우분투 devel 메일링에서 BetterCJKSupport가 논의되고 있습니다

글쓴이: atie / 작성시간: 금, 2005/10/28 - 6:54오후
다음의 launchpad와 wiki에 앞으로 논의될 내용이 정리가 될 듯 합니다.
Quote:
you can subscribe to the spec here.
https://launchpad.net/distros/ubuntu/+spec/better-cjk-support
and the wiki page is here:
https://wiki.ubuntu.com/BetterCJKSupportSpecification
dapper에는 scim을 기본 입력기로 하자는 이야기 나왔습니다. 그런데, 이런 메일이 있어 인용합니다.
Quote:
So far I haven't heard of anybody working on Korean input though. I sadly know very little about how Korean input works, but surely we are going to make sure that it also ROCKS, or?
Quote:
Concerning Korean input, SCIM actually has some usable input modules for Hangeul (both romanized and using a Korean keyboard layout), but I don't think it has any methods for inputting text with Chinese characters, which will also be useful in certain academic contexts, for instance. The only input method I know of is "Ami", which is a XIM-based method that has to be run under a ko_KR.eucKR locale or something in that order.
nabi와 imhangul에 대한 정보를 주는 것이 시급하다는 생각을 했습니다. (작년에 페도라를 쓰면서 IBM의 5250 Linux 터미널에 문제가 있어 개발자와 메일을 주고 받을 때도 수세를 쓰는 개발자는 ami 밖에 몰라 nabi를 check out 할 것을 권한 적이 있었습니다.)
자, 여러분은 BetterCJKSupport를 위해 무엇을 우분투 dapper에 넣었으면 하는가요? 저는 embolden을 기본 활성화 시키는 것이 첫번째로 생각이 들던데요.
File attachments:
| 첨부 | 파일 크기 |
|---|---|
| 187.74 KB | |
| 95.3 KB | |
| 48.08 KB |
{kind=link}
{kind=link}
{kind=link}
댓글
scim이 상당히 매력적이긴 한데, 3벌식이 지원이 별로더군요.수세9
scim이 상당히 매력적이긴 한데, 3벌식이 지원이 별로더군요.
수세9.2버전에서 scim이 기본이었고 저는 세벌 390을 쓰는데,
숫자쓰기나 기호같은것들이 잘 지원되지 못했던걸로 기억됩니다.
음.. 그리고 한글사용에서 의외로 불편한것이 글자커밋이더군요.
aMule이나 모질라등에서 끝글자 커밋이 깔끔하게 되지 않습니다.
kdevelop등도 문제가 조금있구요(http://bbs.kldp.org/viewtopic.php?t=64565&highlight=kdevelop)
그밖에 플레쉬나 자바등의 글꼴등도 쉽게설정할수 있었으면 좋을것 같습니다.
poklog at http://poksion.cafe24.com/poklog/
일단 embolden enabled as default는 위키에 넣었습니
일단 embolden enabled as default는 위키에 넣었습니다.
amule 등에서 끝글자 짤리는 것은 패치가 나왔던 것으로 기억을 하는데 우분투의 imhangul 버전과 imhangul 홈피에서 다운받는 버전이 같은지라 imhangul을 버전업 한 후에 새로 패키징을 해달라고 요청을 하는 것이 어떨까요? 나비도 패치가 있던가요?
scim을 기본으로 하는 것에 대해서는 어떻게 생각을 하는가요? 저는 오히려 불편할 듯 싶은데요. 한글과 일어/중어를 같이 쓰지 않는 경우에는 기본 설치된 scim을 삭제하고 다시 nabi를 설치하게 되지 않을까요?
----
I paint objects as I think them, not as I see them.
atie's minipage
KoreanInputMethod 페이지가 있습니다.
http://wiki.kldp.org/wiki.php/KoreanInputMethod
외부에 알리자고 만든 페이지 아닌가요? 안 그럼 뭐하러 영작까지 했겠습니까.. 8)
이건 무적 철인 krisna옹이 cvs에 고쳐놨습니다. 다음 버전이 나오면 바뀔 겁니다.
위키에 MP3 태그에 대한 얘기가 나온 김에, 줏어들은 이야기지만 간단히
위키에 MP3 태그에 대한 얘기가 나온 김에, 줏어들은 이야기지만 간단히 적어봅니다.
ID3v1의 경우 공식적으로 ISO 8859-1만 지원합니다. 윈도용 프로그램에서 한글을 태그에 넣을 경우 보통은 시스템 코드페이지에 맞춰 인코딩되는 것 같습니다.
ID3v2의 경우 버젼에 따라 ISO 8859-1, UTF-8, UTF-16 등을 지원하지만, 상당수의 프로그램이 멀티바이트 지원을 제대로 하지 않고 ISO 8859-1 필드에 역시 시스템 코드페이지에 맞춰 인코딩한 내용을 채워넣는다고 합니다. 제대로 한다면 UTF-16 전용 필드 같은 곳에 넣어야 하겠죠.
단순히 ISO 8859-1 필드의 표시 문제를 땜빵한다고 근본적으로 해결될 문제는 아니리라 생각합니다.
한글 키보드 설정도 들어갔으면 좋겠습니다. 키보드 설정 보면 웬만한 국가
한글 키보드 설정도 들어갔으면 좋겠습니다. 키보드 설정 보면 웬만한 국가별 키보드가 다 있는데 우리나라만 없더군요. 한영키, 한자키 인식 문제는 커널 차원에서부터 해결할 수 있어야할 것 같고 xmodmap 등으로 따로 설정 안하고 한글 키보드를 선택하는 것으로 할 수 있게 했으면 좋겠습니다.
embolden의 경우 패키지 버전만 올라가면 됩니다.현재 브리지에서
embolden의 경우 패키지 버전만 올라가면 됩니다.
현재 브리지에서 활성화 되지 않는 것은 패키지 프리즈가 들어간 후에 업데이트 된 버전에서 작동하기 때문인 것 같습니다.
nabi 보다는 아무래도 scim-hangul이 들어가는게 맞는 것 같습
nabi 보다는 아무래도 scim-hangul이 들어가는게 맞는 것 같습니다.
이대로는 한국어 환경의 리눅스에서는 다국어 입력에 발전이 전혀 없을 것 같군요. (나비가 간단해서 좋긴 합니다만...좀 더 크게 봐야죠. 자기만 편하다고 다가 아니니.)
[quote="ditto"]embolden의 경우 패키지 버전만 올라가면
그럼 대퍼를 따라가면 자연스레 해결된다고 볼 수 있나요?
-----
http://monpetit.posterous.com/
http://monpetit.tistory.com/
scim은 다른 것은 별 불만이 없는데, CTRL+SPACE가 불편해요.
scim은 다른 것은 별 불만이 없는데, CTRL+SPACE가 불편해요.
https://wiki.ubuntu.com/KoreanTeam
[quote="검은해"]위키에 MP3 태그에 대한 얘기가 나온 김에, 줏
id3v1 의 경우 문자 인코딩을 정하는 필드가 아예 스펙에 없습니다. 무조건 iso 8859-1 인코딩으로 집어넣으라고 되어있죠. (사실 id3v1 은 스펙도 제대로 없긴 합니다. 워낙 간단하구요 ;; )
그리고 id3v2 의 경우 2.3.0, 2.4.0 의 경우가 다른 걸로 알고 있습니다. 2.3.0 의 경우 문자 인코딩을 지정하는 필드에 iso 8859-1 혹은 utf-16 을 지정할 수 있습니다. 2.4.0 의 경우에는 필드에 iso 8859-1, utf-16, utf-16LE, utf-8 4가지 인코딩을 지정할 수 있습니다.
윈도우 프로그램 중에서 현재 id3 태그를 유니코드로 가장 잘 지원하는 프로그램은 itunes 라고 생각합니다. itunes 로 mp3 태그 고치고 태그를 뜯어보면 스펙대로 잘 되어 있습니다. 잘못 안코딩 된 태그를 유니코드 태그로 잘 바꿔주는 편이구요. 푸바도 그럭저럭 괜찮은데, 널 문자를 안 넣는 경우가 있었습니다.
국내에서 유통되는 mp3 id3 태그의 90% 이상이 cp949 로 문자열을 인코딩되어 있습니다. 물론 인코딩 지정 필드에는 iso-8859-1 로 되어 있구요. 보통 이런 파일이 일반적인 mp3 플레이어에서 잘 보입니다.
결국 mp3 플레이어가 태그 인코딩에 대해서 처리 해 주는 수 밖에는 없는 실정입니다. 몇몇 리눅스 계열 프로그램도 id3 태그를 읽을 때 iso 8859-1 을 특정 인코딩으로 인식하라는 옵션이 있습니다. 아니면 그냥 현실을 인정하고 cp949로 인코딩 하고 처리하는 방법이 있는데 그다지 깨끗해 보이지는 않습니다;; 그래서 저는 윈도우즈에선 itunes 와 foobar 만 사용합니다. 인코딩만 utf 로 잘 되어 있으면 리듬박스나 아마록에서는 잘 보입니다. 그리고 제 기억에 아마록은 iso 8859-1 를 euc-kr 등으로 읽어들이는 걸 지원합니다.
리눅스에서 id3v2 잘 지원하는 어플로는 amaroK, rhythmbo
리눅스에서 id3v2 잘 지원하는 어플로는 amaroK, rhythmbox 등이 있지요.
의외로 id3v2 잘 지원하는 어플(한글까지)이 적더군요. easytag 도 아직이고...
윈도우에서는 foobar2000, iTunes 등이 있는데, iTunes 는 가끔 id3v2 대신 id3v1 를 읽어주시는 것 같습니다.
ogg 는 태그를 무조건 유니코드로 저장하므로, 이런 문제가 없어서 좋더군요.
wma 도 태그를 유니코드로 저장합니다만, 아직까지 리눅스에서 wma 태그를 수정할 방법이 없는 것 같습니다. 저는 현재 리눅스에서 VMware 를 틀어서 복잡하게 수정합니다. 혹시 다른 좋은 방법이 있나요?
scim 도 토글키 재지정 기능을 지원합니다. 전 지금 scim 을 한영키로 쓰고 있습니다.
----
블로그 / 위키 / 리눅스 스크린샷 갤러리
다국어 입력기 중에는 scim이 그나마 제일 나은 것 같은데요... ;;
다국어 입력기 중에는 scim이 그나마 제일 나은 것 같은데요... ;;
iiimf는 깔끔하긴 하지만 기능이 적은 듯 하고, uim은 한글 입력이 잘 안되었습니다.
페도라 코어 5에서도 iiimf 대신 scim을 쓰기로 했다고 합니다.
위에 voljin님이 쓴 글을 보니 제 생각이 짧았음이 느껴지는군요.
위에 voljin님이 쓴 글을 보니 제 생각이 짧았음이 느껴지는군요.
scim을 쓰게 된다면, en_US.UTF-8만 설정한 상태에서도 한글 또는 다른 언어의 입력기를 활성화 키를 눌러 동작시킬 수가 있나요? 나비에서는 이것이 되므로 저는 locale은 en_US.UTF-8으로 설정을 하고 한/영을 쓰고 있습니다. 그리고, scim이 기본 설정으로 포함이 된다면 한글 입력기 관련한 요구 사항들을 정리해 주실 분 계신가요?
MP3 tag관련해서는 위키에 다음이 있는데,
좀 더 요구 사항을 위키에 보충하는 것이 좋겠다면 이것도 정리를 해보았으면 합니다.
한영키 인식에 대한 다른 분들의 생각은 어떤가요? 또한, 플래시와 자바의 글꼴 설정은 어떻게 풀어가야 하는지도 보충 의견 부탁 드립니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
Re: KoreanInputMethod 페이지가 있습니다.
페이지 업데이트 된 것 보고 위의 우분투 위키에도 링크 걸었습니다. 8)
----
I paint objects as I think them, not as I see them.
atie's minipage
[quote="ditto"]다국어 입력기 중에는 scim이 그나마 제일
uim 에 byeoru라는 모듈을 설치하면 한글 입력이 잘 됩니다. (네, 그 벼루 만드신 분이 만드셨습니다. :-))
0.5버전부터는 포함시킬 거라고 하더군요.
http://newton.kias.re.kr/~jhpark/uim/ 에 있습니다.
----
Let's shut up and code.
한영키 문제를 잠깐 다시 정리하면, 여긴 두 가지 문제가 있습니다. 첫번
한영키 문제를 잠깐 다시 정리하면, 여긴 두 가지 문제가 있습니다. 첫번째는 한영키의 키코드가 아예 인식이 안되서 우분투에서 setkeycodes로 설정을 해주어야 한다는 것입니다. 이 문제는 커널의 키보드 드라이버의 문제인 것으로 보이며 설정을 어떻게 바꾼다고 해결되는 문제가 아닌 듯 합니다. 작정하고 커널 소스를 들여다봐야 해결이 될 것 같습니다.
두번째는 한글 키보드 설정이 없기 때문에 setkeycodes로 키코드를 인식해도 한영키가 심볼로 매핑이 되어 있지 않다는 것입니다. 그래서 xmodmap으로 설정을 해주는 방식으로 땜빵해서 쓰고 있죠. 이 문제를 해결하려면 xkb에 ko 키보드에 대한 설정을 추가해야 합니다. 이 부분 때문에 XKBConfiguration 관련 문서를 보고 있는데 그다지 어렵지 않게 추가할 수 있을 것 같습니다. 이 설정들을 우분투 xkb 패키지에 포함시키면 될 것입니다.
요즘 리눅스를 들여다보고 있을 상황이 아니라 진도를 못 나가고 있는데 이 문제가 해결되길 바라는 사람이 많다면 같이 좀 노력해봤으면 합니다.
이외에 IM에 대한 얘기를 첨언하면, nabi가 되었든 scim이 되었든 한 머신에서 다국어의 입력이 가능했으면 합니다. 한글도 입력하고 히라가나도 입력하고 중국어, 프랑스어, 독일어 이런 거 다 입력 가능했으면 좋겠다는 것이죠. 그 방법으로 하나의 IM에서 다 소화하는 방법도 있을 수 있겠지만 키보드 맵 전환키를 누르면 IM도 전환되는 등의 방법도 나쁘지 않다고 봅니다.
그리고 IM을 설치하면 XIM 설정에 바로 등록할 건지를 물어봐서 등록하게 하는 등의 기능이 있었으면 합니다.
[quote="wish"][quote="검은해"]위키에 MP3 태그에 대
그나마 ID3v2에서 텍스트를 처리하기 위한 가장 합리적인 workaround는,
* 인코딩이 ISO-8859-1이면 때려 맞추기를 통해서 인코딩을 짐작합니다. 이 인코딩은 보통 태깅된 시스템의 네이티브 인코딩이겠지만, 사실 이거 짐작하는 것도 만만치 않습니다. 웹 브라우저 같이 텍스트가 비교적 많은 경우 (모질라가 그러듯이) 통계적인 방법으로 접근할 수도 있겠지만 이 경우 샘플 텍스트가 너무 적어서 그리 큰 효과를 보지 못 할 듯 싶습니다.
* 아니면 그 인코딩을 그대로 씁니다.
물론 ISO-8859-1 인코딩을 쓴다고 표시된 텍스트는 모두 같은 인코딩으로 되어 있다는 가정이 있어야 겠지요.
- 토끼군
사소한 문제일지도 모르겠지만, 고정폭 글꼴에서 터미널을 제외한 부분(ge
사소한 문제일지도 모르겠지만, 고정폭 글꼴에서 터미널을 제외한 부분(gedit이나 firefox같은 웹 브라우저 등)의 고정폭 지원이 제대로 지원되질 않습니다.
예를들어
같은 경우 윈도우에 들어있는 한양 고정폭 글꼴을 써도 제대로 폭이 맞지 않습니다.이런 현상은 어떤식으로 해결하면 좋을까요?
----------------------------------------
Kwonjin Jeong
[quote="pok"]scim이 상당히 매력적이긴 한데, 3벌식이 지원
http://people.kldp.org/~krisna/blog/entry.php?blogid=408
scim-hangul 새버젼이 릴리즈되었으니 그 문제는 해결되지 않았을까 싶네요 :)
utf-8 인코딩이기만 하면 한글입력에 문제가 없었던걸로 기억합니다... 다만 제가 사용하던 시절 (한 6개월전) 에는 기본 입력기 설정이 안되서 매번 입력기 전환 키를 눌러서 한글입력기로 바꾸는 일이 필요했었는데 요새는 어떤지 모르겠습니다.
자바 글꼴문제는 fonts.properties.ko 를 적절하게 고쳐주는 것으로 해결할 수 있고... flash 는 /etc/X11/fs/config 에 한글폰트 디렉토리도 등록해주면 해결됐었던 걸로 기억하는데 요새 X를 안쓰고 있어서 확인해볼 수가 없네요 :)
오랫동안 꿈을 그리는 사람은 그 꿈을 닮아간다...
http://mytears.org ~(~_~)~
나 한줄기 바람처럼..
[quote="랜덤의여신"]리눅스에서 id3v2 잘 지원하는 어플로는 a
iTunes 에서 id3 버젼을 2.3 이상으로 전부 일괄 변경해줘버리시면... (마우스 오른쪽 버튼을 누르고 "id3 태그 변환" 을 통해 쉽게 할 수 있습니다) 리듬박스등에서 한글문제는 없습니다...
태그들은 윈도우에서 tag&renamer 로 정리하고 iTunes 에 등록해서 v2.4 로 업데이트 하는 방법을 사용 중인데 ... 나름 만족스럽군요 :)
오랫동안 꿈을 그리는 사람은 그 꿈을 닮아간다...
http://mytears.org ~(~_~)~
나 한줄기 바람처럼..
Re: 우분투 devel 메일링에서 BetterCJKSupport가 논의되고 있습
qt 용 한글 입력 모듈인 qimhangul 과... gtk2 용 한글 입력 모듈인 imhangul 도 밀어넣어주세요 =3=33
오랫동안 꿈을 그리는 사람은 그 꿈을 닮아간다...
http://mytears.org ~(~_~)~
나 한줄기 바람처럼..
[quote="creativeidler"]한영키 문제를 잠깐 다시 정리하
우분투 위키의 XRoadmap에 따르면 xkb의 유지보수에 대한 건은 freedsktop.org의 xkeyboard-config 프로젝트에서 담당한다는 이야기가 나옵니다. 우분투에서는 early 테스트를 통해서 많은 feedback을 받겠다는 언급이 있으니 dapper 테스팅에 몇 분이라도 적극적이면 (어쩌면) 이 문제는 쉽게 해결이 될 듯도 합니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
배포판의 기본 폰트도 좀 세련된걸로 바꾸었으면 합니다.백묵이나 대
배포판의 기본 폰트도 좀 세련된걸로 바꾸었으면 합니다.
백묵이나 대우인가.. 가 기본 폰트라 항상 별로 이쁘지가 않습니다.
은폰트 같은걸 기본으로 했으면 합니다.
[url]https://wiki.ubuntu.com/BetterCJKSu
https://wiki.ubuntu.com/BetterCJKSupportSpecification
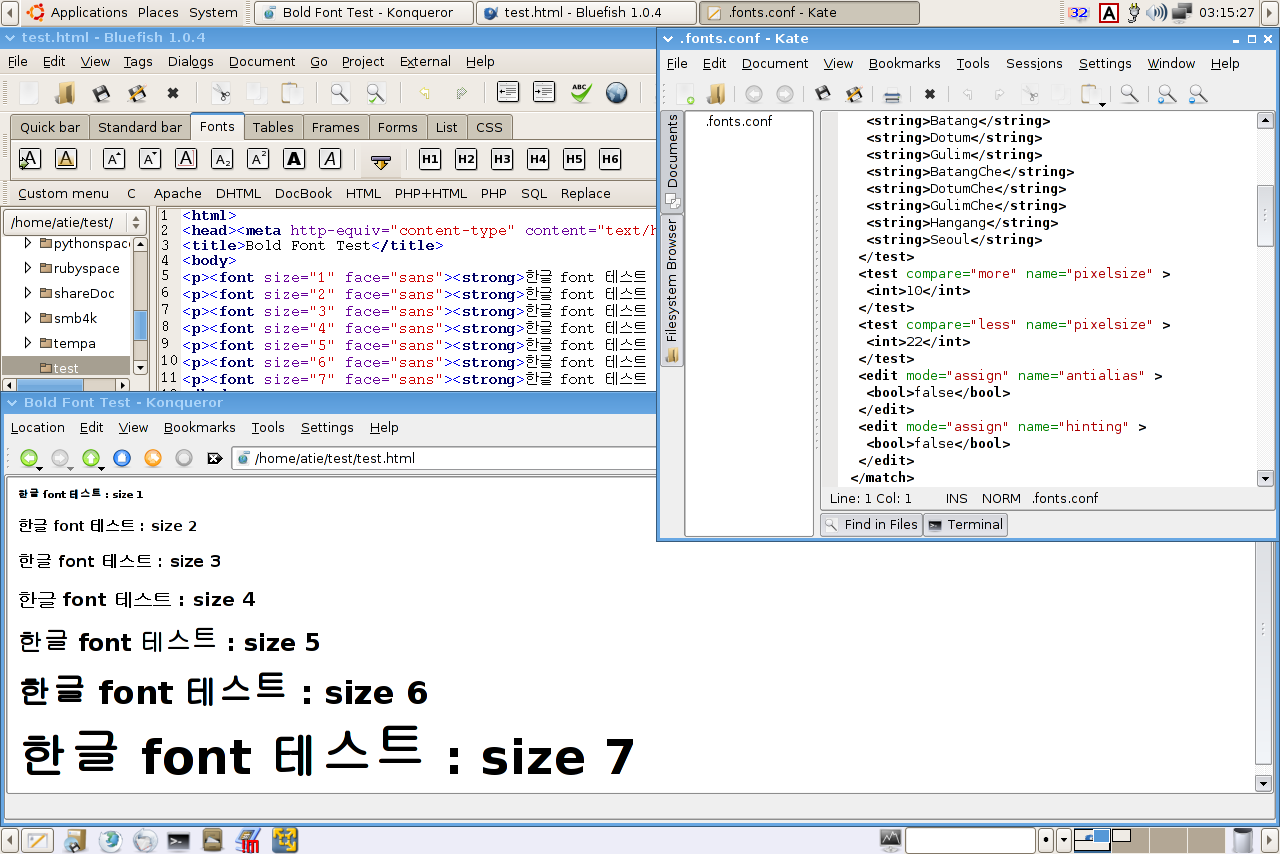
위키에 링크를 걸기 위해 konqueror에서 볼드가 이상이 있는 그림을 첨부합니다.
그리고, 위의 위키가 이제는 첫 스펙 단계로 들어갔습니다. 관심있는 분들은 읽어 보시기 바랍니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
BetterCJKSupportSpecification 웹페이지에 보니까
BetterCJKSupportSpecification 웹페이지에 보니까
라고 되어 있는데, 기존의 breezy에 있는 im-switch와는 어떻게 관계되나요? im-switch의 경우 /etc/X11/Xsession.d/90im-switch로 실행 스크립트가 있고, /etc/X11/xinit/xinput.d/$locale 을 읽어옵니다. 각각의 로케일 파일은 XIM, XIM_PROGRAM, XIM_ARGS, GTK_IM_MODULE, DEPENDS 를 수정하게 되어 있고요.
https://wiki.ubuntu.com/KoreanTeam
[quote="uriel"]BetterCJKSupportSpecifica
위키 페이지에 질문을 해 놓았습니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
KDE에서 AA된 굵은 글씨가 위로 치솟는 문제는 아래 URL을 살짝
KDE에서 AA된 굵은 글씨가 위로 치솟는 문제는 아래 URL을 살짝
보세요...
http://lists.freebsd.org/pipermail/freebsd-gnome/2005-July/011838.html
저기에 링크된 패치에 보시면 잘못된 Y포지션 계산을 고친 부분이 있습니다...
--
Have you ever heard about Debian GNU/Linux?
[quote="kyano"]KDE에서 AA된 굵은 글씨가 위로 치솟는 문
좋은 정보, 고맙습니다. 패치가 적용이 될 수 있는지 스펙에 내용을 추가해 놓겠습니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
[quote="atie"][quote="kyano"]KDE에서 AA된 굵
kyano님이 알려주신 freetype-2.1.10 patch를 적용한 firefox와 konqueror의 스샷입니다. 파폭에서 보면 굴림체로 표현되는 한글과 영문은 선명하게 잘 나옵니다. 그리고 컹커러에서 오른쪽으로 올라가는 문제도 해결이 되었고요. 그런데 문제는 이렇게 하면 메뉴에서 보이듯 bitstream vera sans로 설정된 영문 글꼴이 선명하지 못하고 울퉁불퉁해 보입니다. 해결책이 있는지요? 이 스샷을 보면 영문 글꼴을 쓰는 쪽에서는 패치를 적용할 마음이 사라질텐데 곤란하다는 생각이 듭니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
[quote="atie"]그런데 문제는 이렇게 하면 메뉴에서 보이듯 bi
어디를 말씀하시는 것인가요? 잘 못 찾겠는데요??
이전의 그림을 보지 않아서 그런가요?
(전 대부분 메뉴가 한글이라서)
제 경우에는 컹커러 등에서 이런 문제가 해결이 되었습니다.
확인해 보니, freetype에다가 페도라의 패치를 갖다가 쓴 덕분입니다.
페도라 패치중에 CVS에서 가져온 것이 그 역할을 하는 것으로 보입니다.
[quote="utpark"][quote="atie"]그런데 문제는 이렇
파폭에서 굴림의 한글 영문이 잘 나오는 것으로 봐서 한글 메뉴이면 아무 이상이 없을 듯 하고 스샷에서는 잘 안 느껴지는데 deb을 재설치하고 바로 보면 뭔가 영문 글씨가 (프로그램 메뉴에 있는) 약간 진해지고 울퉁불퉁하다는 것이 느껴집니다.
페도라의 패치를 가지고 있으시면 첨부나 링크를 해 주시겠습니다. 아니면 위의 링크에서 freetype-2.1.10 patch와 같은 것인지를 봐 주시면 더욱 좋고요.
----
I paint objects as I think them, not as I see them.
atie's minipage
[quote="atie"][quote="utpark"][quote="at
firefly씨의 usegamma 패치인 것 같습니다. gamma값을 fontconfig에서 조정할 수 있게 되고, CJK글꼴이 더 잘보인다는 것으로 알고있습니다.
자세히 살펴보니, 단지 USEGAMMA만 정의해놓은 패치군요
(그렇다면, firefly씨의 freetype 패치가 이미 들어있다는 것이고)
USEGAMMA부분에 Y조표를 계산을 하는 코드가 있는 것인지..?
온갖 참된 삶은 만남이다 --Martin Buber
저도 페도라 패치 링크를 찾아서 보았습니다. (https://www.re
저도 페도라 패치 링크를 찾아서 보았습니다. (https://www.redhat.com/archives/fedora-cvs-commits/2005-October/msg00281.html)
firefly의 패치와 y값 계산을 하는 것은 동일하면서 다른 내용이 훨씬 많이 있군요.
#define GRAYS_USE_GAMMA 이것이 더해졌습니다. (#define xxxGRAYS_USE_GAMMA과의 차이는 무엇인지 모르겠습니다.)
예, 버그 리포팅은 이미 되어있고, 우분투에서는 제게 테스트한 빌드를 요청을 해서 하나 만들어 위의 첨부 화면을 링크 걸었으니 이제는 페도라 패치를 링크 걸기만 하면 될 듯 합니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
위의 firefly patch에서 usegamma 부분만 다시 원상태로
위의 firefly patch에서 usegamma 부분만 다시 원상태로 하고 빌드를 하면, 굴림에서 한글과 영문이 나오는 것 아무 차이가 없습니다. 영문 글꼴은 약간 노란 색이 낀 것 처럼 보입니다. 컹커러의 문제는 동일하게 고쳐집니다. 그런데, 문제는 파폭에서 큰 굵은 한글 글자들에 대해 매 두번째 글자마다 약간씩 올라가는 것이 보입니다.
아무래도 페도라에 있는 패치를 적용해 보아야 하겠습니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
[quote="atie"]위의 firefly patch에서 usegamm
잠시 바쁜 사이에 얘기다 많이 진행이 되었네요.. :o
테스트에 좋은 결과가 있었으면 좋겠습니다. 화이팅.. :wink:
위의 페도라 패치를 테스트 했습니다. 결과는 firefly 패치를 썼던
위의 페도라 패치를 테스트 했습니다. 결과는 firefly 패치를 썼던 것보다 훨씬 좋습니다. y값 패치는 동일하게 적용이 되어서 컹커러 문제는 fix가 되고, firefly 패치와는 달리 usegamma 패치가 없고 대신에 안티알리어싱 등을 포함한 몇 개의 패치가 더 있어서 Bitstream에서 나오는 영문 글꼴도 선명하고 굴림에서 나오는 영문/한글도 모두 선명히 잘 보입니다.
그러나, 여기에 있는 고정폭 글꼴 문제는 여전하고 굴림에서 "활"자 같은 글자는 보이지 않습니다.
그런데, 페도라의 패치 이름을 읽다보니 그 패치가 cvsfixes던데 freetype cvs 버전인가요? 그렇다면 다음 버전의 freetype이 나올 때까지 배포판에서는 cvs에서 소스를 댕겨다 쓰면 문제가 해결이 된다는 이야기인데... 아무튼 우분투에는 페도라의 패치를 테스트 해달라고 요청을 했고 이게 고쳐지면, 다음에 "글자 안 나오는 것" 그리고 "고정폭 글꼴" 등등해서 하나씩 버그 보고를 할 생각입니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
[quote="atie"]그런데, 페도라의 패치 이름을 읽다보니 그
우선 전체 cvs를 가져다 쓰는 문제는 좀 골치 아플 것 같습니다.
현재 건드려 놓은 코드를 배포본 꾸러미 관리자가 손을 봐야 하는데 이중일이 될 가능성이 있습니다. 따라서 페도라에서 이미 정리한 패치를 가져와서 사용하는 것이 바람직해 보입니다.
(직접 cvs를 가져와서 테스트해보니 더 이상 좋은 점은 없고, 휠마우스 하고 부딪히는 문제가 있네요..다른 문제도 있겠죠..??)
"활"자 안나오는 문제도 제 시스템에서는 조금 높게 나오지만 다른 글자들과 큰 차이점이 없습니다.("볼"자도 조금 높게 나옵니다.)
또한, "고정폭 글꼴"에 대한 문제도 제 시스템에서는 없기 때문에, 시간이 나면 좀 자세히 들여다 봐야 겠습니다.
굴림에서 "활"자가 안 나오는 것은 저는 이 글의 제목으로 테스트를 합니
굴림에서 "활"자가 안 나오는 것은 저는 이 글의 제목으로 테스트를 합니다. 구슬에서 보면 "활"자가 잘 보입니다. 그리고, 제가 간단히 8pt-22pt까지 굴림과 구슬을 섞어서 만든 초간단 html에서는 "활"자가 잘 보입니다.
따라서, 혹 사용자의 pc 성능, 페이지의 복잡도 또는 글자의 획수 등이 가짜 볼드 렌더링에 영향을 주는 것이 아닐까 짐작만 하고 있습니다.
우리도 불나방이 몇 날아다니면 좋겠습니다. :wink:
----
I paint objects as I think them, not as I see them.
atie's minipage
[quote="atie"]우리도 불나방이 몇 날아다니면 좋겠습니다. :
힝힝 firefly 는 개똥벌레에요 =3=33
오랫동안 꿈을 그리는 사람은 그 꿈을 닮아간다...
http://mytears.org ~(~_~)~
나 한줄기 바람처럼..
[quote="정태영"][quote="atie"]우리도 불나방이 몇 날아
반딧불이가 개똥벌레인가요? 그렇다면 오늘에서야 알게 되었네요.
----
I paint objects as I think them, not as I see them.
atie's minipage
우분투 포럼에서도 scim에 대한 개발의 중요도가 타당하냐는 문제가 제기
우분투 포럼에서도 scim에 대한 개발의 중요도가 타당하냐는 문제가 제기 되었습니다. http://ubuntuforums.org/showthread.php?t=86329
"울고 싶은데 누가 때려주는" 꼴이 되었는데, 제가 아쉽게 생각하는 것은 scim 뿐만 아니라 한글 사용 환경을 좀 더 사용자에게 편하게 제공을 하려면 "아는 것과 진행할 인력"인데 그게 문제라는 거죠.
솔직한 이야기로 저를 포함해서 이 스펙에 작성에 참여하고 있는 사람은 제가 본 것으로는 3명입니다. 그렇지만 진도가 나가는 것이 저조합니다.
도움이 필요합니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
[quote="atie"]굴림에서 "활"자가 안 나오는 것은 저는 이 글
firefly씨 패치는 거의 1~2년 전부터 알려졌고, 이분이 글꼴 쪽으로 많은 패치를 만드셨지만, 패치를 메인에 반영하는 것엔 전혀 관심이 없는 것 같더군요.
usegamma패치만 해도중국 리눅스 배포판에 기본으로 들어갔는지, fontconfig 서치만 해보면 꼭 나옵니다.
패치를 적절히 쪼개고, 반영할 수 있는 것은 반영하려고 하는 노력이 조금만 더 있었다면 하는 아쉬움이 있습니다. :(
온갖 참된 삶은 만남이다 --Martin Buber
위의 스펙 중에 있는 것들중에 집중을 해서 한가지씩 성취를 하는 식으로
위의 스펙 중에 있는 것들중에 집중을 해서 한가지씩 성취를 하는 식으로 접근을 한다고 할 때, 가장 중요하고 시급히 개선이 되야 하는 것을 순서적으로 나열을 한다면 무엇일까 하는 것에 대한 여러분의 의견을 기다립니다.
이유는 스펙의 내용이 점점 커져서 스펙 자체가 완성이 되서 승인을 기다리기란 대퍼+3이 된다고 해도 될까 싶어서 파트별로 분할을 하고 중요도에 따라 단타 위주로 공격을 해볼까 싶어서 입니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
입력기 부분이 아직 결정되지 않은 것 같던데, 먼저 입력 부분이 확실히
입력기 부분이 아직 결정되지 않은 것 같던데, 먼저 입력 부분이 확실히 결정나야 하겠고, 그 다음은 fonts.conf 파일이 될것같습니다.
하드코딩된 백묵글꼴은 사실 큰 문제 아닙니다. 그 부분은 ghostscript에 국한된 문제이며, 은글꼴을 백묵글꼴로 alias하면 그만입니다. 따라서, 은글꼴로 그냥 대체해버리고, 은진체 가족이 기본으로는 못 들어간다 하더라도 fonts.conf에 은진체 설정을 넣어버리면 한글 관련된 설정이 많이 줄어들 것입니다.
(은진체에 비트맵 글꼴이 들어갔으므로 이를 활용하기 위함)
우분투를 자주 쓸 수 없는 상황이라 일단 여기까지 ^^;;
온갖 참된 삶은 만남이다 --Martin Buber
[quote="creativeidler"]한영키 문제를 잠깐 다시 정리하
이 문제는 kbd패키지 및 키보드의 커널부분을 담당자에게 Japanese keyboard관련 문제로 여러차례 메일이 커널 메일링리스트에서 오갔던 것으로 기억합니다만, 커널 2.6이후에 필요하게된 setkeycodes를 사용하는 것이 정답입니다.
예전에는 어떠했는지 잘 기억이 나지 않습니다만 ㅡㅡ;; 모든 키보드모델에 대해서 한영, 한자키의 X11상의 keycode값이 일치하지가 않습니다. 그러므로 xkb를 만들어도 그다지 효용성이 없습니다. 저마다 다른 키보드에 대해서 자동으로 인식하는 키보드 매니져같은게 없는 이상, xkb를 만들어 봐야 무용지물입니다.
구글링해보시면 최근 배포판(FC3)에서도 한영키가 210인 사람, 그리고 그렇지 않아서 고생했다는 사람들이 많이 보입니다.
(각 키보드 모델별로 데이타베이스라도 만들어야 할듯..)
아무튼, 현재 리눅스의 한영키 인식 메커니즘은,
1. 커널에서 한영키를 인식하게 한다 (한영키,한자키 등록: setkeycodes)
2. X11상에서 한영키를 등록한다. (1번이 해결된 후)
3. 커널의 keycode와 X11의 keycode값과는 전혀 무관하다.
온갖 참된 삶은 만남이다 --Martin Buber
[quote="wkpark"][quote="creativeidler"]한
이 문제를 한영키의 인식 문제로만 인식하는 것은 좁은 시각입니다.
커널을 고쳐서 한영키를 인식하게 하는것은 인류 공영에 그다지 이바지 하는 것이 아닙니다.
특수한 키보드나, 다른 아직 알지 못하는 나라의 특별한 키보드를 사용하기 위한 도구를 만들고 그 설정을 제공하므로서 K만 아닌 CJKXXXXX 가 사용할 수 있는 프로그램을 만들어 부트 과정에서 사용하게 하는 것이 보다 적절한 방법이겠지요, 그리고 이런 방법이 프로그램 개발에서 한국에만 매몰되지 않는 방법이구요.
[quote="atie"]위의 스펙 중에 있는 것들중에 집중을 해서 한가
우분투의 CJK LoCo 팀들의 contact들에게서 이 아이디어에 대한 개별적인 동의를 모두 메일로 받아서 이 스펙은 지금 예상하기론 기능별로 쪼개져서 모두에게 중요한 것부터 처리해 나가는 것으로 의견을 모았습니다.
ubuntu.or.kr의 devel buzz에서 우분투 dapper에 가능한 포함을 시키려고 시급히 한글 사용자가 결정해야 할 것에 대한 의견을 모으고 있으니 참여를 부탁드립니다.
그리고, 너무 좋은 의견이 이 곳에 계속적으로 개진이 되고 있고 도움이 많이 됩니다. 계속적인 도움 역시 부탁드립니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
[quote="wkpark"]입력기 부분이 아직 결정되지 않은 것 같던데
스펙은 기능별로 해서 단타로 가자고 우분투 CJK LoCo 팀 간에 연락이 된 후 소강 상태에 들어서기는 했지만, 잠시 일이 진행되는 것을 다시 마음을 다잡고자 적어 놓습니다.
입력기는 우선 scim에 대한 데비안에서의 재 패키징이 진행되고 있습니다. scim-hangul도 0.2.1이 포함되고 중국어나 일본어 입력 관련해서도 개선이 있는 것으로 알고 있습니다. 그리고, 며칠 전에 cwryu님이 nabi와 imhangul을 im-switch 지원이 되는 것으로 올려 주셔서 Dapper의 입력기 쪽은 현재보다는 많이 편해지리라 봅니다. (웬일인지 새 nabi가 아직 우분투 쪽으로 auto-sync 되지 않아 리포팅 해 놓고 기다려 보고 있는 중입니다.)
fontconfig 쪽은 중국팀의 입장은 아직 모르겠고, 일본팀에서는 폰트 자체가 배포판에 넣을 수 없는 상황이라 자체 패키지를 가진다고 하더군요. 하지만 입력기 다음으로 embolden을 포함한 폰트 렌더링과 함께 우선 순위를 갖는 것은 상황 인식이 비슷한지라 어떻게든 진행이 되리라 봅니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
[quote]이 문제는 kbd패키지 및 키보드의 커널부분을 담당자에게 J
글쎄요. 일단 키보드에서 넘어오는 스캔코드 자체를 OS가 인식하지 못하는 것은 키보드 특성과 무관하게 문제가 있는 거라고 봅니다. 발생시키는 스캔코드값을 무시하고 말고는 OS가 결정한다하더라도 말이죠. 그리고 한국에 한한다 하더라도 어쨋든 수많은 사용자가 사용하는 키보드이므로 "특수한 키보드"라고 하기는 좀 무리가 있죠. setkeycodes는 그야말로 특수한 키보드에 대한 편법으로 써야하는 거라고 봅니다.
여기에 대한 의견도 위와 같습니다. 스캔코드값을 읽지 못하는 것과 읽은 것을 무시하는 것은 다른 문제입니다. setkeycodes를 하지 않으면 스캔코드값조차 모른다는 건 거의 버그에 가깝다고 봅니다.
그건 그렇지 않습니다. 자동으로 인식할 필요는 없죠. 키보드를 사용자가 선택하면 되니까요. 제가 알고 있는 대부분의 OS가 설치 시 키보드 종류를 물어보고 선택한 키보드를 인식합니다. '한글 106 key type 1' 이런 식으로 선택하면 한영키가 한영키로 기능하게 하는 것이죠. 이런 건 지금 XKB의 구조상 충분히 가능합니다. 일본은 이미 그렇게 하고 있구요. 보시면 아시겠지만 한국 외에 대부분의 국가가 다 자국의 XKB 세팅을 갖고 있습니다. 그리고 KDE나 그놈에는 이미 키보드맵을 선택할 수 있는 설정이 있습니다.
사실 한국의 키보드는 미국 스타일의 표준(?) 키보드와 가장 가까운 키보드입니다. 프랑스나 독일, 스페인, 이탈리아 어디를 가도 다 자국의 키보드 변형이 있고 그 변형 정도는 한국보다 심합니다. 이런 키보드가 특수한 키보드로 취급 받아서 스캔코드조차 인식 안되는 상황이 전 싫습니다. 머, 어쨋든 이 문제는 제가 시간이 나는대로 대안을 마련해보도록 하겠습니다.
한영키 문제는 리눅스 2.6에서 새로 생긴 커널 버그가 맞습니다.
한영키 문제는 리눅스 2.6에서 새로 생긴 커널 버그가 맞습니다.
드라이버에 보면 키보드 종류마다 스캔코드를 같게 나오도록 하는 테이블이 들어있는데 그 한영키 코드가 있을 자리가 input 레이어로 통합되면서 빠져버렸습니다. 한영키를 세팅할 때 키보드마다 다른 코드로 setkeycode를 해야 하는 이유가 그것이구요.
지금 리눅스용 키보드에서 특정키의 스캔코드가 아예 안 나오는 자국어 자판을 가진 언어는 없습니다.
지금보니까 코드상에 HANGUEL, HANJA 뭔가 따로 처리하려고 하는 코드를 예전에도 본 기억이 있네요. 들여다보다가 잘 모르겠고 개인적으로 쓰지도 않아서 그냥 접었습니다만...
[quote="creativeidler"][quote]이 문제를 한영
스캔코드를 모르는 것이 아니라 해당 스캔코드에서 키코드로 변환하는 테이블에서 키코드가 빠진 것입니다. 스캔코드는 받고 키코드로 변환해주지 않는 것입니다. 이게 버그로 보는 것이 적절하다면 2.6 이후에 10번 넘게 릴리스될때까지 적절한 조치가 취해지지 않은 것은 이상스러운 일이군요.
이 것은 사용자가 키보드를 선택하더라도 문제가 있습니다. 동일한 키보드에 대해서 한영키의 키코드가 다르게 오기 때문입니다. 데비안에과 페도라의 한영키 키코드 값이 다릅니다.
krisna님, 키코드가 다르게 오면 입력기 언어 변경은 어떻게 처리를
krisna님, 키코드가 다르게 오면 입력기 언어 변경은 어떻게 처리를 하시나요? 하드 코드 되었으리라고는 생각하지 않고 어떤 환경 변수와 비교하는 부분이 있나요?
im-switch로 입력기를 바꾸고 입력기가 바뀔 때 위의 환경 변수(?)가 정해지는 식으로 된다면 사용자가 키코드 값을 편집하는 현재의 경우를 피할 수 있게 될 수 있는지가 궁금합니다. 그래도 여전히 사용자가 한 번은 키코드 값을 넣어줘야 하나... 아니면 그 때 스캔코드를 가져와서 변환할 수 있나요 :?
----
I paint objects as I think them, not as I see them.
atie's minipage
[quote="atie"]krisna님, 키코드가 다르게 오면 입력기 언
입력기는 X 서버에서 보내주는 값에 의존하기 때문에 프로그래머 입장에서 보면 키코드 문제와 전혀 관계가 없습니다. XK_Hangul, XK_Hangul_Hanja 키 심벌만 제대로 전달해 주면 입력기는 정상 작동하게 되어 있습니다.
그래서 한글, 한자 키심벌이 제대로 전달되게 하기 위해서 xmodmap을 이용해서 X에서 설정을 하는 것입니다.
[quote]스캔코드를 모르는 것이 아니라 해당 스캔코드에서 키코드로 변
아닙니다. 스캔코드조차 읽지 못합니다. setkeycodes를 하지 않은 상태에서 showkey -s를 하면 스캔코드조차 읽히지 않습니다. 그리고 버그는 관심을 보여주는 사용자가 많아야 수정이 되는 것이죠. 10번 릴리즈 되었다고 리눅스 커널에 버그가 없지는 않잖습니까.
이 문제 역시 다 조정해줄 수 있습니다. 가장 간단한 방법으로는 키보드 세팅을 두 개 만들어서 사용자가 둘 중 되는 걸 고르게 할 수 있죠.
[quote="creativeidler"][quote]예전에는 어
현 자판은 대부분 두벌식이고, 두벌식과 같은 자판은 입력기가 필수이기때문에 xkb와 거의 무관합니다. (일본어 자판과 전혀 다른 스토리입니다. 일본어경우 xkb만으로 어느정도 히라가나를 입력할 수 있습니다.) 물론 세벌식이라면 xkb만으로 입력기를 어느정도 대신할 수 있고요 (첫가끝 자모로만 입력한다면). 여전히 한글 입력기가 있어야만이 원하는 한글음절을 입력할 수 있습니다.
(입력은 초/중/종이나 입력기가 뱉어내는 코드는 초/중/종이 아닌 완성형 한글코드 혹은 유니코드 한글음절 영역입니다)
일본어 자판쪽에선 setkeycode 솔루션 말고 다른 것을 쓰나요? 그쪽을 알아보는게 나을것같군요.
온갖 참된 삶은 만남이다 --Martin Buber
[quote="creativeidler"][quote]스캔코드를 모르는
뭔가를 혼동하고 계신데, 스캔코드에서 키코드 변환 테이블에서 한영전환에 대한 키코드 맵이 빠졌다는 얘기가 스캔코드를 읽지 못한다는 얘기랑 같습니다. setkeycodes는 단지 한영키를 이 변환 테이블에 추가해주는 기능만 할 뿐이죠. 그때서야 비로서 스캔코드를 emit합니다.
한글 키보드만을 위해서 여러개의 키보드 세팅을 둔다? 네, 단 몇개정도의 키보드 세팅이라면 충분히 반영할 수 있을것입니다. 그래서 어떤 형태의 다른 키보드가 있는지를 조사하려 했던 것인데, 얼추 3개 이상의 다른 키코드를 가지는 여러 키보드가 존재합니다. 세팅을 미리 만들어둔다고 해도 일반 사용자들이 그것들을 고르기에는 쉽지않은 형국이 됩니다. 반영되기도 쉽지 않겠죠.
온갖 참된 삶은 만남이다 --Martin Buber
krisna님 답변 고맙습니다.그렇다면, nabi 외에 scim
krisna님 답변 고맙습니다.
그렇다면, nabi 외에 scim 같은 다국어 입력기도 고려를 하고 (한영키와 한자키는 입력기에 관계없이 마찬가지 이겠지만, 다른 언어에 혹 영향이 받는 것이 있다면), GNOME과 KDE 프로그램들도 고려해서 한영키와 한자키의 설정을 관장하는 부분은 커널의 확장판으로 처리를 해야 합니까? 아니면 X에서 해야 하나요? (구글링으로 AIX 쪽을 잠깐 보니 106키에는 두 키 외에도 총 6개의 키심벌을 변환할 수 있어야 하던데.)
위에 나온 이야기들을 정리해서, 배포판에서 다른 키코드가 넘어오고 지금처럼 사용자가 직접 편집하는 것은 개선이 되어야 한다는 전제에서 질문을 드립니다.
----
I paint objects as I think them, not as I see them.
atie's minipage
[quote="krisna"]...이 것은 사용자가 키보드를 선택
설마 그럴리가요. 키보드 한영키문제는 커널 2.6 이후의 문제고,
커널만 같다면 같은 X11키코드가 나와야 정상이 아닌가요?
좀 더 분명하게 확인해야 할 듯.
온갖 참된 삶은 만남이다 --Martin Buber
[quote]뭔가를 혼동하고 계신데, 스캔코드에서 키코드 변환 테이블에서
네, 그건 저도 알고 있습니다. 하지만 전 키코드가 매핑이 안되어 있어도 스캔코드 자체는 별도로 사용자가 알 수 있어야 한다고 생각하거든요. 그래야 최소한 showkey와 setkeycodes를 연동해서 설정 프로그램이라도 만들어 줄 수 있거든요.
윈도우도 보면 키보드 타입 1, 2, 3이 있습니다. 자기 키보드에 안 맞으면 바꿔가면서 사용하죠. 윈도우에서 일반 사용자들이 할 수 있다면 리눅스에서도 할 수 있습니다.
[quote][quote]한글 키보드만을 위해서 여러개의 키보드 세팅을
윈도우 같은경우는 보통 자동으로 세팅됩니다. 적어도 키보드를 판독해서 "자동으로 인식된 키보드는 어쩌고 입니다" 라고 제시해주죠.
또, 키보드 타입 1,2,3중 몇개는 아예 한영키가 없습니다. 조금 스토리가 다른 얘기죠. (한영키가 없는 경우의 키보드도 있는데, 이 글타래에서는 한영키가 아예 없는 경우에 대해서는 간과하고 있습니다)
그래서 이 글타래에 이미 언급되고, 위키페이지도 메모된 내용이 바로 자동 키보드 설정 메커니즘이 가능한지, 한영키 관련된 여러 키보드 정보를 모르려고 하는 것이고요. 그런게 정리가 되어야 비로서 이걸 xkb로 쓰는게 현명한지 Xmodmap을 쓰는게 나은지 자동화된 방법과 어떻게 결합할 수 있는지 등등을 얘기할 수 있을겁니다.
온갖 참된 삶은 만남이다 --Martin Buber
[quote]윈도우 같은경우는 보통 자동으로 세팅됩니다. 적어도 키보드를
제가 윈도우 XP는 설치해보지 않아서 모르겠으나, 윈도우 2000까지의 모든 윈도우 버전은 설치시 키보드 선택 화면이 있습니다. 물론, 말씀처럼 권고안은 제시해줍니다만 최종 선택은 사용자의 몫이죠. 그리고 설치 후에도 바꿀 수 있구요. 그리고 제가 알고 있는 몇몇 사례에 의하면 오른쪽 ALT가 한영키로 동작한다거나 오른쪽 메뉴키가 컨텍스트 메뉴키로 동작한다거나 하는 경우가 있었는데 키보드 타입을 바꿈으로써 해결되었습니다. 리눅스도 그렇게 하자는 게 제 주장입니다. 그리고 지금 스캔코드 문제만 해결되면 XKB 설정만으로 충분히 가능한 상태입니다.
[quote="atie"]그렇다면, nabi 외에 scim 같은 다국
입력기 개발자의 입장에서 이야기하자면, X쪽에서 XK_Hangul 키심이 제대로 넘어오는 것이 중요합니다. 그것만 제대로 작동하면 별 문제가 없습니다.
그런데 문제가 두가지라서, 커널인식의 문제는 윗 분들 말씀을 다 들어봐야 커널 패치가 적절한 것인지, setkeycode를 활용한 설정 프레임웍을 만드는 것이 적절할지 결정할수 있겠습니다.
그리고 그 커널 인식의 문제가 해결되면 X에서 한영키 설정의 문제는 한국용 xkb를 하나 추가하는 것이 어떨까 싶습니다.
제가 앞에서 주장한 내용이 그것입니다. 커널에 스캔코드와 키코드 매핑 테이블을 고정적으로 두는 것보다, 유저 프로세스 레벨의 키보드 설정 도구를 마련하면 여러가지로 유용하게 사용할 수 있을 거라고 판단한 것입니다.
[quote="wkpark"][quote="krisna"]...이
좀더 구체적으로 이야기 하면 커널단에서 오는 키코드와 X에서 사용하는 키코드는 서로 같은 값이 아닙니다. 커널에서 오는 키코드는 동일한데, 이상스럽게도,
X에서 보여주는 키코드값이 다릅니다.
제가 사용하는 데비안 Xfree86에서는 '한/영'키의 키코드로 122가 오고
다른 많은 fedora 사용자들이 리포팅한 것으로는 210이 온다고 합니다.
구체적인 확인과 원인파악이 필요한 것 같습니다.
[quote="krisna"][quote="wkpark"][quote="
x.org와 xfree86의 키코드 체계역시 다른가보군요.
xfree86의 122는 xkb/keycodes/xfree86에 정의된 키코드값이긴 한데 한/영키는 121 한자키가 122라고 되어있습니다.
<FK16> = 121; <FK17> = 122; ... alias <HNGL> = <FK16>; // Hangul Latin toggle alias <HJCV> = <FK17>; // Hangul to Hanja conversion온갖 참된 삶은 만남이다 --Martin Buber
[quote="krisna"]좀더 구체적으로 이야기 하면 커널단에서
제가 기억하기로는 ps/2가 122로 오고 usb가 210으로 왔던것 같습니다. (거꾸로였던가? 요새 기억력 감퇴가;; )
----
데스크탑 프로그래머를 꿈꾸는 임베디드 삽질러
구체적인 자료를 수집하는 것이 필요할 듯 하여, 다음의 설문을 열었습니다
구체적인 자료를 수집하는 것이 필요할 듯 하여, 다음의 설문을 열었습니다.
http://bbs.kldp.org/viewtopic.php?t=68034
----
I paint objects as I think them, not as I see them.
atie's minipage
댓글 달기