10G 트래픽 수집 시스템 만들고 있습니다.
안녕하세요^^;
지금 DAG 카드라는 것을 이용하여 10G 망에서 패킷을 수집하여 관리하는 시스템을 만들고 있습니다.
제가 워낙 초보라서 많은 어려움이 있는가운데 힘겹게 패킷 헤더 정보를 뽑아서 DB에 넣는 것까지 성공하였습니다.
하지만 문제가 생겼네요~
DB에 잘 들어가긴 들어가는데 처리속도가 너무 늦다는 점입니다.
헤더 정보를 DB에 넣을 때 row당 약 80byte 정도가 됩니다.
그런데 평균 초당 30,000~50,000개의 패킷이 수집되는데 그걸 처리를 못해주는 것 같습니다.
mysql에서 초당 처리할 수 있는 삽입(row갯수)이 몇개 정도라고 볼 수 있을까요?
mysql의 한계인지 쿼리의 문제인지 잘 모르겠습니다.
도움 부탁드립니다^^;
일단 삽입이 제대로 되야 나중에 빠른 검색을 위한 고민을 해볼텐데 삽입조차 처리가 느리니깐 답답하네요
ㅠㅠ
사용한 쿼리는 아래와 같습니다.
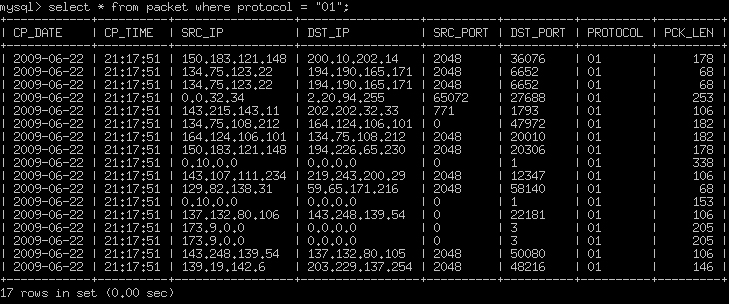
sprintf(query, "INSERT INTO total_traffic VALUES (now(), now(), '%s', '%s', '%u', '%u', '%02x', '%d')", src_ip, dst_ip, ntohs(srcport[0]), ntohs(dstport[0]), protocol[0], ntohs(drec->wlen)); mysql_query(sql_connection, query);
요 위에께 루프를 돌며 초당 3~5만개를 넣어줘야 하는데 DB에 보면 초당 8~9천개가 들어가있는것 같아요^^
혹시 이런 비슷한 경험으로 초당 몇만개의 자료를 넣어보신적이 있으신분 도움 부탁드립니다^____^;
참고로 시스템 사양은 다음과 같습니다.
===========================================
*Hardware
- CPU : Dual-Core AMD Opteron(tm) Processor 2218 (2.6GHz)
- RAM : 4Gbyte
- HDD : 1093Gbyte = 1Tbyte
- NMIC : DAG 8.2X (패킷수집장치) - 이 장치로 인해 패킷 해더 분석속도는 전혀 지장 안받습니다^^;
*Software
- OS : CentOS release 4.7 (Final)
- DB : mysql 5.1.34
===========================================
| 첨부 | 파일 크기 |
|---|---|
| 39.07 KB |
{kind=link}
아마
mysql로는 좀 힘들지도 모릅니다만..
간단하게 하시려면 heap table을 쓰시면 됩니다.
이것은 메모리에 올라가는 테이블로서 메모리용량만큼(?) 데이터를 쌓을수 있습니다.
쌓으면서 기간이 지나면 다른 테이블로 옴기면 되겠죠.
그러나 가급적이면 mysql을 제외한 다른 방법을 쓰시는것이 좋을듯합니다.
------------------------------------------------------------------------------------------------
Life is in 다즐링
------------------------------------------------------------------------------------------------
Life is in 다즐링
다른 상용DB를 사용해도 무리라고 봅니다.
메모리 DB를 구현하시거나, 구입하세요.
다른 방법으로는 램드라이브를 만드시고 sqlite를 사용해 보시기 바랍니다.
가능하면 하드디스크 억세스를 줄이는 방법이외에는 속도 개선의 여지가 없네요.
혹시 heap table 로 바꿀땐..
안녕하세요^^
먼저 답변주셔서 너무 감사드립니다~
alter table total_traffic type=heap;
이런식으로 하면 테이블 속성이 바뀌는 건가요?^^;
그럼 현재 기본으로 생성된 테이블은 type=myisam 인가요?
제가 워낙 모르는 것들이 많아서 죄송해요ㅡㅡ;;
답변 기다리겠습니다^^
...
1) 테이블 속성(?) => 테이블의 스토리지 엔진(storage engine) 바꾸기
ALTER TABLE total_traffic ENGINE = 'heap';
2) show create table total_traffic;
* 예시
mysql> CREATE TABLE test111 (
-> `id` int(11) DEFAULT NULL
-> ) ENGINE=MyISAM DEFAULT CHARSET=euckr;
Query OK, 0 rows affected (0.08 sec)
mysql> alter table test111 engine = 'heap';
Query OK, 0 rows affected (0.06 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table test111;
+---------+--------------------------------------------------------------------------------------------+
| Table | Create Table |
+---------+--------------------------------------------------------------------------------------------+
| test111 | CREATE TABLE `test111` (
`id` int(11) DEFAULT NULL
) ENGINE=MEMORY DEFAULT CHARSET=euckr |
+---------+--------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql>
------------------ P.S. --------------
지식은 오픈해서 검증받아야 산지식이된다고 동네 아저씨가 그러더라.
------------------ P.S. --------------
지식은 오픈해서 검증받아야 산지식이된다고 동네 아저씨가 그러더라.
흠...
일단 mysql에서 단일/블럭/loader 를 이용하여 DB에 insert하는 방법이 있는 것으로 알고 있습니다.
insert into values (),(),()... <-- 이렇게 했던 것으로 기억 되는데요...
이런식으로 insert 한번에 여러 Row를 입력하는 방법이 단일 insert 보다 수배 이상 빠릅니다.
mysql쪽 query buffer 값을 좀 늘리신 다음 블럭 insert로 해보시면 약간의 효과는 있을 것입니다.
좋은 방법입니다. 또
좋은 방법입니다.
또 다른 하나를 추가하자면,
mysql이라면, LOAD DATA INFILE 이라는 bulk insert방법을 사용해 볼 수 있겠습니다.
물론, 대부분의 DBMS에서도 여기에서 기술된 3가지 방법을 모두 지원하는 편입니다.
------------------ P.S. --------------
지식은 오픈해서 검증받아야 산지식이된다고 동네 아저씨가 그러더라.
------------------ P.S. --------------
지식은 오픈해서 검증받아야 산지식이된다고 동네 아저씨가 그러더라.
... 지금 DAG 카드라는
* 우려에 대한 조언
- 1G망에서도, 작은 크기 패킷(64~256등) 경우에도, 수백Kpps를 보일 수 있습니다.
- 고려사항에, aggregation이나 sampling 또는 실트래픽에 대한 검토결과로 30K~50Kpps로 측정했다면 모를까? 10G망에서는 우려되는 모델로 보입니다.
빠른 검색(?)을 전혀, 고려하지 않는 가정에서는 작은 레코드인 경우, 30k~50k레코드는 달성될 것으로 보입니다.
다른 데이터베이스도 비슷한(소위, 도토리 키재기) 정도일 것입니다.
그러나, 검색을 고려한다면 많은 실험을 해보셔야 할 것입니다.
초당 3만레코드라고 가정해도, 하루로 환산하면, (30,000 x 24 x 60 x 60 =) 2,592,000,000
약 25억건의 레코드라고 볼 수 있는데, 어떤 DBMS도 이를 이용한 통계(?)등의 쿼리를 처리하기에는 무리가 있을 것입니다.
삽입과 빠른 검색은 나누어 생각하시면, 낭패를 볼 수 있으니, 유념하시기 바랍니다.
------------------ P.S. --------------
지식은 오픈해서 검증받아야 산지식이된다고 동네 아저씨가 그러더라.
------------------ P.S. --------------
지식은 오픈해서 검증받아야 산지식이된다고 동네 아저씨가 그러더라.
정말 제가 생각지도 못한 귀중한 답변이네요^^
안녕하세요^^
너무 자세한 조언 감사드립니다~
역시 제가 DB와 network management쪽을 거의 처음 접해보는지라 생각못했던 부분이 많았는데 꼭꼭 잘 찝어주신것 같아서 뿌듯합니다^^;
위에 주신 답변도 너무 감사히 잘 봤습니다..ㅎㅎ
이번 7~8월에 걸쳐서 시스템 구성이 완료되어야 하는데 정말 노력 많이해야할 것같아요~
논문 2편과 웹에서 관리할 수 있는 시스템, 그리고 100page 분량의 최종보고서까지...ㅋㅋ할께 많네요^^
아마도 이번 과제를 통해서 제가 얻어갈 수 있는 것이 정말 많을것 같습니다^____^;
종종 질문 올릴것 같은데 앞으로도 좋은 답변 기대해보겠습니다^^*
감사합니다~편안한 밤 되시길 바랍니다...^^
웹UI까지 계획하시고
웹UI까지 계획하시고 계신다면 역시 ntop을 참조하심이 좋을것 같습니다. 어느 기능까지 구현할지, 그리고 UI는 어떻게 할지 ntop에서 많은 힌트를 얻었습니다.
그리고 웹 UI -> ntop은 mrtg처럼 RRD tool로 데이터 관리하고 그래프 그려줍니다. 저는 웹에는 Mysql과 php, Open Flash Chart를 썼네요.
http://wiki.kldp.org/wiki.php/superwisdom
네~맞습니다^^
안녕하세요^^
최종 결과물은 웹GUI를 가지고 있어야 합니다^^
정말 깔끔하지 못한 질문 하나 올렸는데 모든 분들이 정성스럽게 답변을 주셔서 너무 감사드립니다^_____^
부러울 따름입니다ㅋ
웹에서 접근하여 어디서든지 측정하고자 하는 위치의 트래픽을 감지할 수 있어야 합니다~
java를 쓰라고들 하는데 저는 자바는 해본적이 없어서 그나마 c언어와 유사한 구조를 지니고 있다는 php를 생각하고 있었습니다.
챠트도 어떻게 해야할지 고민해봐야 겠습니다^^;
ntop도 찾아서 사용해봐야 겠네요~
일단 중간발표가 시급하니 급한불부터 끄고 원점으로 돌아와서 고민해봐야겠습니다.
도움 주셔서 정말 감사합니다^^
오늘 하루도 행복한 저녁으로 마무리 하시기 바랍니다~!
^_______^*
mysql이 대부분의
mysql이 대부분의 상황에서 다른 오픈소스/상용 DBMS에 비해 빠르긴 하지만 그 차이가 크지도 않습니다.
그리고 상대적으로만 빠르다고 하는것이지 mysql은 느립니다.
그리고 원하시는 기능을 그 장비에서 처리할 수 없습니다.
다른 분이 하루 레코드 갯수를 계산해 주셨는데 거기에 평균 80바이트를 곱하면 순수 데이터만 207,360,000,000 byte입니다. 200기가쯤 되죠.
메모리는 4기가인데 이정도면 입력은 할 수 있어도 정렬이나 random access는 현실적으로 불가능한 수치입니다.
게다가 조회를 위한 인덱스를 잡는다면 필드 두세개 정도만 잡아도 데이터보다 인덱스가 더 커질 수도 있습니다.
인덱스를 안잡으면 5일, 잡으면 2~3일 내에 디스크가 꽉 찹니다.
mysql을 버리면 입력은 할 수도 있습니다.
초당 3만 레코드 * 평균 80바이트면 디스크에 2.4메가씩 써주면 됩니다. bulk write라고 해도 견딜만한 수치입니다.
모든 패킷의 정보를 조회하는 것이 목적이 아니라 각 패킷의 연결들을 가지고 통계를 내서 그걸 조회하는 것이 목적이라면 일단 파일에 무조건 append하는 식으로 블럭을 만들고 그걸 다른 장비에서 특정 블럭 단위로 통계를 내서 DB에 입력하는 방법도 고려해 보시면 좋겠네요. 다 쓴 블럭은 지우고요.
학교 다녔을 때, 이와
학교 다녔을 때, 이와 비슷한 프로그램을 구현해 본 적이 있습니다.
저는 pcap을 사용했기 때문에 수집하고 분석하는데에서 CPU가 많이 발목을 잡았는데, 지금처럼 H/W를 사용하신다면 역시 I/O가 문제겠군요.
아무튼 저도 비슷한 고민을 했었는데, 결론적으로 DB에 들어갈 데이터 자체를 줄여야 한다는 결론이 났습니다.
1. 메인 thread에서는 계속 패킷을 수집하면서 메모리에 패킷 정보를 누적합니다.
2. 그러다가 일정 시간이 되면, analysis thread로 모아진 패킷 데이터를 넘깁니다.
3. analysis thread에서는 모아진 패킷을 압축합니다.
4. 압축이 완료된 데이터를 db thread로 넘겨서 mysql에 write합니다.
위의 과정을 반복했는데, 압축은 gzip으로 한다는 그런 이야기가 아니구요 ㅎㅎ,
예를 들어 FTP로 데이터를 주고 받을 때, 패킷 헤더(src 및 dest 아아피와 포트 등)는 비슷하잖아요? 이런 것들을 모으면 수백, 수천개의 패킷이 하나로 줄어들 수 있습니다.
극단적으로 A와 B가 p2p로 1분간 10만개의 패킷을 교환했어도, DB에는 1개의 row만 들어갈 수 있는거죠.
그리고 패킷을 수집하는 프론트엔드에서는, 큐가 넘치면 어쩔 수 없이 패킷 수집 자체를 샘플링 해버리도록 했습니다.
http://wiki.kldp.org/wiki.php/superwisdom
결국 flow 개념을 넣었다는 건가요?^^
먼저 답변 감사드립니다~
pcap 사용안하고 하드웨어를 사용한다는 것은 시스템에 부하를 주지 않기때문에 상당한 매리트 입니다.
이 과제가 제가 취미로 하는 것이 아니고 대학원 연구실에서 처음 들어와 맡게된 것이거든요^^
저도 이것저것 찾다보니 님께서 말씀하신것 처럼 같은 특성을 갖는 패킷끼리 묶는다는 것을 본적이 있네요~
flow를 만든다고 하더라고요~최근 router에서 flow를 생성해서 보내주는 경우도 있고, 제가 직접 flow를 생성하는 방법도 있고요~
그런데 그부분에서 어떻게 해야하는지 몰라서 일단 무조건 몽땅 다 DB에 넣어보자 식이었는데 역시 힘드네요ㅎㅎ
위에 많은 분들이 말씀하신 것처럼 DB 자체에는 한계가 있는것 같습니다..
insert되는 량을 줄이는 알고리즘을 뽑아내는게 꼭 필요한것 같아요~
저도 그쪽 부분을 연구해보도록 해봐야겠습니다^^;
혹시 flow 생성(=압축)에 관하여 도움이 될만한 책이나 논문등...자료같은것 있으면 추천 한방 부탁드립니다~^^;
트래픽 분석에 관해서 볼만한 책이 시중에 잘 안보여서 인터넷만 뒤지고 있는데 좋은 자료가 많이 안보이는 것같습니다..ㅜㅠ
편안한 밤 되시고~감사합니다^^
...
그렇습니다. 기존의 pps, bps, session등의 개념과 한계를 넘어, traffic aggregation 및 traffic sampling 개념을 적용한 근래의 기술이 flow개념이지요.
flow개념을 수용한, 이미 널리 알려진 기술로, 표준이랄 수 있는 sflow, ipfix를 들 수 있을 것이고, 업계표준으로 시스코 netflow, 주니퍼 j-flow, 리버스톤의 LFAP등이 있겠습니다. 각각의 RFC나 관련자료가 도움이 될 것입니다. 이들 기술간의 관계(족보?)를 알아보는 것도 도움이 될 것입니다.
대학원생이시라면, netflow를 기반으로 연구를 시작하는게 좋겠습니다.
netflow는 가장 널리 사용되며(시스코/호환 장비가 몇 대더라?), pcap등을 이용한 패킷캡쳐내용을 netflow유형으로 aggregation하여(netflow generator) 예제코드(상용에 버금가는)등을 구하는 것도 쉬우며(DAG카드 인터페이스가 native와 이용자 층이 두터운 pcap인터페이스 모두 지원하는 편이지요?), 이러한 generator단을 지나, collector, 분석에 이르기 까지 많은 연구자료를 찾을 수 있기 때문입니다.
그런데, DAG카드까지 사용했다면, 이러한 내용은 이미 서베이했을 것이고, 결국, 트래픽분석이 관건이 될것으로 보이는데요....
뭐하나 중요하지 않은 것이 없지만, 특히, 트래픽 분석부분이 궁극의 목적라고 할 만큼 중요하다고 생각합니다. 그러나, 아직은 미완의 영역/기술이라 섣불리 추천하는 것은 어렵습니다. 특히, 학생에게 말이지요.
단지, 세계적으로, 대부분의 분석 접근 방법론이 netflow기반이거나, 적어도 호환되는 방식을 제공한다라는 정보를 드립니다. 이를 기반으로 대학, 연구소, 기업등의 접근 및 장단점을 분석하는 절차가 우선시 되어야 할 것으로 보입니다.
------------------ P.S. --------------
지식은 오픈해서 검증받아야 산지식이된다고 동네 아저씨가 그러더라.
------------------ P.S. --------------
지식은 오픈해서 검증받아야 산지식이된다고 동네 아저씨가 그러더라.
정말 유익한 정보입니다^^
답변 또 주셨네요^^너무 감사드립니다!
DAG카드가 pcap인터페이스 모두 지원하는 것 같습니다.
netflow기반으로 가야하는게 정도인것 같습니다^^;
이것 저것 서베이하면서 지금 시간까지 한달 넘게 흘렀는데 많은 것을 하지못한 제 자신이 너무 부끄럽네요>.<
먼저 flow 개념부터 확실하게 이해하고, 위에 나열해 주신 여러가지의 flow에 관한 RFC나 관련자료 등을 먼저 학습해봐야겠습니다.
그리고 flow를 통해서 안정적인 DB를 확보하고 나면 말씀하신것 처럼 트래픽 분석에 관해서도 많은 고민해봐야할 것 같습니다^^
이른 시간부터 답변 달아주셔서 너무 감사합니다~
일단 중간발표에서 netflow에 관한 내용을 가지고 향후 일정에 포함시켜봐야 겠습니다.
오늘 하루도 편안하고 행복하게 마무리 하시기 바랍니다^^
감사합니다.
그냥 5 Tuple로 묶으셔도 됩니다. ^^
Src IP, Dst IP, Src Port, Dst Port, Protocol 을 키값으로 해쉬테이블을 구성하여 일정시간 동안
Flow를 생성하는 간단한 구조로 한번 가보셔도~~ ^^
============================
Stay Hungry, Stay Foolish
============================
Stay Hungry, Stay Foolish
감사합니다ㅋ
안녕하세요^^;
하다하다 정 안되고 힘들면 5개 tuple도 생각해봐야할것 같아요..ㅋㅋ
일단 위에 소개된 방법 하나하나 차근차근 다 해봐야할것 같습니다~
결국 결론은 한점으로 모여지내요~
Flow^^
답변 너무 감사드리고~
언제나 행복한 삶이 되시길 바랍니다^o^
통계를 위한 것이라면..
단지 통계를 위한 것이고 또한 반드시 전체데이터를 저장할 필요가 있는 것이 아니라면..
1. 일부 데이터의 실시간 처리 후 저장하는 방법도 있습니다. 이런다면 저장할 데이터를 줄이면서도, 처리되어 자장된 데이터를 통해 통계를 낼수도 있습니다.
2. 전체 데이터가 아닌 의미있는 일부의 데이터만 저장하는 방법도 있겠죠. 위에 다른 분 말씀처럼 하드웨어적으로 불가능한 처리량이라면 이 방법도 대안이 될 수 있을꺼라 생각합니다.
그리고 말씀 하신 환경을 타겟으로하는 DB를 보통 Data Stream Management System 라고 하더군요.
꼭 전체를 다 봐야
꼭 전체를 다 봐야 하나요? 보통 cisco guard 나 기타등등 장비들은 sampling 을 합니다. 즉 전체 패킷의 1/x 만 받아서 sampling 을 하더군요.
그러게요.
기가급 망의 패킷(해더 정보)을 모두 저장할려면, 미러링하는 장비가 라운드로빙으로 분산 로그 서버에 하나씩 나누어주고 각각 저장된 정보를 조인해서 보는 방법이외는 뾰족한 수는 없을 듯 합니다.
phonon님 감사합니다~
분산 서버를 이용하는 것도 좋은 방법중에 하나라고 생각됩니다^^;
일단 저에게는 큰 작업이 될 수도 있으니 아래에서 부터 차근차근 밟아가보도록 하겠습니다~^^
답변 감사드려요^^*안녕히 계세요~!!
김정균님~감사드려요..^^
일단 DAG 카드 자체에서 패킷을 손실업이 10G까지 다 잡아주니깐 그걸 본다는 가정으로 시스템을 구축해야 할것 같아요~
그래서 나중에 Flow를 만들더라도 일단 하나하나 다 까보고 만들어야 할것 같습니다..ㅠㅠ
목적..
트래픽 분석의 목적부터 정확히 하시는게 나을듯 하네요..
10G면 보통 usable 80%로 볼때 8G를 생각 할수 있을것이고..
이런경우 Full packet을 수집하는 경우는 KT쪽에서 밖에는 안하는걸로
알고 있습니다..( 프로젝트명은 실명 거론 하지 않도록 하겠습니다. - 개인 사정상.. )
요즘 트렌드로는 유형 분석을 하게 되는데 그런 경우 5-TUPLE을 하게 되는데
이때도 어떤 레이어에 어떤 방식으로 분석 할지에 따라서 데이터량이 많이 차이를
냅니다.
현재 5-Tuple을 사용한 경향분석 시스템들도 많이 상용화를 끝낸것으로 압니다.
(한 종류는 참여하여 현재 상용판매중인 것으로 압니다.)
일단 명확한 것은 지금 하시는 방법에 Mysql(Heap Table)로 충분히 가능 하실겁니다.
대신 여러 Raw Data Table을 Queueing 형태로 가져 가시는게 좋을실겁니다.
그러나 RawData수집은 가능 하더라도 분석쪽에 쓰이기 위한 Table Access Time을 줄이시기
위해 좋은 모델을 고려 하셔야 할 듯 싶습니다.
혹시 도움이 될지 모르겠지만 더 자세한 사항이 궁금하시면 메일 주십시오.
dif001 앳 naver.com
bleu님 감사합니다^^
지난 월요일에 대전에 중간 상황 보고하고 오고 댓글이 달린걸 이제서야 봤네요^^;
발표 준비하느라 이것저것 할게 많더라고요..
이번에 대학원 와서 처음으로 이런 류의 일을 해보는데 역시 만만치가 않네요..
DB다루는 방법이나 Network Management 쪽이나 모두 학부때 얇게 배운 지식뿐이니깐요..
사실 이번에 중간 보고 하러 갔다가 심사하셨던 실무자 분들이 이런 얘기를 하시더라고요~~
대학원에서 얘기해서 나올 답은 아닌것 같으니 실무에 있는 사람들과 직접 부딫히며 연구하는게 좋은 방법이라고...^^
아마도 그 말이 맞는 걸지도 모릅니다.
사실 저도 누군가를 통해 이 방면의 지식을 얻을 수 있다면 정말 감사한 일이겠죠ㅎ
이렇게 나마 게시판을 통해서 여러 분들의 귀한 한말씀, 한말씀을 듣게 되니 큰 힘이 되는것 같습니다~!!
현재 DAG 카드에서 100% 비손실 캡쳐는 가능합니다~파일로도 패킷들을 저장해줄 수 있고요~~
문제는 DB에 어떻게 잘 넣느냐인데...
bleu님께서 하시는 말씀은 즉 Heap Table에 패킷을 여러개 모았다가 한번에 넣으라는 말씀이신가요?^^;
앞서 말씀드렸다시피 제 짧은 지식으로는 100% 이해가 안되네요ㅎ
답변 너무 감사드립니다~일단 많은 분들의 추천으로 NetFlow라는걸 먼저 학습해봐야겠습니다~
감사합니다^^
댓글 달기