한글 자소분리 JSON -- 파이썬3

글쓴이: 황병희 / 작성시간: 월, 2020/06/01 - 11:06오전
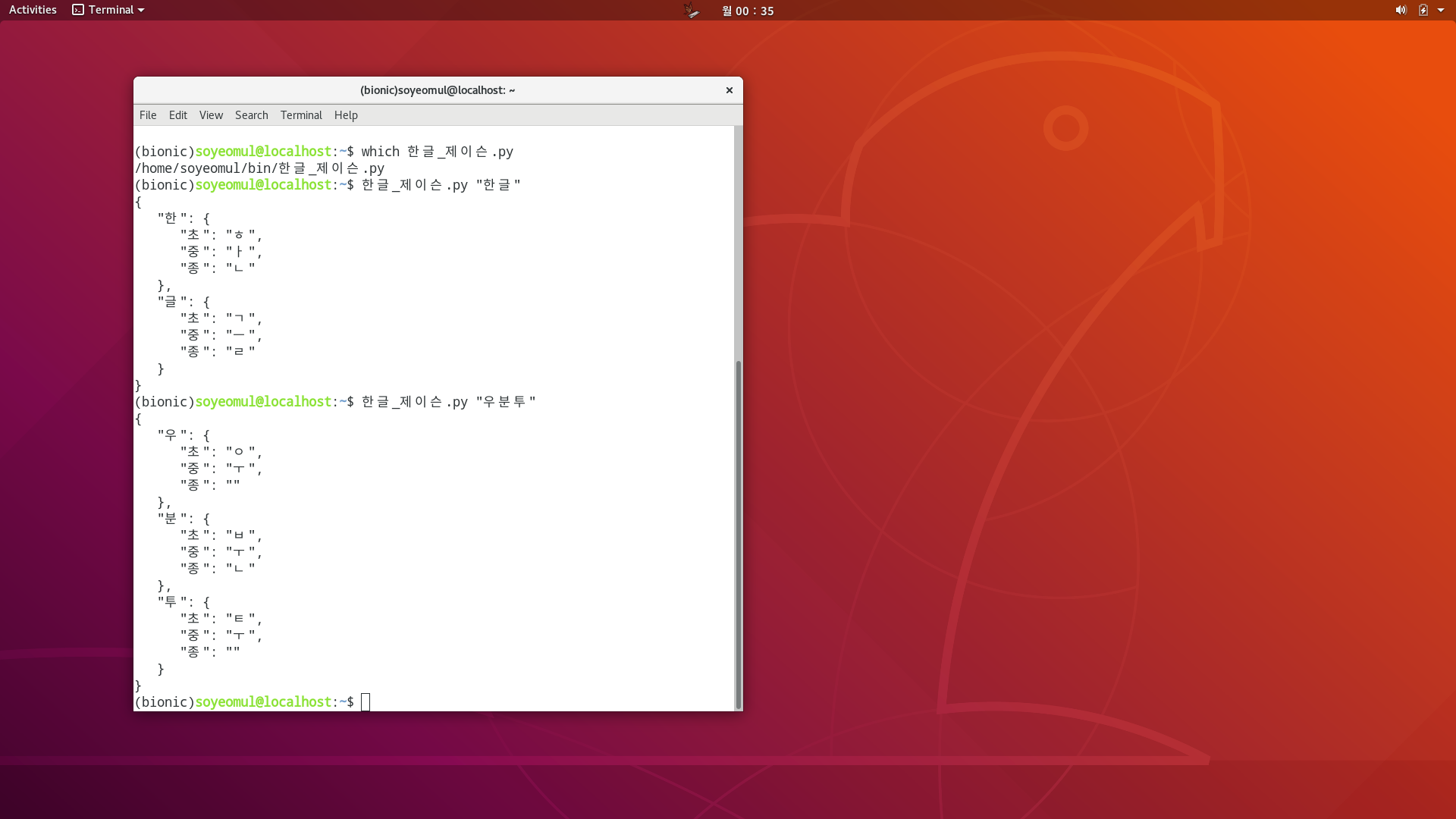
유니코드 한글을 자소를 분리합니다 그리고 JSON 포맷으로 만듭니다
농장 한우 자료 JSON 작업전에 몸풀기로 한번 해봤어요.
좋습니다 아주 좋아요. 이거 코드 작성후 무사히 돌아가는거 확인후,,,
한글창제원리가 너무 좋아요 감사하구요.
그리고 유니코드 만드신분들과 libhangul 만드신분들께 정말 감사드립니다.
아 물론 대왕세종께는 정말 특별한 감사의 마음을 전합니다...^^^
소스코드:
https://gitlab.com/soyeomul/test/-/raw/master/JSON/%ED%95%9C%EA%B8%80_%EC%A0%9C%EC%9D%B4%EC%8A%A8.py
동작 확인 유무는 스크린샷 첨부했습니다.
(구글 검색하시는 분들 위하야 태그도 추가합니다)
(우분투 한국 자료실에도 올렸어요~)
파이썬3 드림
태그: 한글, 유니코드, 자소분리, JSON, 세종대왕
[우분투 18.04 파여폭스 나비에서 적었어요~]
File attachments:
| 첨부 | 파일 크기 |
|---|---|
| 364.04 KB |
{kind=link}
Forums:
유니코드 시대에는 한글 조합/분리 진짜 편하고 한글
유니코드 시대에는 한글 조합/분리 진짜 편하고 한글 오토마타 만들기도 쉽습니다.
한글 창제하신 세종대왕님은 아마 천재였을 듯^^
감사합니다 호동님^^^ 그리고...
마자요 세종대왕께선 천재 이상이었을거 같아요. 소중한 댓글 감사합니다 호동님^^^
그리고 유니코드 한글 자소 분리 C언어(리눅스)를 구현해볼까 하다가 검색해보니 돌고돌아 KLDP 에서 역시나 있었어요.
우분투 쓰시는 한 익명님께서 작성하신 코드를 링크로 남깁니다. 훗날 한글 자소 분리 문제로 다른분들도 또다시 체력을 낭비하지 않도록요~^^^
### 한글 자소 분리 C언어 (리눅스 -- UTF-8) ###
### 날짜: 2017년 1월 20일 (익명님 작성) ###
===> https://kldp.org/comment/621153#comment-621153
(우분투 18.04 LTS 에서 실험해보니 코드 잘 동작합니다 감사합니다)
태그: 유니코드, 한글, 자소분리, UTF-8, 우분투, 리눅스, C언어, 세종대왕, 익명님 고마워요^^^
[크롬북에서 적었습니다]
--
^고맙습니다 감사합니다_^))//
그거 공식 무지 쉬워요
그거 공식 무지 쉬워요
ucs 넣고, 결과 나오면 ucs to utf8 함수로 바꿔주고 출럭하면 되요.
https://www.unicode.org/reports/tr15/tr15-18.html#Hangul
Common Constants static final int SBase = 0xAC00, LBase = 0x1100, VBase = 0x1161, TBase = 0x11A7, LCount = 19, VCount = 21, TCount = 28, NCount = VCount * TCount, // 588 SCount = LCount * NCount; // 11172 Hangul Decomposition public static String decomposeHangul(char s) { int SIndex = s - SBase; if (SIndex < 0 || SIndex >= SCount) { return String.valueOf(s); } StringBuffer result = new StringBuffer(); int L = LBase + SIndex / NCount; int V = VBase + (SIndex % NCount) / TCount; int T = TBase + SIndex % TCount; result.append((char)L); result.append((char)V); if (T != TBase) result.append((char)T); return result.toString(); }아이고 호동님 농사꾼 눈에는 C언어가 허블나게
아이고 호동님 농사꾼 눈에는 C언어가 허블나게 어렵습니다,,,
헌데 위에 예제로 주신 코드는 파이썬의 append 함수 처럼 참 미묘한 문법이 있사온데,,,
파이썬은 아닌거 같은데... C언어 인가요 자바인가요... 진짜 궁금해서 여쭤봅니다,,,
파이썬3 드림
[우분투 18.04 파여폭스 나비에서 적었어요~]
--
^고맙습니다 감사합니다_^))//
해결했습니다...;;;
전 호동님이 올리시면 다 C언어 아님 루비인줄 알았는데...
자바 코드였다는걸 원문 보고 알았어요. 소중한 댓글 다시한번 감사드려요^^^
[우분투 18.04 파여폭스 나비에서 적었습니다]
--
^고맙습니다 감사합니다_^))//
한글 초성이 없는 글자들은 어떻게 분리하는지 아시나요?
한글 초성이 없는 글자들은 어떻게 분리하는지 아시나요?
https://charset.fandom.com/ko/wiki/%EB%AF%B8%EC%99%84%EC%84%B1_%ED%95%9C%EA%B8%80
미완성 한글들이요
초성이 없는 글자들이 많이 쓰인다면 또다시 필요성에
초성이 없는 글자들이 많이 쓰인다면 또다시 필요성에 의해 아마 만들어질거 같아요...
뭐든지 필요성에 따라 코드가 생산되는거 같다는 생각이 드네요,,,
도움 못드려 죄송해요~
[우분투 18.04 파여폭스 나비에서 적었어요~]
--
^고맙습니다 감사합니다_^))//
그거는 그냥 유니코드 나열해놓은거에요.
그거는 그냥 유니코드 나열해놓은거에요.
폰트가 한글자로 보이게끔 설계되어 폰트렌더링 라이브러리에서 처리를 해줘서 한 글자로 보이는거에요.
그래서 특별한 분해 공식은 없어요.
루비 쓰시면
"문자열".unpack("U*") 하면 유니코드 문자 낱개로 풀려요.
"ᅟᅡᆬ".unpack("U*").each { |ch
즉 유니코드 문자, U+115f, U+1161, U+11ac 를 출력하면 한개 문자처럼 보여요. gedit 에 문자 하나씩 복붙해도 되고요.
그러나까 "가"라는 문자는 유니코드로 ac00 이렇게 되지만, 조합 방식으로 문자를 조합하면 3개 유니코드로 이루어져 있고 그거는 ac00이 아니죠.
그냥 검색하다가 역시 돌고돌아 KLDP 에 어마무시한
그냥 검색하다가 역시 돌고돌아 KLDP 에 어마무시한 물건이 있어서 링크를 남깁니다.
보존 연구 가치가 있다 생각되었어요. libhangul 만큼 한글에 관한 훌륭한 자산이라 생각합니다.
(소스코드 곳곳에 유니코드와 한글의 깊은 고민이 녹여져 있어서 보기만 해도 흐뭇했네요^^^)
(아 그리고 이 글타래 주제 -- 한글 자소분리 -- 와 깊은 관련이 있어서 추가합니다)
### 한글 정규 표현식 라이브러리 (hre) ###
https://kldp.org/node/67773 (만들기전 논의)
https://wiki.kldp.org/wiki.php/hre (사용 안내서)
http://kldp.net/hre/release/ (소스코드 내려받기)
[우분투 18.04 파여폭스 나비에서 적었어요~]
--
^고맙습니다 감사합니다_^))//
11172 자 다 분리해봤어요 ;;;
막연히 이 분리한 JSON 파일이 어데선가[***] 쓰일거 같은 예감이 들었어요.
그래서 분리해봤어요. 파일로 첨부합니다 -- 원본파일[11172.json] ;;;
유효 범위는
"가(0xAC00)" ===> 첫 글자
"힣(0xD7A3)" ===> 마지막 글자
입니다.
아래 첨부파일은 웹브라우저에서 UTF-8(유니코드) 로 열어야 제대로 보입니다.
그리고 포맷 유효성 체크는 아래 스크립트로 했어요.
[***] 한글 입력기 연구 및 유니코드 한글 구조 분석 등등 ;;;
[우분투 18.04 파여폭스 나비에서 적었어요~]
--
^고맙습니다 감사합니다_^))//