 코어에 아직 포함되지 않은 걸로 알고 있는데, 리눅스용 대표글꼴로 밀려면 차라리 백묵 글꼴을 개선하는 것이 나을 듯 합니다. 이 경우 그냥 버전업되는 것으로 적용되어질 테니까요.