[완료]Memory의 실제 논리적 구성과 실제 addressing의 차이점이 궁금합니다.
글쓴이: nicemuy / 작성시간: 수, 2012/05/16 - 2:06오전
제가 요새 하드웨어 공부를 하게되면서 Memory의 구조를 스치듯(?)이 보았는데, 상당히 이해가 안가는 점이 있어서 질문남겨 봅니다ㅠㅠ
우선은 제가 본 메모리의 대략적인 구조 그림이 아래와 같은데요...
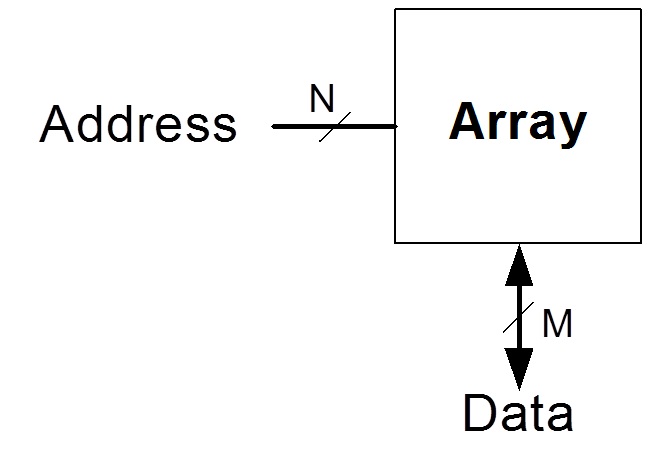


이것이 32bit 컴퓨터에서는 address라인과 data라인이 전부 32bit라고 합니다. 여기서 제가 궁금한점이, 그림에 따르면 32bit 컴퓨터에서 address가 0x00 00 00 00에서 data를 실제 32bit를 읽어오고 0x00 00 00 01에서도 data를 32bit 읽어오고 이렇게 되야하는데,
실제 고급언어로 프로그래밍할때 int A[2]; 라는 정수형 배열의 주소값이 A[0] = 0x00 00 00 00 이고 A[1] = 0x00 00 00 04 라는 사실이 저를 너무 괴롭게 합니다...ㅠ(int가 4바이트라고 했을시) 한 주소값에서 32bit를 한번에 읽어 올 수 있으면, 당연히 A[0] = 0x00 00 00 00
이고 A[1] = 0x00 00 00 01이어야 되는것 아닌가요?? 그러나 실제 프로그래밍을 해보면 사실상 주소값하나에 마치 1바이트만 읽어오는 듯이 보이는데, 이게 왜이런지 도무지 모르겠습니다...!
{kind=link}
{kind=link}
{kind=link}
Forums:
1byte 가..
address 단위는 1byte 가 맞습니다.
data line 이란건 "한번에 전송 가능한 data크기" 일 뿐입니다.
따라서 실제주소 0x00 00 00 00 에서 읽게되면 0x00 00 00 00 ~ 0x00 00 00 03 까지 읽을 수(!) 있는것이고, 어디까지를 프로그램에서 사용할 지는 그 다음 문제지요.
data line의 크기가 중요한건 프로그램의 효율 또는 속도 문제가 걸려있기 때문인데, 만일 data line이 1byte 라고 하면, 32bit을 읽기 위해서는 4번 읽어야하니까.. 이미 속도가 4배 차이 나게 되죠. (32bit 머신에 비해서..)
최근 프로그램들은 기본적으로 처리하는 data단위가 커지니까 64bit data 처리를 하는 CPU와 그 주변부로 넘어가고 있는 중이구요..
제가 알고있던게...
맞는거군요...! 답변 감사합니다
댓글 달기