파이썬 웹 크롤링질문드립니다.
글쓴이: rladmsxor93 / 작성시간: 목, 2018/01/11 - 3:42오전
from urllib.request import urlopen from urllib.request import HTTPError from bs4 import BeautifulSoup try: html = urlopen("http://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=101") bsobj = BeautifulSoup(html,"html.parser") except HTTPError as e: print(e) try: for headline in bsobj.findAll("ul", {"class" : "slist1"}): print(headline.get_text()) #http((?!\").)* except AttributeError as e: print(e) [OutPut] [신년회견]“소득 3만불 시대 걸맞은 삶의 질, 국민들이 실제로 누려야” 경향신문 부동산 대책은 왜 신년사에서 빠졌나 한겨레 "최저임금 인상이 취약층 위협…靑이 직접 챙기겠다" 매일경제 재계, 대통령 신년사에 "취지 공감…부작용 최소화해야" 연합뉴스 ...이하 생략
저는 경제뉴스파트에 헤드라인과 헤드라인에 해당하는 URL을 크롤해보자합니다.
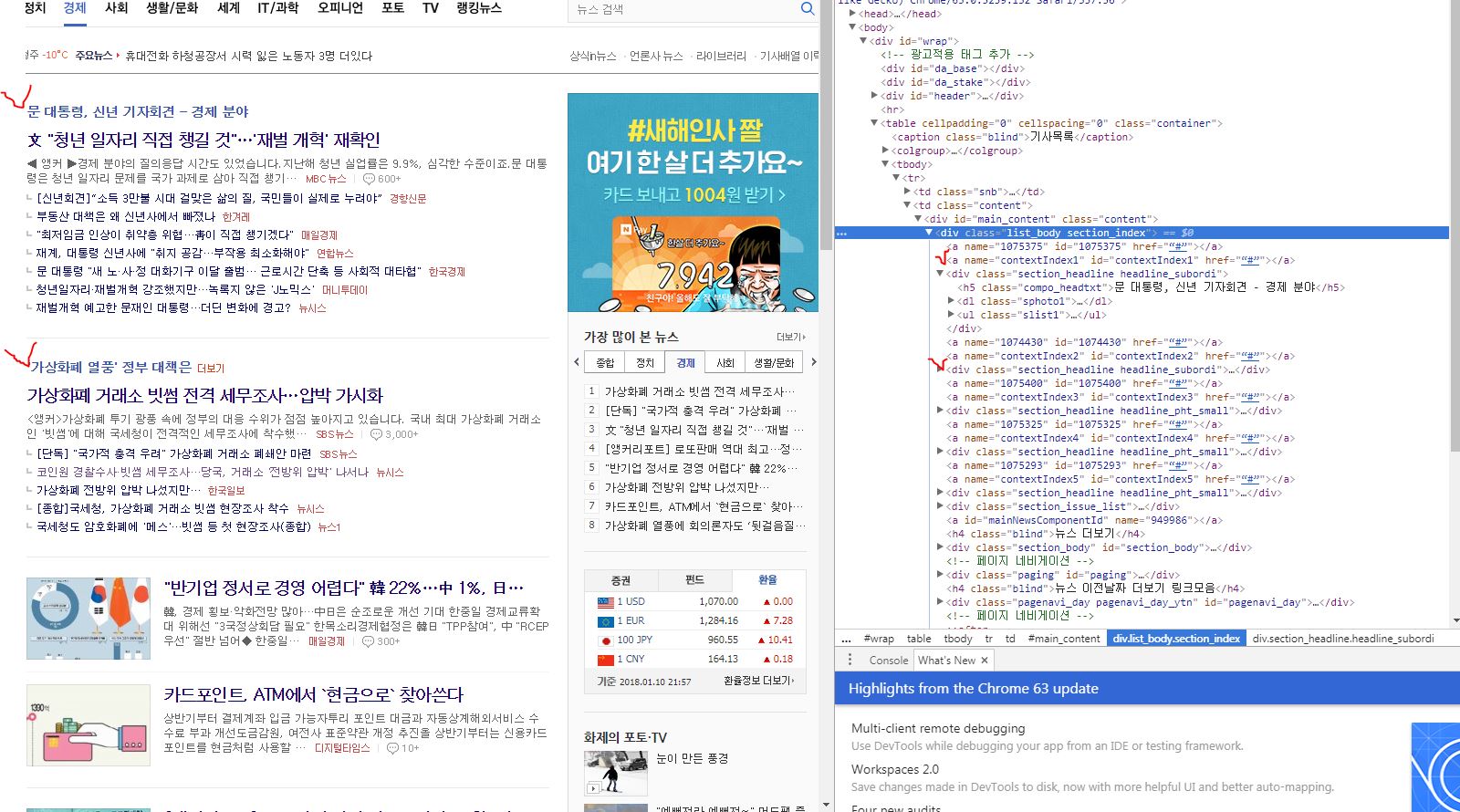
사진을 보시면 윗 영역와 아랫영역 두 부분으로 나뉘는것을 확인하였습니다. findAll메소드로는 해당 소스처럼
헤드라인 제목만 추출이 됩니다.
하지만
for headline in bsobj.find("ul", {"class" : "slist1"}).findAll("a"): print(headline.get_text() + headline['href']) [OutPut] [신년회견]“소득 3만불 시대 걸맞은 삶의 질, 국민들이 실제로 누려야” http://news.naver.com/main/read.nhn?mode=LSD&mid=shm&sid1=101&oid=032&aid=0002843388 부동산 대책은 왜 신년사에서 빠졌나 http://news.naver.com/main/read.nhn?mode=LSD&mid=shm&sid1=101&oid=028&aid=0002394293 "최저임금 인상이 취약층 위협…靑이 직접 챙기겠다" http://news.naver.com/main/read.nhn?mode=LSD&mid=shm&sid1=101&oid=009&aid=0004081175 ..... 이하 생략
for문을 이렇게 바꾸면 윗영역만 헤드라인과 해당 URL을 크롤할 수 있었습니다.
제가 하고싶은건 두 부분다 헤드라인 + URL을 추출하고싶은데 어찌해야 할지 모르겠습니다. html개발자 모드열어서
접근 방법을 다양하게 시도도 해보고 정규표현식으로도 해보았지만 시작한지 얼마 안되어서 감이 잘 안잡히네요.
이럴땐 어떻게 해야 되는지 알려주실 수 있나요?
뉴스 출처 : http://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=101
File attachments:
| 첨부 | 파일 크기 |
|---|---|
| 303.47 KB |
{kind=link}
Forums:
find대신 findAll을 사용해서
이렇게 하면 됩니다.
감사합니다!!!
잘 작동되네요 ㅎㅎ
어떤식으로 해야될지 감이 잡혔습니다!
댓글 달기