파이썬 크롤링 질문입니다
글쓴이: overflowww / 작성시간: 목, 2017/07/06 - 6:52오후
def get_link_from_news_title(page_num, URL, output_file):
for i in range(page_num):
currunt_page_num = i+1
position = URL.index('page=')
URL_with_page_num = URL + str(currunt_page_num)
source_cord_from_URL = urllib.request.urlopen(URL_with_page_num)
print(source_cord_from_URL)
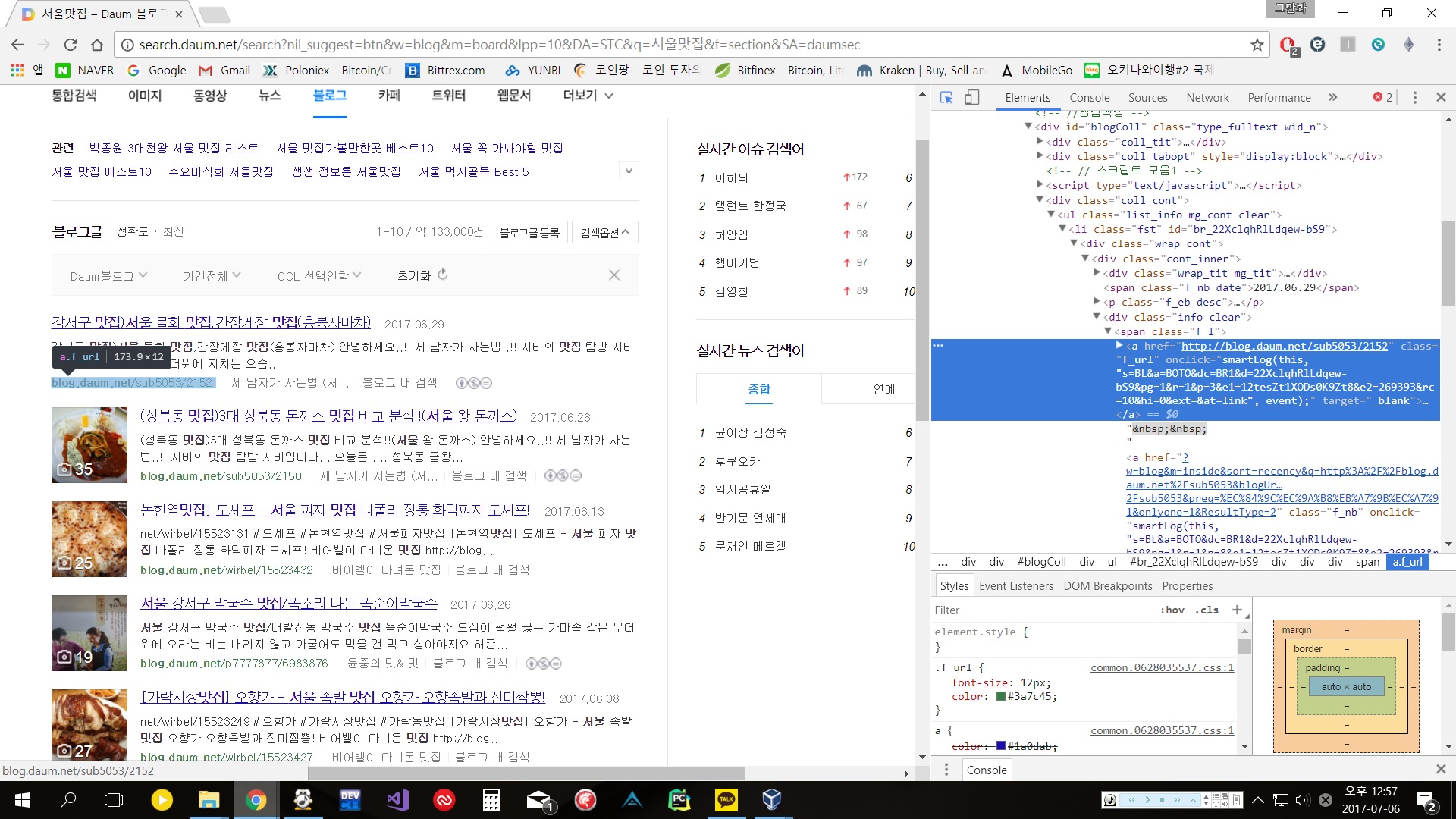
soup = BeautifulSoup(source_cord_from_URL, 'lxml', from_encoding='utf-8')
for title in soup.find_all('span', 'f_l'):
title_link = title.select('a')
article_URL = title_link[0]['href']
print(article_URL)
get_text(article_URL, output_file)
이 방식으로 현재 페이지의 URL을 얻어오려고 하는데요
urlopen까지는 정상적으로 동작하는데
두번째 for문에 진입을 못하네요
어떤점이 문제인지 알 수 있을까요
File attachments:
| 첨부 | 파일 크기 |
|---|---|
| 597.04 KB |
{kind=link}
Forums:
댓글 달기