유니코드는 한 문자에 한 코드만을 부여하지 않았습니다.
글쓴이: 익명 사용자 / 작성시간: 화, 2009/05/05 - 12:53오후
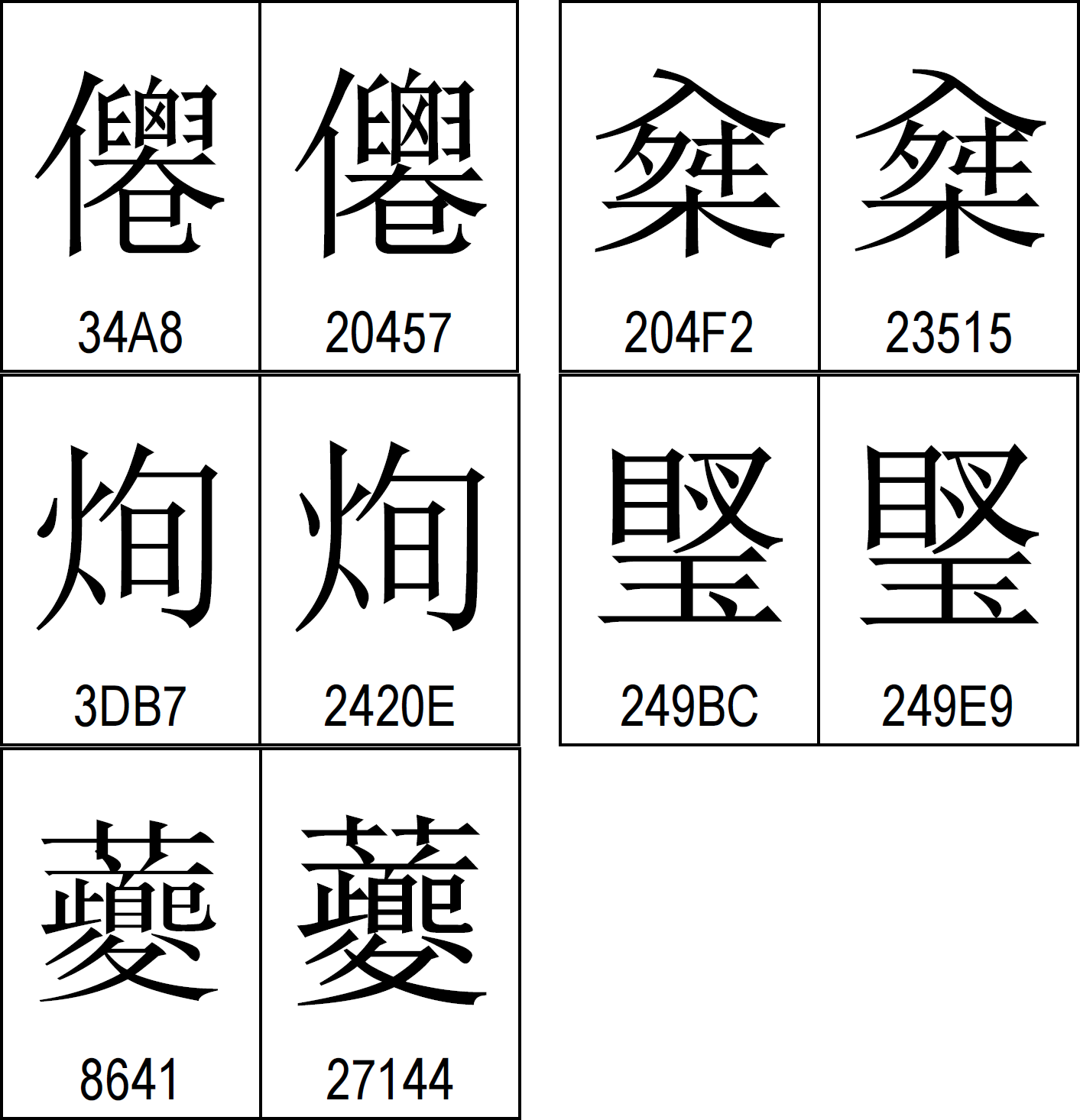
아래 그림을 보세요. 호환용 한자라면 모를까 정규 영역에 이런 오류가 있다는 건…
File attachments:
| 첨부 | 파일 크기 |
|---|---|
| 136.42 KB |
{kind=link}
Forums:
아래 그림을 보세요. 호환용 한자라면 모를까 정규 영역에 이런 오류가 있다는 건…
| 첨부 | 파일 크기 |
|---|---|
| 136.42 KB |
오류라기 보다는 각
오류라기 보다는 각 나라에서 만들어 쓰던 코드를 그대로 가져올 수 있도록 놔둔것이 아닐까요?
한국어도 같은 글자에 해당하는 영역이 두군데라고 알고 있습니다.
emerge money
http://wiki.kldp.org/wiki.php/GentooInstallSimple - 명령어도 몇 개 안돼요~
http://xenosi.de/
https://xenosi.de/
KS C 5601에 있었던
KS C 5601에 있었던 중복 한자들은 이미 호환용 한자 영역에 따로 배당되어 있습니다. 하지만 위 그림에 나온 한자들은 호환용 한자들이 아니며, 정규 영역에 배당돼 있습니다.
저는 '한글'영역을
저는 '한글'영역을 언급한 것이었습니다.
emerge money
http://wiki.kldp.org/wiki.php/GentooInstallSimple - 명령어도 몇 개 안돼요~
http://xenosi.de/
https://xenosi.de/
사실 한글은 네
사실 한글은 네 군데에 배당돼 있습니다.
1. 첫가끝
2. 호환용 자모
3. 한글 글자 마디
4. 반각 한글 자모
반각을 제외하고,
반각을 제외하고, 첫가끝(ㄱㄴㅏㅑ 등 각 자소를 표현하는 영역 맞죠?) 를 제외하고,
'같은 한글을 표현하는 영역' 은 두군데가 맞죠?
이 역시 기존의 방식을 유지하기 용이하도록 완성형과 조합형을 기준으로 한다고 알고 있습니다.
emerge money
http://wiki.kldp.org/wiki.php/GentooInstallSimple - 명령어도 몇 개 안돼요~
http://xenosi.de/
https://xenosi.de/
....
글자 자세히 보시면 완전히 똑같은 글자가 아닌데요.
송효진님 말씀대로 호환을 위해서 그런것 같네요.
ftp://ftp.unicode.org/Public/
ftp://ftp.unicode.org/Public/UNIDATA/Unihan.zip
링크한 Unihan DB를 참고해 보세요.
유니코드는 glyph가 아니라 character를 정하는 표준입니다.
글자의 모양을 따지는 것은 별 의미가 없다고 봅니다.
모두 다른 (비슷하게
모두 다른 (비슷하게 생기긴 했지만) 문자입니다. Unihan database를 조금만 찾아 보셨더라면 이런 얘기는 나오지 않았을텐데요. 좀 더 자세하게 말해 보자면...
예를 들어 맨 처음 예의 U+34A8과 U+20457은 문자가 유래한 출처(IRG sources)가 다릅니다. T-source, 그러니까 대만쪽 자료에서는 둘이 CNS 11643 plane 7 0x574C과 plane 4 0x662F에 배당되어 있고, G-source, 그러니까 중국쪽 자료도 한쪽은 GB7590 0x3329이고 다른 한쪽은 강희자전이 출처네요. 더 황당한 것은 아래에 강희자전 인덱스(IRG indices의 KangXi)를 보니 plane 2에 추가된 것이 본래 강희자전에 있던 거고, BMP에 있던 건 강희자전에는 없지만 만약 들어갔다면 다른 문자로 취급되는 (제가 강희자전에서 소팅을 어떻게 하는진 몰라서 잘 모르겠지만 위치를 보니) 문자네요. 한어대자전(Hanyu Da Zidian) 쪽도 두 문자가 서로 붙어 있는 것 같긴 하지만 하여튼 다른 문자로 나오고 있습니다.
아마 두 문자는 원래 강희자전에 없는 form이 먼저 들어 갔다가 호환을 위해 추가된 것 같습니다. G-source에서 KX라고만 쓰여 있는 걸 보니 심증이 더 굳혀지는군요. 하여튼 이건 "필요해서" 추가된 거지 버그라고 할 수는 없습니다. 그리고 만약 진짜 버그면, 여기가 아니라 유니코드 쪽에 먼저 연락을 해야 하는 게 아닌가 싶군요.
(덤: 이 글에 있는 내용이 혹시 틀렸다면 알려 주시면 감사하겠습니다.)
http://std.dkuug.dk/JTC1/SC2/
http://std.dkuug.dk/JTC1/SC2/wg2/docs/n2644.pdf
사실 알려져 있었던 문제입니다.
귀찮아서 찾아 볼
귀찮아서 찾아 볼 생각은 못 했는데 defect report가 따로 있었군요. 그런데 30분 동안 좀 자료를 들춰 보니까 유니코드 표준에 찍혀 나올 대표 글리프가 틀리거나 (자주 있는 일이죠) 호환성을 위해 필요한 경우라 아주 심각하게 틀린 건 아닌 것 같습니다. 제가 추측한 게 틀린 게 아닌가 하고 심각하게 고민하고 있었는데 다행히 그건 아니었군요. -_-;;;
제가 예를 든 문자를 포함한 두 문자는 BMP에서는 합쳐진 문자가 SIP에서는 갈라져 나오는 도중 잘못된 글리프를 쓴 거고, 나머지 세 개 중 U+204F2와 U+23515는 애초에 강희자전과 한어대자전 모두 다른 문자로 처리하고 있습니다. (아마도 사람 인 人과 들 입 入의 차이겠죠?) 나머지 두 개가 진짜 "중복"이라고 할만한 것 같은데 일단 등록이 된 이상 별로 손 쓸 방법은 없으니 저기서는 그냥 가능한 것들은 글리프를 살짝 바꾼 다른 (알려진) 문자로 매핑해서 해결해 버리자는 제안을 하는 걸로 보입니다. 재매핑을 하자는 글리프를 보니 점 하나가 차이나는 걸로 봐서 Han unification에서 충분히 갈라져 나올 만한 문자들이군요.
이거 뒤져 보면서 계속 느끼는 점인데 유니코드에서 한자 관련된 부분은 두고 두고 문제거리로 남는 것 같습니다. 애초에 Unihan database도 너무 복잡하고 꾸준히 버그도 잡고 있는 걸 보면요. 그나저나 몇 해 전에 kKorean 필드에 쓰인 한글 로마자화가 뭣같다는 얘기가 나왔는데 덕분에 5.0에서는 유니코드 문자인 kHangul이 추가되었군요.
예를들어, 한국어,
예를들어, 한국어, 일본어, 중국어도 모두 한자를 쓰는데 한자가 한영역에만 있는게 아니라
한국한자, 일본한자, 중국한자, 다 따로 있는걸로 압니다.
그러므로 비슷해 보이는 한자들이 있는건 당연한게 아닐가요?
=========================
CharSyam ^^ --- 고운 하루
=========================
=========================
CharSyam ^^ --- 고운 하루
=========================
그게 유니코드에서는
그게 유니코드에서는 Han unification이라고 해서 glyph가 살짝 다른 웬만한 문자는 다 합쳐 버렸습니다. 아주 최근에야 같은 문자라도 서로 다른 glyph로 보여 주는 방법이 생겨서 그나마 상황이 나아졌지만, 처음에는 상당히 논란이 컸다고 알고 있습니다. 하지만 다른 문자셋과의 호환성을 위해 일부러 그 원칙을 적용하지 않은 경우가 있지요.
lifthrasiir 님의 말씀에
lifthrasiir 님의 말씀에 덧붙이자면,
直 이 한자는 사실 두 글리프의 unification입니다. (중국어 글꼴로 바꿔 보시면 알 수 있습니다.)
아마도...
위의 한자들의 경우에도 적용되는 것인지는 잘 모르겠지만, 어떤 한자들의 경우에는 한자 하나에 음이 2개인 경우도 있는데, 그 경우에는 위의 경우처럼 같은 한자에 두 개의 코드를 배당하는 것으로 알고 있습니다. 예를 들면, 자동차할 때, '차'라는 한자는 수레 '거'로 읽을 때도 있쟎습니까? 아마도 한자를 정렬할 때 발생할 수 있는 문제를 염두에 두고 코드를 배정한 때문이 아닌가 하는 생각이 듭니다.
KS C 5601에 있었던
KS C 5601에 있었던 중복 한자들은 이미 호환용 한자 영역에 따로 배당되어 있습니다. 하지만 위 그림에 나온 한자들은 호환용 한자들이 아니며, 정규 영역에 배당돼 있습니다.
비효율을 감안하고 호환성에 중점을 둔 듯 합니다
저도 잘 몰랐던 사항이라서 좋은 정보를 얻는 기회가 되었습니다.
넓어진 영역을 효율적으로 쓰는 대신 중복 가능성을 감안하더라도 CJK 언어권의 미묘한 글자 표현이나 해석에 대한 호환성을 더
중점적으로 생각했다... 이렇게 보는 것이 옳을듯 합니다.
=================================
이 세상은 썩어있다!
- F도 F시 시가지 정복 프로젝트
=================================
이 세상은 썩어있다!
- F도 F시 시가지 정복 프로젝트
홈페이지: 언더그라운드 웹진 18禁.net - www.18gold.net