점보 프레임 세팅 관련 의문
안녕하세요. 저는 대학원에서 수치연산 시뮬레이션을 하고 있는 대학원생입니다.
노드가 26개인 클러스터 서버를 관리하고 있습니다.
큰 수치연산을 mpi를 이용하여 자잘하게 쪼개서 돌리는 일을 해야 합니다.
별 다른 문제 없이 잘 돌아갑니다. mpi세팅도 잘 되었고, 결과값에도 문제가 없습니다.
문제는, 이 연산을 돌릴 때 mpi때문에 생기는 커뮤니케이션 코스트가 너무 크다는 겁니다.
전송하는 데이터량은 그렇게 많지 않고, 기가빗 랜을 쓰고 있기 때문에 대역폭 문제는 없는 것 같습니다.
문제는 레이턴시인데요. 패킷 하나 보내는데 밀리세컨드 단위로 시간이 걸립니다.
헌데 각 통신간 시간 간격이 밀리세컨드 단위입니다.
즉, 모든 노드가 (1) 1밀리세컨드 수치연산하고, (2) 패킷 쏘고 받아서 필요한 데이터를 얻는데 1밀리세컨드가 걸립니다.
1밀리세컨드 계산하고 1밀리세컨드 기다리고... 이짓을 계속 반복하는 것 같습니다.
큰 시뮬레이션이고, 알고리즘을 고칠 여지는 없습니다. 8코어 머신(4코어*2)이기 때문에 한 머신으로만 돌리면
커뮤니케이션 코스트가 거의 없어져서 (같은 머신으로 패킷을 쏘니까요) 빨라지긴 합니다만, 늘 이렇게 돌리기엔
컴퓨터 댓수가 많이 부족합니다.
네트웍 하는 친구(대학원생)한테 물어보니, 한 컴퓨터가 패킷을 쏘아 다른 컴퓨터가 패킷을 받는데 걸리는 시간은
마이크로세컨 단위라고 합니다. 1/1000이죠. 그런데 레이턴시가 1마이크로세컨이 아니라 1밀리세컨인 이유는,
패킷을 쏠 때에 os가 네트웍 최적화를 위해(?) 패킷을 바로 안쏘고 좀 버벅대기 때문이랍니다. 같이 쏠 수 있으면
뭉쳐서 쏘려고 기다리는거래요. 그래서 점보 프레임이라는걸 잘 세팅해서 내가 패킷을 쏜다고 하면 os가 다른 패킷 쏘는거
기다리지 않고 바로 쏘도록 만들 수 있고, 그럼 네트웍 레이턴시를 줄일 수 있다고 합니다.
그래서 점보 프레임을 세팅하려고 인터넷 문서를 뒤지고 있는데, ... -_-;; 반대 경우만 나오는 것 같네요. 저는 패킷 사이즈에
상관없이, 아무리 작더라도 패킷을 바로바로 쏴주길 원하는데, 점보 프레임이라는거는 패킷을 쪼개지 않고 뭉쳐서 쏘는
개념이라고 하는군요...
질문입니다.
1. 네트웍 레이턴시를 극한으로 줄이는 일이 가능합니까? 현재 1ms-10ms정도고, 저는 1us정도로 줄이길 바랍니다.
2. 점보 프레임을 써서, 혹은 랜카드 설정을 잘 해서 패킷을 바로바로 쏠 수 있도록 하는 일이 설정 가능한것인가요?
즉, 점보 프레임을 이용해서 질문1을 실현할 수 있습니까? 아니면 무슨 커널 패치라도 해야 합니까?
3. 이런 일이 가능하다고 했을 때, 대역폭에서 손해를 보게 될텐데, 얼마나 손해를 보게 됩니까? 같은 네트워크에 매우
바쁜nfs가 물려 있다고 하면 얼마나 손해를 보게 될까요?
4. 이러한 일을 제대로 알아보기 위해서는 어떤 키워드로 문서를 검색해서 읽어야 합니까?
고맙습니다.
InfiniBand 네트워크// InfiniBand 스위치// 1 microsecond(µs) Latency 성능
댓글이 마치 특정 제품의 Brand를 홍보나 광고하는 것처럼 되어버려서 유감스럽지만, 아래와같이 검색결과가 도출되었습니다. 그런데, 저는 아래에 언급된 회사들과는 아무런 상관이 없는 사람입니다.
===================================================================================
Cisco Nexus™ 5000 Series 는 10 Gigabit Ethernet switches 이고, Latency 가 최고 3.2 µs 이하의 성능이 나온답니다.
===================================================================================
InfiniBand 는 QDR(Quad data rate)일 경우 40 Gigabit(Gbit/s) interconnect per adapter ( 26Tb/s QDR InfiniBand 324 port Chassis Switch )일 때, Latency 가 최고성능으로 1.07 µs MPI latency 성능이 나온다네요. --- "제품의 사양에 따라서" 1.07 에서 2.6 µs의 MPI latency 성능이 나온답니다.
Switch (필요하면 Gateway까지도...) 뿐만 아니라, QDR InfiniBand Adapter Card 가 PCI Express 2.0 (PCIe 2.0 Bus) 사양이니,,, 서버("메인보드")도 교체가 이루어져야 할 것 같습니다만...!
참고로, InfiniBand 분야에서는 Mellanox사 제품이 마치 산업표준 처럼 유명한 것 같습니다.
===================================================================================
저도 이 분야에 아주 오랜 과거부터 관심은 있었기 때문에(그러나, 직접적으로 이 분야에 종사하고 있지는 않습니다.),,, 1 Gigabit Ethernet(LAN) 사양에서 소프트웨어적으로 설정을 변경하여 network latency를 1 microsecond 성능으로 바꾸는 방법을 찾아보고 있지만 아직 찾지는 못했고, 상기의 경향성으로 보아서는,,, "하드웨어에 대한 전면적인 투자"가 선행되어야..... 한자리 수의 마이크로세컨드(µs) 레이턴시 성능을 구현할 수 있을 것 같습니다.
* 아래 Link들을 참고하십시요. *
* Cisco Nexus 5020 Switch Performance in Market-Data and Back-Office Data Delivery Environments
http://www.cisco.com/en/US/prod/collateral/switches/ps9441/ps9670/white_paper_c11-492751.html
http://www.ciscosystems.com/en/US/prod/collateral/switches/ps9441/ps9670/white_paper_c11-492751.pdf
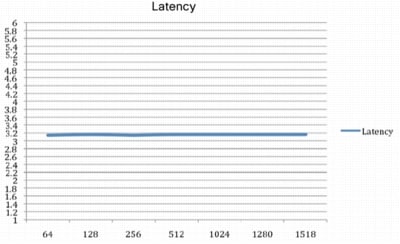
The Cisco Nexus™ 5000 Series 10 Gigabit Ethernet switches,.....
Latency Test Results
: For each packet size tested, from 64 to 1518 bytes, latency did not exceed 3.2 microseconds when using the Ixia test suite (Figure 3).
Figure 3. Switch Latency by Message Size
http: //www.cisco.com/en/...../ps9670/images/white_paper_c11-492751-3.jpg
* InfiniBand - Wikipedia --- http://en.wikipedia.org/wiki/InfiniBand
InfiniBand is a switched fabric communications link primarily used in high-performance computing.
Latency : The single data rate switch chips have a latency of 200 nanoseconds, and DDR switch chips have a latency of 140 nanoseconds. The end-to-end latency range ranges from 1.07 microseconds MPI latency (Mellanox ConnectX HCAs) to 1.29 microseconds MPI latency (Qlogic InfiniPath HTX HCAs) to 2.6 microseconds (Mellanox InfiniHost III HCAs). As of 2009 various InfiniBand host channel adapters (HCA) exist in the market, each with different latency and bandwidth characteristics. InfiniBand also provides RDMA capabilities for low CPU overhead. The latency for RDMA operations is less than 1 microsecond (Mellanox ConnectX HCAs).
Mellanox Technologies: Solutions for Weather - High Performance Computing
Mellanox Technologies: Solutions for Microsoft Windows - High Performance Computing
혹시라도 1 Gigabit Ethernet(LAN) 사양에서 소프트웨어적으로 설정을 변경하여 network latency를 두자리 수의 microsecond(µs) Latency 성능으로 바꾸는 방법이라도 있는지는 계속해서 찾아봐야 겠네요!
(... 1Gbit/s 사양의 환경에서 한자리수의 microsecond(µs) Latency 성능을 구현하는 것은 현실적으로 불가능(?)할 것 같으므로 ...)
jeon1226님도 어떠한 방법이나 팁을 찾으신다면, 여기 게시판에 관련글을 올려주시면 저도 많이 참고하도록 하겠습니다.
그리고, jeon1226님께서 대학원 포함하여 현업에서 느끼는 여러가지 상황들이나 구체적인 사정들을... 여기 KLDP에서 논의하고 정보(관리,운영상의 노하우 및 현업사정 포함)를 나눈다면,,, 다른 여러분들에게도 많은 도움이 될 것 같네요.
/// *** Interconnect : InfiniBand /// MCR Linux Cluster ///
"MCR Linux Cluster"는, 10 microseconds(µs) 이하의 MPI latency 성능을 발휘하는데,,, 아쉽지만 이것 역시 네트워크는 Mellanox사의 InfiniBand 제품이군요.
그냥 참고만 하십시요.
( The MCR stands for Multiprogrammatic Capability Cluster. )
=================================================================================
https://computing.llnl.gov/tutorials/linux_clusters/mcr_background.pdf
(MCR) --- M&IC Capability Cluster
Multiprogrammatic and Institutional Computing (M&IC) - Lawrence Livermore National Laboratory (LLNL)
The MCR Linux cluster was built by Linux NetworX in Utah.
See the LNXI Build and LLNL Integration information for more details and photos.
1.4 : M&IC Scientific Software Development Environment
A high-performance, low-latency MPI environment that is robust and scalable is crucial to us. Today, applications are utilizing all the features of MPI 1.1 functionality. Many features of MPI-2
functionality are also in current use. Hence, a full, robust and efficient implementation of MPI-2 is of tremendous interest. A POSIX compliant-thread environment is also crucial and a
Fortran95-threads interface is also important. All libraries need to be thread-safe. MPI should be multithreaded as well as thread-safe. We should not have to tune the MPI-runtime environment
for different codes and different problem sizes. In our estimation, bandwidth of 0.2 bytes/second/peak OP/second/SMP and an end-to-end MPI ping-pong latency of less than 10 microseconds
or better will provide the desired performance. Because we are talking about systems with tens of thousands of processors, it is vitally important that the MPI implementation scale to the full
size of the system. This scaling is both in terms of efficiency (particularly of the MPI_ALLREDUCE functionality) as well as the efficient use of buffer memory. M&IC applications are carefully
programmed so that MPI RECEIVE operations are posted before the corresponding SEND operation. This allows for minimal (and hence scalable) MPI buffer space allocations.
M&IC applications require the ability for each MPI task to access up to 2.0 GiB of physical memory. The large memory sizes of MPI tasks requires that nodes be configured with
2 ~ 4 GiB of real memory per processor.
=================================================================================
http://www.docstoc.com/docs/21941443/MCR-Linux-Cluster/
...page 43 and 85...
M&IC --- http://llnl.gov/icc/lc/mic/ or https://computing.llnl.gov/mic/
MCR at Livermore
High Performance Computing at LLNL --- https://computing.llnl.gov
Lustre --- http://lustre.org or http://wiki.lustre.org/index.php/Main_Page
Quadrics --- http://www.quadrics.com or http://en.wikipedia.org/wiki/Quadrics
Top500 --- http://top500.org
* Spec. of the MCR Linux Cluster * ( The MCR stands for Multiprogrammatic Capability Cluster. )
----------------------------------------------------------
1,152 dual processor Intel Pentium 4 nodes ( total of 2,304 processors )
4 GBytes SDRAM per node ( 4.6 TBytes total memory )
115 TB local disk space
110 TB global disk space
MPI for message passing within cluster
( this MP stands for Message Passing )
OpenMP for shared memory within each noded
( this MP stands for Multi-Processing )
*** Interconnect: Mellanox Infiniband
----------------------------------------------------------
=================================================================================
* Linux Clusters Overview --- https://computing.llnl.gov/tutorials/linux_clusters/
=================================================================================
Gigabit Ethernet 일때,'네트워크 레이턴시'가 150 microseconds(µs) ,세자리수성능
아래의 교육기관(Vanderbilt Univ.)에서 주장하는 내용이 Fast Ethernet 이거나 Gigabit Ethernet 일 때, '네트워크 레이턴시'가 150 microseconds(µs) 까지는 성능이 나온다고 주장하는 것 같네요. 세자리 수의 마이크로세컨드 레이턴스 성능이 나올 수 있나 봅니다. 150 microseconds(µs) 이면 0.15 milliseconds(ms) 이네요.
0.15 ms 이면, jeon1226님의 연구실에서 현재 운영하고 있는 클러스터(1 ~ 10 ms)보다는 Latency 면에서 대략 6배에서 67배 성능향상이네요!
내용도 한번 잘 읽어보시고, 보다 구체적인 설정내용에 대해서도 대학기관이니 직접 문의를 하거나 조언을 요청하면 도움을 받을 수 있지 않을까 생각됩니다!
* ACCRE High Performance Compute Cluster --- http://www.accre.vanderbilt.edu/mission/services/hpc.php
Fast Ethernet -- Commodity networking used in most desktop computers that has a bandwidth of 100~Mbps and latency of up to 150 microseconds in Linux.
Gigabit Ethernet -- Commodity networking typically found in servers and has a bandwidth of 1 Gbps and latency of up to 150 microseconds in Linux.
설정내용과 같은, 보다 구체적인 내용을 인터넷에 공개한 다른 정보가 더 검색되면 다시 올려보도록 하겠습니다.
Books / Cluster Supercomputer / Cluster Communication Protocol /
이론적인 "배경지식"을 더 깊게 연구하고 싶으시면, 아래 Link들도 참고하시면 되겠네요.
* Book: Performance Characteristics of a Cost-Effective Medium-Sized Beowulf Cluster Supercomputer
http://www.springerlink.com/content/5ywwnh82mlrepxv6/
* Book: Performance results for a reliable low-latency cluster communication protocol
http://www.springerlink.com/content/y7035862v40247r5/
* Minimum Latency // Linux Parallel Processing HOWTO //
=================================================================
http://www.ecn.purdue.edu/~pplinux/PPHOWTO/pphowto-3.html
=================================================================
Linux Parallel Processing HOWTO : Clusters of Linux Systems
3.2 Network Hardware
* Maximum bandwidth :
This is the number everybody cares about. I have generally used the theoretical best case numbers; your mileage will vary.
* Minimum latency :
In my opinion, this is the number everybody should care about even more than bandwidth.
Again, I have used the unrealistic best-case numbers, but at least these numbers do include all sources of latency, both hardware and software.
In most cases, the network latency is just a few microseconds; the much larger numbers reflect layers of inefficient hardware and software interfaces.
=================================================================
*** 가장 기본이 되는 문서인 상기의 HOWTO문서의 내용을 근거로 미루어 짐작컨대,,, 결국 Network Latency 문제는,,,
"소프트웨어 설정상의 이슈"라기 보다는 네트워크 "하드웨어의 성능"상의 이슈로 귀결되는 것 같습니다.
"소프트웨어 설정상의 문제"
결론이라는 것이, 결국은 '네트워크 하드웨어의 성능'이라니,,,,, 힘빠지는 군요.
혹시 jeon1226님이 "소프트웨어 설정상의 문제"와 관련해서 검색한 정보가 있다면, 여기 올려 주십시요. 저도 참고 하겠습니다.
jeon1226님!
jeon1226님께서 네트워크 관련해서 뭔가 "혼돈"이 있는 것 같습니다.
jeon1226님 께서 원하시는 것이,,,
패킷 보내고 받아서 연산을 위한 데이터를 구성하는데 1밀리세컨드가 소요되고 연산 자체에 1밀리세컨드 가 소요되고, 다시 패킷 받는데 1밀리세컨드가 소요되는데 그때까지 연산을 못하고 기다리다가 다시 연산하는데 1밀리세컨드가 소요되고,,,, 이런식으로 연산하지 못하고 기다리는 시간을, 1밀리세컨드가 아니라 (말하자면) 1마이크로세컨드로 줄이기를 원하시는 것 같은데,,,
A서버가 TCP로 패킷을 TCP Segment Size 단위로 잘라서 보내고 B서버가 TCP로 패킷을 받은 후에 잘 받았다고 보낸 쪽으로 Acknowledgement신호를 보내고, Ack신호가 올때까지 기다리고 있던 A서버는 Ack신호가 온 것을 확인한 후 다시 패킷을 보내고... 이런식으로 TCP가 통신하는 것이 기본과정인데,,,
"Network Latency가 1마이크로세컨드 이다"라는 것이, 단순히 상기와같은 과정으로 패킷주고 받는 데 걸린 시간이 1마이크로세컨드가 소요된 것을 의미하는 것이 아닙니다. 이러한 부분에서 jeon1226님께서 뭔가 개념상의 혼돈이 있는 것 같습니다.
오히려 패킷을 너무 잘게 잘라서 주고 받을 경우에는, 서로 간에 패킷보내고 Ack신호 받고 하는 과정이 너무 빈번하게 일어나게 되어서 오히려 TCP 통신 상의 효율성이 떨어지게 되는 것입니다.
그래서, 속도가 빠른 네트워크 일수록 패킷을 Jumbo Frame 기법과 같이 패킷을 한꺼번에 모아서 보내는 방법을 사용합니다. 즉, 다른 말로는 기가비트네트워크에서 오히려 Jumbo Frame 기법을 사용해야 Network Latency의 효율이 좋아진다는 말입니다.
또한, 일반 랜이나 패스트 이더넷 네트워크에서도, Ack신호를 빈번하게 받는 것을 줄이기 위해서, 패킷을 최대한 한꺼번에 보내는 기법으로서 "TCP Sliding Windows" 기법 같은 것을 사용하는 것입니다.
그리고, "네트워크 레이턴시"를 1 microsecond(µs) 로 성능을 높이기 위해서는, 상기에서 언급했듯이 네트워크를 하드웨어적으로 InfiniBand 로 구성해야 하는 것이고...! ( 고속 네트워크인 InfiniBand 에서도 Jumbo Frame 기법 같은 것을 사용해야 1 마이크로세컨드(µs)라는 효율이 나오겠지요!)
다시말해서, 패킷을 최대한 잘게 잘라서 빈번하게 바로 바로 보내는 것이 네트워크 효율성(Latency)을 높이는 방법이 아니라, 오히려 반대로 고속의 네트워크일수록 '점보프레임'처럼 패킷을 모아서 보내는 것이 Network Latency의 효율성이 높아짐을 뜻한다는 말입니다.
그런데,,,,,,
단지 jeon1226님이 원하시는 것 처럼, MPI(and/or OpenMP)가 생성한 데이타의 패킷을 받을 때까지 계산 못하고 기다리는 시간에 대한 효율성과 네트워크가 패킷을 서로 주고 받을 때 Ack신호를 얼마나 덜 주고 받을 수 있을까 하는 효율성 사이의 "득과 실"에 대한 "최적화된 설정값"을, 사람이 직접 찾거나 설정하는 것이 가능한 일은 아닌 것 같습니다?!
그래서, 상기의 검색결과에서와 같이, 미국에서 조차도 네트워크 "하드웨어"에 대한 투자를 많이 해서 최대한 고속의 네트워크로 "네트워크 레이턴시"를 최대한 줄일 수 있는 방향으로 리눅스 클러스터 서버를 구성하는 것이 아닐까라는 생각이 드네요!
물론 서버 자체의 메모리 용량이나 스토리지 I/O 속도나 CPU 연산 속도도 최대한 빠른 것으로 투자하여 구성하겠지요!
다시말해서, 소프트웨어적인 설정을 어떻게 바꾼다고해서 1 Gigabit 네트워크의 Latency를 1 microsecond(µs)로 만들 수 있는 방법은 있을 수가 없으며, 1 Gigabit 네트워크에서는 Jumbo Frame 기법을 쓰더라도 Latency를 1 microsecond(µs)로 만들 수는 없고, 결국 하드웨어 투자로 고가의 InfiniBand 고속 네트워크로 클러스터 서버를 구성해야 1 microsecond(µs)의 Network Latency를 얻을 수 있다는 뜻입니다.
설명이 부족한 면이 있지만 그래도 jeon1226님의 의문점이 풀렸기를 바랍니다...!
상기의 설명 내용에 오류가 있거나, 혹시 jeon1226님의 질문에 대한 설명으로 핀트가 벗어난 내용이면 조언 바랍니다.
노파심에...
설명하시는 상황이 Nagle algorithm과 맞아떨어지는 것 같은데, 이쪽은 확인해 보셨나요?
구글에서 Nagle algorithm, TCP_NODELAY로 검색해 보시면 자료가 많이 나옵니다.
Nagle's algorithm
Nagle's algorithm도 결국은, "어떻게 하면 Ack신호를 받는 빈도 수를 줄이면서 데이터를 많이 보내느냐, Ack신호발송 delay를 적게 조치하느냐"이니까, "TCP Sliding Windows"기법이나 "Jumbo Frame"기법과 비슷한 맥락의 기법이나 알고리즘이군요.
...음냐리...
뭐 그렇게 따지자면 해시 테이블과 B-tree와 LRU cache는 다 "어떻게 원하는 데이터를 빨리 찾느냐"니까 비슷한 맥락의 기법이긴 하죠.
Vanderbilt Univ. 에 직접 조언을 구해보시는 게 빠른 방법 같습니다!
개인적인 생각으로는, 네트워크 세부 설정 부분도 생각을 해야 하겠지만 그것보다는 먼저...
MPI(and/or OpenMP)가 메세징 하는 데이터의 바이트의 크기나 기타의 관련 설정들을 (각각의 수치해석 프로그램을 컴파일할 때마다) 적절히 최적값을 유추해서 설정해 주는 방향으로 해야하지 않을까 싶습니다만...!
(... 각각의 시뮬레이션 하는 수치해석 코드의 특성과... 해당 클러스터 서버의 네트워크 환경에 따라서,,, 그때 그때 적절히...)
상기에서 설명한 대학기관(Vanderbilt Univ.)에 직접 문의를 하셔서,,, 어떻게 1 Gigabit Ethernet 환경의 Cluster Server에서 어떻게해서 150 microseconds(µs) 또는 0.15 milliseconds(ms) 의 Network Latency 효율성을 얻었는지 알아보시는게 제일 빠른 방법이 아닐까 생각됩니다!
이 분야는 잘
이 분야는 잘 모르지만,
질문하신 분의 질문 network latency 를 줄이는 방법 이라는게 innobeing님이 말씀 하신게 맞나 싶네요.
1.5k 이하 작은 패킷(일반적 ethernet 에서의 MTU)을 주로 통신 하고 데이터 양이 많지 않다면
Jumbo frame 은 물론이고 InfiniBand를 사용한다고 나아질 내용은 아닌 것 같습니다.
질문은 일반적으로 패킷을 OS 에서 전송할때 하나씩 보내는게 아니고 버퍼링을 통해 묶어 보내게 되는데,
이 버퍼링 대기 시간을 줄이고 싶으신거 아닌가요?
위 내용은 장치 드라이버 레벨 또는 OS의 네트워크 스택에서 처리 하지 않을까 생각 합니다.
따로 커널에서 설정하는 부분은 찾지 못하겠네요. 소스를 좀 봐야 할듯.
도움이 못되 죄송합니다. ㅡㅡ;
고성능 클러스터에서는 반드시 고려 해야 할 사항 같아서 저도 좀 알고 싶네요.
openmpi, http://www.open-mpi.
openmpi,
http://www.open-mpi.org/hg/hgwebdir.cgi/ompi-svn-mirror/rev/857fc5aed408
OTL
TCP_NODELAY 와 관련이
TCP_NODELAY 와 관련이 있군요.
여기도 참고 자료가 있습니다.
http://articles.techrepublic.com.com/5100-10878_11-1050878.html
위키에도 잘 나왔있네요.
http://en.wikipedia.org/wiki/Nagling
Interactions with real-time systems
Applications that expect real time responses can react poorly with Nagle's algorithm. Applications such as networked multiplayer video games expect that actions in the game are sent immediately, while the algorithm purposefully delays transmission, increasing bandwidth at the expense of latency. For this reason applications with low-bandwidth time-sensitive transmissions typically use TCP_NODELAY to bypass the Nagle delay.[2]
답변 고맙습니다
아직 손댈 생각은 못하고 있지만 큰 도움이 되었습니다.
읽어보니 nagle 알고리즘이 말하는 상황과 동일합니다. os에서 뭔가 네트웍 최적화를 위해 패킷을 바로 안보내고 ms단위로 붙들고 있는 상황이 말입니다;; 왠지 mpi에서 당연히 tcp_nodelay로 보낼 것 같긴 한데... tcp nodelay로 해결될 문제인지 알아보겠습니다. 답변주신 모든 분들 고맙습니다.
몇자 적어 보고자 찾아보는 도중
댓글이 많이 올라 왔군요...
많은 도움 받았습니다 :-)
(너무 오래 쉬었네..)
Communication & Utopia...
Communication & Utopia...