C++, 정렬할 때 메모리 문제
C++을 이용해서 대용량 csv파일을 정렬하고자 합니다.
(cpu 12개, 메모리 약 100기가)
예를 들어서 2001년~ 2012년에 해당하는 데이터를 정렬하려고
각 core에 1년치 데이터를 할당해서 sort 작업을 진행하려고 합니다.
1년에 해당하는 데이터는 (100,000~10,000,000 x 15) 로 이루어져있고
숫자와 문자 모두 포함하고 있습니다.
ex)
12351256, 29839182, GB00DJM120, 1, 3, ... , OG0189290
12353456, 29835631, GB00DJ2153, 2, 4, ... , OG018HJJD
...
...
12345731, 29832131, GB00GL1023, 4, 1, ... , OG01AFDG1
이 데이터를 1열, 2열, 3열, 4열 순서로 정렬을 하려고 합니다. (5 ~ 15열은 뒤에 따라오는 데이터)
아래에 있는 코드는 두 개의 열을 정렬하는 것인데 이 방법을 확장해서 15열로 만들었고(string string1, string2, ..., string15)
두 개의 열을 비교하는 것이 아니라 4개의 열을 비교하도록 만들었습니다.
아래 코드는 2001 한해를 정렬하는 코드이고 이런 코드가 12개가 있어서
각각 컴파일 해서 백그라운드로 12개를 동시에 돌렸습니다.
그런데 코드를 돌리다보니까 리눅스에서 자체적으로 프로그램을 종료 시켜버렸습니다.
아래와 같은 정렬 코드가 메모리를 많이 차지하기 때문이라고 생각하는데 (메모리에 관련된 에러 메세지가 나왔습니다)
이 문제에 대한 아이디어나 메모리를 적게 차지하는 정렬 알고리즘을 알려주시면 감사하겠습니다.
cf) 위에 말씀드린 것은 시간이 오래 걸리지 않아서 동시에 처리하지 않고 하나씩 순차적으로 처리하면 금방 끝나지만
실제 데이터는 이것보다 복잡해서 12개를 동시에 돌렸을 때에 대한 해결 방안이 궁금합니다!
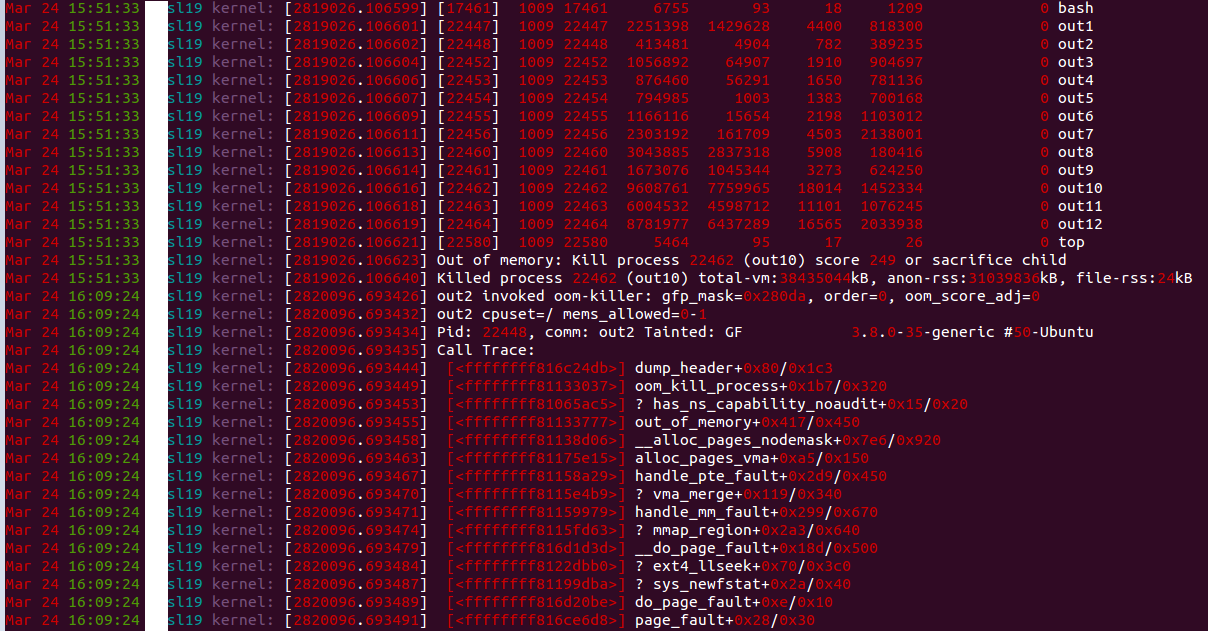
+ 첨부한 사진은 /var/log/kern.log 일부분을 캡처한 것 입니다.
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <algorithm>
#include <iterator>
using namespace std;
// class for sort
class sort_class
{
private:
string string1, string2;
//string string1, string2, string3, string4, string5, string6, string7, string8;
//string string9, string10, string11, string12, string13, string14, string15;
public:
sort_class(const string& init_string1, const string& init_string2);
friend int Compare_By_string1(const sort_class& lhs, const sort_class& rhs);
//friend int Compare_By_string1234(const sort_class& lhs, const sort_class& rhs);
friend ostream& operator<<(ostream& os, const sort_class& obj)
{
os<<obj.string1<<','<<obj.string2;
return os;
}
};
sort_class::sort_class(const string& init_string1, const string& init_string2)
:string1(init_string1), string2(init_string2){}
// function that sorts by string1, 2개 열을 정렬
int Compare_By_string1(const sort_class& lhs, const sort_class& rhs)
{
return (lhs.string1<rhs.string1);
}
// 4개 열을 정렬
/*
int Compare_By_string1234(const sort_class& lhs, const sort_class& rhs)
{
if(lhs.string1==rhs.string1)
{
if(lhs.string2==rhs.string2)
{
if(lhs.string3==rhs.string3)
{
return (lhs.string4<rhs.string4);
}
else if(lhs.string3!=rhs.string3)
{
return (lhs.string3<rhs.string3);
}
}
else if(lhs.string2!=rhs.string2)
{
return (lhs.string2<rhs.string2);
}
}
else if(lhs.string1!=rhs.string1)
{
return (lhs.string1<rhs.string1);
}
}
*/
int main()
{
// read 2001.csv file and put them into the test_vector
ifstream file("2001.csv");
vector<sort_class> test_vector;
string string1, string2;
while(getline(file, string1,',')
&&getline(file,string2,'\n'))
{
test_vector.push_back(sort_class(string1,string2));
}
file.close();
// sort the test_vector by string1
sort(test_vector.begin(), test_vector.end(),Compare_By_string1);
// write the sorted test_vector on out_2001.csv file
ofstream fout("out_2001.csv");
std::ostream_iterator<sort_class> output_iterator(fout,"\n");
std::copy(test_vector.begin(),test_vector.end(),output_iterator);
fout.close();
return 0;
}| 첨부 | 파일 크기 |
|---|---|
| 252.56 KB |
{kind=link}
메모리가 모자라서 OOM killer가
메모리가 모자라서 OOM killer가 떴네요.
일단 숫자만 존재하는 열은 string으로 사용하시기보단 적절한 범위의 정수형을 사용하시길 추천드립니다. string 내부에 동적 메모리 할당이 수반되고, 정수형 비교가 string의 lexicographic 비교보다 훨씬 빠릅니다.
이 정도의 대용량 데이터를 정렬하시려는거면 직접 처리하시는것보다 DB를 사용하는게 어떨까요? csv면 db로 import하기도 어렵지 않을거고, 퍼포먼스도 직접 짜시는것보다는 훨씬 나을 것으로 예상합니다.
제가 DB를 잘 몰라서 그러는 걸 수 도 있는데..
제가 DB를 잘 몰라서 그러는 걸 수 도 있는데.. 정렬을 하면서 중간중간에 계산을 해야 해서 DB 사용은 어려울 것 같습니다.
kukyakya님 말씀대로 string을 간단한 자료형으로 바꿔서 돌려보겠습니다. 감사합니다!
...
"대용량 csv"라 하심은 대략 몇 MB 정도를 뜻하는 건가요?
100 MB ~ 2000MB 정도까지 다양하게
100 MB ~ 2000MB 정도까지 다양하게 있습니다. 빅데이터 하시는 분들에게 대용량이 아닐 수도 있습니다..
용량이 커야 2GB 인데 그걸 12개 돌렸을 때, 100GB 메모리를 가진 컴퓨터에서 OUT OF MEMORY가 나오는 이유를 모르겠습니다.
External sorting을 알아보세요.
https://en.wikipedia.org/wiki/External_sorting
코딩이 조금 번거롭습니다. 하지만 그렇게까지 어렵지는 않고, 일단 짜 놓으면 잘 돌아갑니다.
자주 해야 할 일이라면 MapReduce 같은 걸 검토해 보셔도 좋습니다. 물론 초기비용이 크죠.
이런 방법이 있었군요. External
이런 방법이 있었군요. External Sorting이랑 MapReduce 한 번 시도해 보겠습니다. 감사합니다!
100GB 메모리에 2GB 데이터라... 이 정도
100GB 메모리에 2GB 데이터라...
이 정도 규모를 생각하고 드린 답변은 아닌데요.
제시해드린 방법은 정말로 싱글노드 메모리엔 도저히 안 들어가는 규모의 데이터를 다룰 때나 쓰는 방법입니다.
선택이야 질문자님 몫이지만, 지금 알려주신 규모로는 왜 메모리 부족 문제가 생기는지 알 수 없겠는데요.
그렇군요.. 위에 나온 방법대로 해도 24 GB (2
그렇군요.. 위에 나온 방법대로 정렬해도 24 GB (2 GB x 12) 이상의 메모리를 사용하지 않는다는 말씀이시죠.
혹시나 예시로 든 코드가 24 GB 이상의 메모리를 비효율적으로 사용하는 것이 아닌가 해서 질문을 드렸었습니다.
원래 코드에는 sort만 하는 것이 아니라 다른 계산들도 해서 메모리를 잡아먹을 수도 있을 것 같습니다.
메모리가 부족한 이유에 대해서 더 생각해 보겠습니다. 감사합니다.
...
혹시 memory leak이 있을지도 모르니 일단 100줄 정도 되는 장난감 csv를 만들어서 valgrind로 돌려보시는 것이 어떨지...?
프로그램이 돌아가고 있을 때 top으로 봐서 실제로 메모리를 얼마나 잡아먹고 있는지 확인해 보는 것도 좋겠는데요. 정작 문제는 엉뚱한 프로세스일 수도 있으니. (뭔가 top보다 더 좋은 명령이 있을 것 같은데 제가 잘 몰라서..)
100MB라면 파일을 통째로 vim으로 열어서 :%!sort 하면 몇 초 내로 결과가 나오는 정도의 크기입니다.
valgrind라는 툴이 있었군요. 말씀하신 툴을
valgrind라는 툴이 있었군요. 말씀하신 툴을 써서 메모리 누수를 체크해 봐야겠습니다.
프로그램이 돌아가고 있을 때도 확인해 봐야겠고..
많은 도움이 될 것 같습니다. 감사합니다!
std::string의 메모리 사용량
많은 수의 문자열을 다룰 경우,
std::string은 공간 효율적이지 않을 수 있습니다. 예를 들어, "GB00DJM120"는 10 개의 문자로 이루어져있지만, 지역 변수std::string s("GB00DJM120")는 GCC 5.2.0에서는 총 32 바이트(스택 32 바이트 + 힙 0 바이트), GCC 4.9.2에서는 총 43 바이트(스택 8 바이트 + 힙 35 바이트)를 차지합니다.따라서, 숫자 컬럼은 정수형에 저장하고 문자열 컬럼은 각각의 컬럼 폭(N)에 맞는 문자 배열(char[N] 혹은 char[N + 1])에 저장하면 메모리 사용량을 꽤 줄일 수 있을 듯 합니다. 실제 데이터도 보여주신 예제 데이터에서처럼 숫자 컬럼은 정수형에 충분히 들어갈 수 있는 크기이고 각각의 문자열 컬럼은 저마다 그 폭이 일정하다고 가정했습니다.
GCC 버전을 확인 해 보니 4.8.4라서 더
GCC 버전을 확인 해 보니 4.8.4라서 더 비효율적으로 사용하고 있었던거 같습니다. 게다가 확인해 보니 메모리 누수까지..
말씀하신대로 데이터 컬럼 당 폭이 일정해서 문자배열과 정수 자료형을 사용해서 메모리를 효율적으로 사용해야 할 것 같습니다. 답변 감사합니다!
감사합니다.
감사합니다.
컴의 메모리가 100G라도 어플이 요구한다고 100G
컴의 메모리가 100G라도 어플이 요구한다고 100G 모두가 할당되는 것이 아닙니다.
어떤 OS로 최대로 어플에 할당할 수 있는 양은 정해져 있는데 구글에 검색해 보시면 특정 API 등을 써서 최대 할당량을 변경해서 한계를 초과해서 메모리를 할당하는 방법을 찾으실 수 있을 겁니다.
오.. 어렵기도 하고 신기하네요 API라는 것도
오.. 어렵기도 하고 신기하네요 API라는 것도 공부해 봐야겠습니다. 감사합니다!
http://lovekmg.blogspot.kr/2008/08/api%EB%9E%80.html
댓글 달기