올릴까 말까 고민하다가... 이런건 스스로 해야하는데..
입사하고 처음으로 제대로된(?) 프로젝트를 하나 진행하고 있습니다.
지금은 설계가 막 끝나고 구현을 들어가는데.. 어디서 부터 어떻게 해야할 지
막막하네요...(벌써 기일의 반이 지났는데..)
역시 학교에서 하는 프로젝트(이론 구현위주의..)와 실무 프로젝트는
그 차이가 예상했던 것 보다 큽니다......ㅠ.ㅜ
그냥 고수분들의 의견을 듣고 싶습니다. 이런 설계가 매끄러운지...
혹 불가능하거나 구현하기 애매한 부분은 없는지....
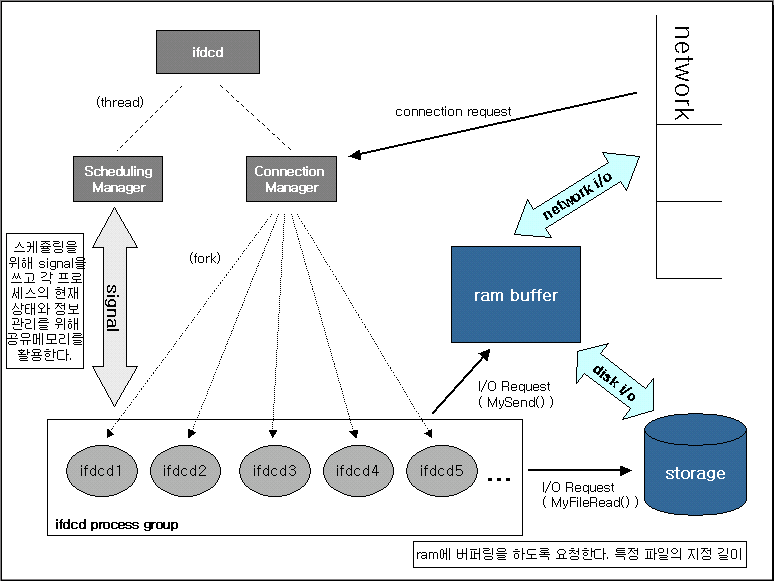
우선 아래 그림을 먼저 봐주세요...
기존의 파일 서버의 데몬에서 스케쥴링(?) 기법을 적용시키는 작업입니다.
이렇게 하는 이유는 네트웍 I/O 로드와 디스크 I/O로드를 어느 정도 분산시키고자
함인데요, 그 방법으로서 이런 구상을 했습니다.
최초의 프로세스에서 ConnectionMan이라는 쓰레드와 SchedulingMan쓰레드
이렇게 두 개를 추가로 만들어서, ConnectionMan은 계속 Accept 하고
Scheduling 쓰레드는 시그널 혹은 IPC (어떤기법이든지) 를 이용하여
스케쥴링 하는 것입니다.
스케쥴링의 대상은 물론 ConnectionMan에서 포크된 자식 프로세스집단입니다.
스케쥴링의 목적은, 다시 말씀드리다시피 I/O로드 분산이며,
그 구체적인 방법은..
1. 디스크 I/O를 일부 프로세스 그룹에게 제한하여 램버퍼에 버퍼링을 시킨다.
2. 그 작업이 끝나면 뒤이어 다른 프로세스 그룹들이 또 버퍼링을 한다...
3. 그렇게 버퍼링이 되는 동안 버퍼링이 이미 끝난 프로세스는 네트워크 I/O를 수행하도록 한다.
입니다.
기본적인 아이디어는 이런데..
좀 길었나요... 흠... 어떻게 생각하면 간단한 구조인데..
제가 실무 프로젝트는 처음이라 어떤 방법이 가장 효율적일지 명쾌한 답이
떠오르지 않네요.
가장 고민스러운 것은 스케쥴링시에 어떤 수단을 쓰느냐 입니다.
프로세스들의 큐를 만들것인지...
또 그것은 공유메모리를 사용해서 구현해야 할 듯 한데, 그것이 쉬울지...?
(프로세스 간의 동기화가 장난 아닐것 같은데..)
아니면 기타 다른 효율적이고 간단한 방법이 있을 것인지.....
여튼 지금 매우 복잡난감합니다.
구원의 손길을 내밀어 주소서........ ㅜ_________ㅜ
| 첨부 | 파일 크기 |
|---|---|
| 18.51 KB | |
| 22.45 KB |
{kind=link}
{kind=link}
저의 개인 정보를 잠시 눌러보고 icristi님이 쓴 모든 글 조회하기
저의 개인 정보를 잠시 눌러보고 icristi님이 쓴 모든 글 조회하기 버튼을 눌러보니까.. 역시나 전부다~~~ 질문 뿐이더라구요...ㅠ.ㅠ
답변해주신 모든 분들 복받으실거구요...
저도 얼렁얼렁 배워서...
갈고 닦은 것 KLDP에 환원할 수 있길 바랍니다...^__^
..
네트웍 I/O 로드와 디스크 I/O로드를 분산시키는 스케쥴링이라 하셨는데
내용을 곰곰히 읽어보니..결국은
모든 프로세스 그룹은 네트웍 I/O가 동시에 가능하지만.
특정 프로세스 그룹만이 디스크 I/O 를 할 수 있도록 하는
스케쥴링을 하려는 것 같습니다. 결국 디스크 I/O관리를 통해
네트웍 I/O와 디스크 I/O의 로드를 조절하는 셈이 될것이라 이해했습니다만..
이러한 알고리즘으로는 세마포어가 있습니다.
특정 프로세스 그룹에게만 디스크 I/O 권한을 부여하면 될 것
같습니다.
틀린점이 있다면 지적해주세요.
IO 로드의 분산의 개념이 무엇인지 설명해주세요.
네트웍 I/O 와 디스크 I/O 를 분산하려고 하신다는 말씀을 하셨는데, 이 말의 개념이 무엇인지 좀더 구체적으로 설명을 해주세요. 로드를 분산을 하려는 목적과 함께...
일반적으로 FTP 서버나 보통의 파일 서버의 데몬들은 클라이언트로 부터
일반적으로 FTP 서버나 보통의 파일 서버의 데몬들은 클라이언트로 부터 DownLoad 요청이 들어오면 While 문 안에서 일정 길이의(일반적으로 수십에서 수백킬로바이트) 바이트 스트림을 디스크로부터 읽어 소켓으로 보내게 되는 과정을 반복합니다. 즉, while문 안에서 DISK I/O와 NETWORK I/O가 반복적으로 (거의)동시에 일어나는 것이죠.
이런 테스크들이 200~300개로 늘어날 경우에 DISK I/O나 NETWORK I/O는 서로 간에 좋지 않은 영향을 줄 수도 있다는 가정을 해봅니다. 구체적으로, 과다한 트래픽 로드가 발생할 시에 어느 하나의 디바이스가 블럭 상태나 지연이 발생하면 다른 하나의 디바이스는 효율적으로 그 Capacity를 전부 활용할 수 없다는 예상을 해볼 수 있다는 것입니다.
이런 가정을 출발점으로 해서 개선의 여지를 모색한 것이죠..
제가 위에 '분산'이라는 용어 선택을 아무래도 잘못 선택한 듯 싶은데요. 일반적으로 분산시스템에서의 '분산' 혹은 로드 밸런싱의 의미의 '분산' 이라기 보다는 각각의 I/O 를 [개별적]으로 수행하고 싶은 것입니다.
즉, 하나의 프로세스를 기준으로 일정 순간에 DISK I/O를 모두 끝내고, Disk I/O가 모두 끝나면 이제 NET I/O 수행 하는 것이죠. 물론 중간에 임시 저장 공간은 램버퍼를 이용하게 되겠지요.
이런 기본적인 아이디어가 있습니다.
하지만 구체적이고 실무적인 (?) 구현에 익숙하지 않은 저로서는 이게 참 난감합니다. SchedulingMan이라는 스케쥴링 쓰레드를 만들긴 하였으나, 이것으로 부터 어떻게 프로세스 집단을 스케쥴링 하도록 구현할 것인가.... 즉, 어떻게 이놈 이놈들은 빨리 Disk I/O를 이만큼 끝내라(램버퍼로) 그리고 이놈은 끝났으면 또 다른놈 와서 해라... 그리고 다 끝난 놈은 NET로 쏴서 램버퍼 빨리 비워라..
라고 알려주고 통신할 것인가?? <--가장 큰 관건!
위에 세마포어 말씀하셨는데 그 방법도 정말 괜찮은 것 같아요. 하지만, 추가적인 공유 정보를 가지고 있어야 하는데 그 구현을 어떻게 할지가 또 하나의 난관이라는 것입니다.
예를 들어 몇 개의 프로세스가(프로세스당 100MB~700MB파일) DIsk I/O를 끝내려면 램버퍼가 적어도 2G(가정) 이상이 필요하니까 이것은 불가능하므로 적절하게 어느 정도만 끝내고 빨리 NET I/O 해서 램버퍼를 비워야 하겠죠. 또 이때 램버퍼 비워지면서, 다른 프로세스 집단에 DISK I/O하면서 램버퍼링하는 과정을 유도하고 하겠죠. 그러는 동안 어느 정도까지 파일을 읽었는지 각 프로세스마다 정보가 필요하겠죠. 그런 정보를 스케쥴러가 알아야하니까 공유되어야 함은 물론이고, 그것을 어떻게 동기화 일일이 시킬 것인가가 문제죠.
또 다른 문제는 너너 DISK I/O해라 너너 NET I/O 해라 라는 지시를 어떤 매커니즘으로 알려줄 것인가(Signal?) 라는 고민이 또 하나입니다.
참 난잡하죠?
일단 여기까지 이야기 했는데.. 더 헷갈려진 것 같네요.
Common Sense 한(?) 설계와 구현이 아닌 듯 해서, 여러분들의 관심이 있을 지는 모르겠습니다. 그래도 최대한 충고해주실 부분 충고해 주시고, 이건 아니야 라고 생각하시는 부분도 가차없이 말씀해주시면 정말 너무너무 감사하겠습니다.
긴글 읽어주셔 감사합니다 ^_______________^
[quote="icristi"] 이런 테스크들이 200~300개로 늘
현재 시도하시는 프로젝트가 서버의 퍼포먼스를 향상시키기위한 시도라고 가정을 하고 말씀을 드릴께요.
결론부터 말씀드리자면 드라이버/디바이스의 관점에서 볼때는 "과다한 트래픽 로드"가 걸릴수록 드라이버/디바이스가 가진 잠재적인 성능을 모두 끌어낼 수 있습니다. 왜냐하면 그만큼의 로드가 걸리지 않았다면 I/O 를 끝내고 쉬어야만 하므로 디바이스의 측면에서 보면 최대한 활용되지 않은 셈이거든요. 특히 블록디바이스의 경우, 미디어가 회전하고 자기 헤드가 움직이는 기계적인 요소를 가지고 있으므로, 동시에 여러개의 I/O request 가 수행되고 있을 경우 드라이버/디바이스가 이 I/O 를 reordering 함으로써 순차적으로 I/O request를 수행할때보다 훨씬 더 빠르고 효율적으로 I/O를 수행할수 있거든요.
첨부하는 그림은 보통 서버프로그램을 NetBench 나 ServeBench 등의 프로그램을 돌리면 얻을수 있는 통상적인 그래프입니다. 이것을 보시면 아시겠지만 초반에는 클라이언트수의 증가에 따라 성능도 선형적으로 증가를 합니다.
반면 클라이언트수가 일정 숫자를 늘어나면 오히려 성능이 조금씩 감소하는데, 이는 서버가 수행되고 있는 하드웨어의 부족한 자원위에서 지나치게 많은 프로세스가 수행될때 발생하는 thrashing 현상입니다.
클라이언트수에 따라 프로세스가 증가하면서 발생하는 thrashing 현상을 근본적으로 막는것은 불가능하다고 알고 있으며, 프로세스의 수를 줄이고 asychronous I/O 를 쓰거나 하는등으로 소극적인 대처방법을 쓰는것으로 알고 있습니다.
유저레벨의 프로그램에서 IPC 등을 써서 프로세스 스위칭을 하면 thrashing 문제가 오히려 악화될것 같은 생각이 듭니다. 또한 유저모드에서 대용량의 버퍼를 할당해서 lock 하거나 mmap 을 쓰거나 한다면 커널에서 사용할 수 있는 자원이 줄기 때문에 오히려 역효과가 나지 않을까 합니다.
* 참고로 일반적으로 밸런스가 잘 맞춰진 시스템에서는 항상 블록디바이스가 병목의 원인이 되는것이 보통입니다.
[quote="hb_kim"]현재 시도하시는 프로젝트가 서버의 퍼포먼
물론 그렇습니다.
Thrashing 에 대한 개념은 재학 시절 OS 시간에 들어서 익히 알고 있습니다. Degree of MultiProgram 과 CPU Utilization의 상관관계 그래프가 아래의 그림과 비슷한 것을 볼 수 있었습니다. 오랜만에 들어보니 새롭네요^.^
저도 이런 시도가 퍼포먼스의 향상에 증가를 줄 수 있을지의 명확한 근거를 짜맞춰 볼 수가 없습니다. 이 아이디어는 제 머리속에서부터 나온 것도 아니며(팀장님의 직감에서의 오더), 따라서 제 자신부터 이 프로젝에 대한 확신이 없습니다. 하지만 위에서 떨어진 오더니 안할 수는 없으니까요. 개인적으로 되든 안되는 재밌을 것 같구요.
아! 그리고 이렇게까지 자세한 답변이 너무 황송합니다~
감사드립니다.
댓글 달기