네이버 사전을 PyGTK 로 만들어봤습니다.

글쓴이: zelon / 작성시간: 월, 2007/08/27 - 2:56오후
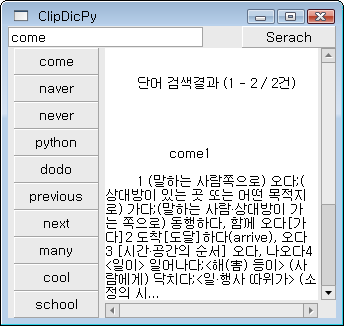
PyGTK 로 클립보드를 제어하는 샘플을 변형하여 네이버 사전에서 결과를 얻어오는 프로그램입니다. 간단한 히스토리 기능이 들어가있습니다.
클립보드에 텍스트로 된 단어가 들어오면 해당 단어를 네이버 사전에서 검색해서 결과를 보여줍니다. 그러므로 어떤 프로그램이라도 단어를 Ctrl + C 로 클립보드에 복사를 지원해주면 검색이 가능합니다.
다양한 사전 프로그램들이 많은데 특정 프로그램에서는 지원해주지 않는 것들이 많아서 고민하다가, 클립보드를 통해서 단어를 가져오면 어떨까해서 만들어봤습니다 :)
실행은 'python ClipDicPyMain.py' 를 실행하시면 되고, 당연히 PyGTK 와 파이썬이 설치되어야 합니다. :)
File attachments:
| 첨부 | 파일 크기 |
|---|---|
| 2.18 KB | |
| 11.16 KB |
{kind=link}
Forums:
앗. search 철자에
앗. search 철자에 오타있네요. :-)
---------------------------
Smashing Watermelons~!!
Whatever Nevermind~!!
Kim Do-Hyoung Keedi
----
use perl;
Keedi Kim
허걱... 이런... 눼
허걱... 이런... 눼 오타라고 생각해주세요 크흑 ㅠ.ㅜ(왠지 스스로 바보라고 생각중;;)
-----------------------------------------------------------------------
GPL 오픈소스 윈도우용 이미지 뷰어 ZViewer - http://kldp.net/projects/zviewer/
http://www.wimy.com
-----------------------------------------------------------------------
GPL 오픈소스 윈도우용 이미지 뷰어 ZViewer - http://zviewer.wimy.com
블로그 : http://blog.wimy.com
좋군요. 몇가지 기능
좋군요. 몇가지 기능 추가 요청해도 될까요?
찾지 못한 단어는 히스토리에 추가하지 않는 것하고
원할때 동작을 잠시 멈추는 기능이 있었으면 좋겠네요.
--
perl -e's@@JEON Myoung-jin@;sub man{s| _|her e|}
sub see{s;^;Just;;u;s;e ;Perl ;;to;print$_,$/}$uperMan=M;
s=^....=U are not=;s~$uperMan~~;&admitIt;s=U are = A=;s|young|_|;&man;
sub admitIt{say;ye;s!-\w+! Hacker!};see U'
$Myoungjin_JEON=@@=qw^rekcaH lreP rehtonA tsuJ^;$|++;{$i=$like=pop@@;unshift@@,$i;$~=18-length$i;print"\r[","~"x abs,(scalar reverse$i),"~"x($~-abs),"]"and select$good,$day,$mate,1/$~for 0..$~,-$~+1..-1;redo}
그렇군요!! 찾지 못한
그렇군요!! 찾지 못한 단어는 히스토리에 안 넣게 ^^;; 원래 이 프로그램은 제가 이전에 C#, Java 로 만들었던 것을 PyGTK 로 옮기면서 클립보드 예제를 변형하면서 히스토리 기능이 생겨서 미처 생각 못했습니다. 말씀하신 두가지 기능 모두 간단한 거라 곧 수정 후 다시 올리도록 하겠습니다.
2분이나 답글 다시는 뜨거운 반응을 보여주셔서 어느 정도 완성 후 kldp.net 에 릴리즈 하도록 하겠습니다.
-----------------------------------------------------------------------
GPL 오픈소스 윈도우용 이미지 뷰어 ZViewer - http://kldp.net/projects/zviewer/
http://www.wimy.com
-----------------------------------------------------------------------
GPL 오픈소스 윈도우용 이미지 뷰어 ZViewer - http://zviewer.wimy.com
블로그 : http://blog.wimy.com
추가 기능 요청 해도
추가 기능 요청 해도 되는 것인가요? :-)
검색 후보 단어가 생기면 해당 검색 후보 단어들을 모두
한 스크롤 안에 처리를 할 수 있으면 좋을 것 같네요.
예를 들면 test 단어 같은 경우에는 뜻1, 뜻2, ... 가 있는데
첫 화면에서는 요약판만 보여주거든요.
---------------------------
Smashing Watermelons~!!
Whatever Nevermind~!!
Kim Do-Hyoung Keedi
----
use perl;
Keedi Kim
음... 해당 기능은
음... 해당 기능은 저도 고려해봤었는데, 2개의 후보 중 아래 후보 단어를 찾고자 했던 거라면 한참 스크롤해야할 거 같아서 ^^;;; 요약판을 보는게 좋을 거라고 생각했었습니다.
지금 다시 생각해보니 일단 요약판을 보여주고, 그 밑에 후보를 다시 나열하는 것은 괜찮을 듯 하네요. 의견 감사합니다 :)
-----------------------------------------------------------------------
GPL 오픈소스 윈도우용 이미지 뷰어 ZViewer - http://kldp.net/projects/zviewer/
http://www.wimy.com
-----------------------------------------------------------------------
GPL 오픈소스 윈도우용 이미지 뷰어 ZViewer - http://zviewer.wimy.com
블로그 : http://blog.wimy.com
expand 부분을 조금 고쳐봤습니다.
window 사이즈를 늘이면, 각 box들이 모두 늘어나는 문제를 수정해봤습니다. pygtk를 오랜만에 보니까, 감회가 새롭네요. 예전에 VEE 가지고 놀았던 적이 있었는데 :)
커널컴파일한다고 그녀를 기다리게 하지 마라.
커널컴파일한다고 그녀를 기다리게 하지 마라.
라이센스 검토를 하셔야 합니다.
좋은 프로그램에 태클을 거는 것 같아서... 죄송합니다만...
zelon님이라면 제가 말하고자 하는 바를 이해하실테니...
http://kldp.net/search/?type_of_search=soft&words=dic
kldp.net에서 검색해보시면 단일 부류로 가장 많은 프로그램이 사전일겁니다.
이 프로젝트들은 지금 거의 모두 중단된 상태입니다.
그리고 그 이유는 아시는 바와 같이.. 사전 데이터(심지어 발음 데이터까지)의 차용에 따른 라이센스 문제였습니다.
요즘은 네이버같은 포털들도 오픈소스에 대해서 호의적니까...
결과를 웹브라우져를 실행시켜서 네이버 사전으로 볼 수 있는 링크를 제공한다던가(view in naver?)...
네이버 배너를 달아준다던가(powered by naver?)...
하는 조건으로 공식적으로 사용할 수 있게 해달라고 해보시면 어떨까요?
(사실 네이버도 출판사에서 사전데이터를 받아서 쓰는 거라 잘 될지는...-.-;;;)
아무튼 이 문제만 해결된다면 멋진! 유용한! 프로그램이 될 수 있을 것 같네요~
----
the smile has left your eyes...
----
the smile has left your eyes...
API를 통하면 될 겁니다.
이 쓰레드의 설명을 볼 때는 API를 썼겠거니 했는데 (그런 정도가 아니면 이전에도 많이 나왔던 다른 사전과 다를 바가 없으니까요) 코드를 보니 그게 아니군요. 제가 요즘 API를 끌어다 쓰는 코딩을 하다보니 오해를 했습니다.
http://openapi.naver.com/page.nhn?PageId=1_11 를 보면 영어사전에 대한 OpenAPI 설명이 나와 있습니다. 애초에 가져다 쓰라고 공개를 한 거기 때문에 따로 허락을 득하거나 할 필요가 없습니다. API key를 하나 받고 getDic.py만 고치면 됩니다.
저작권 문제 같은 건 생각할 필요도 없군요. 로컬에 직접 데이터를 구축하고 오프라인 검색을 지원할 게 아니면, 그냥 API 지원하는 데다 질의해서 결과를 받아오면 됩니다.
해당 링크 페이지의
해당 링크 페이지의 설명을 보고 궁금한게 있습니다만...
OpenAPI로 쿼리 요청하면(사전)
응답으로 받는 것은 결국 단어 뜻 링크여서
단어 뜻 링크까지는 xml로 깔끔하게 받으나
결국 브라우져가 아닌곳에서 보여주려면
여전히 html 내용을 걸러내야 하는것이죠?
---------------------------
Smashing Watermelons~!!
Whatever Nevermind~!!
Kim Do-Hyoung Keedi
----
use perl;
Keedi Kim
그럴 지도 모르겠네요
item - 개별 검색 결과이며, title, link, description을 포함합니다.
라고 되어 있길래 본문까지 주는가 싶었는데, 예제는 뜻이 안 나와 있네요.
궁금한 것이
궁금한 것이 있습니다만...
사전 데이터를 로컬에 저장하는 것은... 음...
복잡한 문제니까 논외로 치더라도
(로컬에 저장은 상관없는데 그걸로
또 다른 서비스를 제공하는게 문제의 소지가 있는거겠죠?)
스파이더링 툴로 사전 데이터를 사용하는 것이
라이센스 쪽에서 문제가 되는것인가요?
지리한 질문이겠지만,
브라우져로 접근해서 사전을 사용할 수 있게 공개했다는 것 자체가
http 프로토콜로 접근해서 해당 데이터를 사용할 수 있게
해놓았다고 보면 비약일까요? 궁금해서 여쭤 봅니다.
---------------------------
Smashing Watermelons~!!
Whatever Nevermind~!!
Kim Do-Hyoung Keedi
----
use perl;
Keedi Kim
문제가 있을 수도 있겠지요.
그 사전 데이터를 이용하려면 그 페이지에 접근해야 한다. 라는 규정도 만들면 만들수도 있을것 같네요. 해당 사전 데이터를 제공한 곳과, 네이버의 정책에 따라서요. 그 페이지를 봐야 광고 수익을 올릴테니까요.
http를 이용해서
http를 이용해서 접근하는 것 자체가 이미 광고를 보고있는(엄밀히 말하면 광고 데이터를 받은 것)이 아닐까요? http 프로토콜을 사용하면서 웹브라우저로만 접근하라고 한다면 이건 좀 어거지가 아닐까하는 생각이 드네요.
만약 그렇다면 파이어폭스의 adblock이나, 그리스몽키 또는 텍스트 브라우져, 더 나아가서 커스텀 브라우져를 사용하는 사람도 잠재적인 라이센스 위반이 되는 것일까요?
음... 두서가 없네요. :-)
---------------------------
Smashing Watermelons~!!
Whatever Nevermind~!!
Kim Do-Hyoung Keedi
----
use perl;
Keedi Kim
계약 위반이라고 생각하는 사람도 있습니다.
http://whyfirefoxisblocked.com/ 를 보시면 광고차단을 도둑질이라고 비난하고 있습니다.
는 것도 이미 있는 주장입니다. 기상청이 외부에 노출된 파일을 쓰지 말라면서 그랬죠.
무척 길었던 기상청
무척 길었던 기상청 관련 쓰레드도 기억 나는군요. :-)
기상청 쓰레드를 보면서, 재배포가 안되면 내가 일기예보 보고 친구들한테
날씨 이야기하거나 문자로 보내면 위법이라는 건가? 이뭐병...
라는 생각도 했었었죠... ^^
올려주신 링크는 잘 보았습니다.
개인적으로는 거의 억지라고 생각합니다.
야구보다가 공수 바뀔때 다른 채널을 보는 사람은?
집에서 예약녹화 기능을 이용해서 TV 컨텐츠 보는 사람들은?
저런 의견이 대세가 되는 날이 오면
파이어폭스의 에이전트 스트링을 익스플로어와 동일하게
변경해서 써야 하는 일이 올지도 모르겠군요.
익스플로어의 광고 제거 관련 플러그인들도 철퇴를 맞을테구요.
텍스트 브라우져 사용자는 완전 날도둑?? :-(
하지만(지극히 반복적이고, 소모적이고, 지리한 생각일지도 모르겠지만...),
80번 포트를 쓰면서 도둑질이니 라이센스 위반이니 하는 것 자체가
파이어폭스 류의 브라우져가 접근하지 못하게한 것은 비록 웃기지만 이해할 수 있습니다만,
그들의 주장(도둑질!) 자체는 이해하기 힘든 넌센스라는 생각밖에 들지 않네요...
그것이 싫다면 사용자로 하여금 못쓰게 할 것이 아니라
자신들이 커스텀 프로토콜에 커스텀 프로그램을 써야할텐데,
그 비용을 줄이고 엔드유저를 끌어들이기 위해 웹을 선택해놓고,
사용자들보고 도둑질이라고 하다니요. 쩝...
---------------------------
Smashing Watermelons~!!
Whatever Nevermind~!!
Kim Do-Hyoung Keedi
----
use perl;
Keedi Kim
크~ 열심히 숙제(?)를
크~ 열심히 숙제(?)를 하다가 이제 다시 글을 봤습니다. 요새 댓글이 달려도 메일이 안오네요. 저만 그런가;;
일단 많은 사전류 프로그램들이 그런 수난이 있었군요. 몰랐었었습니다. 개인적으로는 잘 쓰다가 공개는 처음이라 그런가... 일단 제 패치 올려주신 spike 님 감사드립니다 :) PyGTK 는 처음이라서 레이아웃이 힘들었는데 ^^;
저도 이 프로그램을 PyGTK 버젼으로 만들면서 제일먼저 본게 오픈API 인데, 앞서 댓글다신 분들처럼 링크만(!) 나와 있어서, 결국 html 파싱을 해야하기 때문에 쓰지 않았습니다. 그런데 라이센스가 걸린다면 오픈API 를 써볼까하는 생각도 드는군요. 공식적으로 하려면 해야할 일이 많다는 걸 깨달았습니다. ㅠ.ㅜ 개인적으로 취미삼아 만드는 건데도 흑.. 일단은 네이버 마크를 달고 계속 진행해 보겠습니다.(그런데 지금 보니 kldp.org 밑에도 네이버 링크가 있네요)
파일을 보면 getDic.py 라고 따로 되어 있는 부분이 일단은 네이버인데, 다른 사전도 플러그인처럼 getDicYahoo.py 처럼 만들까 생각 중입니다.
-----------------------------------------------------------------------
GPL 오픈소스 윈도우용 이미지 뷰어 ZViewer - http://kldp.net/projects/zviewer/
http://www.wimy.com
-----------------------------------------------------------------------
GPL 오픈소스 윈도우용 이미지 뷰어 ZViewer - http://zviewer.wimy.com
블로그 : http://blog.wimy.com
너무 메일이 많이
너무 메일이 많이 발송되어서, 관리자분께서 답글메일 기능을
막아두셨다더군요.
http://kldp.org/node/84205
------------------------------------------
emacs user
------------------------------------------
emacs user
:-) 좋은 프로그램 만드셨군요.
좋은 프로그램 만드셨군요.
한때 윈도즈의 사전 프로그램 같은것을 만들려고
X 프로토콜 쪽을 보던것이 생각나는군요.
Clipboard를 사용하는건 현명했다고 생각이 됩니다. :-)
제 생각으로는 프로젝트를 진행하셔도 괜찮을것 같다는 생각이 듭니다.
이것 저것 생각하다 보면 진행이 어려워지니까요.
대신 네이버에 대한 배려가 필요는 하다고 생각하고요.
(예의상 네이버에서 검색을 하고 있다는것은 표기해줘야 겠지요)
통로가 있으시면 직접 네이버에 물어보면 좋겠지만,
답변이 쉽게 나오지 않을겁니다.
(공식적인 답변은 쉽게 나오기 어렵죠~)
경험상 보통 신경을 안쓸겁니다.
현재 회사에서 신경을 쓰는것은 윈도즈와 다른 경쟁사 입니다.
현재는 오픈소스에 너그러운 편이죠~
네이버 역시 마찬가지라고 생각됩니다.
---


Jabber: lum0320@jabber.org
Lum7671's Weblog
코드를 조금
코드를 조금 고쳤습니다.
self.num_buttons가 굳이 ClipboardExample의 멤버일 필요가 없을 것 같아서 클래스 밖으로 뺐습니다.
데이터를 수정할 때 range대신 enumerate를 활용하도록 고쳤습니다.
self.clipboard_history를 미리 크기만큼 만들 필요가 없을것 같아서 빈리스트로 초기화 했습니다.
중복된 데이터를 걸러낼 때 set()을 쓰도록 고쳤습니다.
타이머로 클립보드 검사 하던것을 클립보드의 내용이 바뀌었을 때 동작하도록 고쳤습니다.
간만에 재밌는 코드 잘봤습니다. :)
----
Do not feed troll!
----
데스크탑 프로그래머를 꿈꾸는 임베디드 삽질러
좋은 프로그램
좋은 프로그램 감사합니다.
나중에 한번 테스트 해볼께요.
wxPython으로 껍데기를 바꾸어 봤습니다.
유용한 아이디어와 툴의 소스 제공에 감사드립니다.
제 데스크탑에 윈도용 PyGTK를 설치하지 않은관계로,
자주 사용하는 wxPython을 사용해서 껍데기를 바꾸어 보았습니다.
제가 쓰는 기능만 빨리 만들어 보려고 하는 바람에
히스토리 기능은 빼고,
클립보드의 내용을 붙이는 기능만 남겨두었습니다.
참고하실분은 가져다 쓰세요. :)
결과물에 줄바꿈을 넣도록 바꿔봤습니다.
네이버 영한사전을 브라우저 없이 사용할 방법을 찾다가 발견했습니다.
다른 분들이 올려주신 패치도 적용 시켰는데, 결과물 포맷이 줄바꿈 없이 나와서 좀 더 보기 쉽게 바꿨습니다.
아주 만족하면서 쓰고 있습니다. ^^