재미있는 놀이: C, Python, Erlang으로 50000! 해보기 #1

#1. 시퀀셜
난 사실 리컬시브니 디바이드앤 퀀커니 하는 이런저런 기법과 알고리즘을 잘 못한다. 머리가 나빠서인게 가장 큰 이유이고 오류가 없는 코드는 가장 단순한 코드라는 확실한 믿음 때문이다. 코드의 특정 부분에서 성능 최적화를 '반드시'할 필요가 있을 때에나 이런 저런 시도를 하면서 코드에 여러 기법들을 적용해 보지만 어지간해서는 기본적인 문법과 기본적이고 직관적인 코드 이상은 잘 작성하지 않는다.
프로그래밍 언어론에서 프로그래밍 언어의 요소를 구분할 때 일반적으로 반복문, 제어문, 산술문 정도로 구분한다. 그중 반복문은 전체 프로그램의 성능에 가장 큰 영향을 미치는 부분이다. C언어라면 대표적으로 for문과 while문이 있다.
문법에서 제공하는 반복문을 사용하는 방법 말고 반복(루프, loop)을 구현하는 다른 방법으로는 리컬시브가 있다. 이 글을 읽는 사람들 중 리컬시브가 뭔지 모르시는 분들은 얼른 공부하고 오시길 바란다. 리컬시브로 구현한 50000!은 다음 시간에~^^
이번 글에서는 for문의 단순 반복문으로 50000!을 계산하는 코드를 각각 C언어, 파이썬, 얼랭으로 작성하고 다음 세 가지를 측정할 것이다.
1. 쉘에서 time 명령으로 측정한 시간.
2. 핵심 계산함수의 실행시간만 time 라이브러리를 사용해 측정
3. 멀티코어 시스템에서 각 코어를 어떤식으로 사용하는지 확인
1번처럼 쉘의 time 명령으로 아주 쉽게 실행 시간을 측정할 수 있지만, 2번처럼 별도의 코드를 더 삽입해서 코딩하는 이유는 파이썬이나 얼랭같은 인터프리터 기반 스크립트 언어는 쉘에서 직접 실행할 때에 인터프리터가 로딩되는 시간이 추가로 들어가기 때문이다. 인터프리터의 로딩시간을 제외한 순수 계산 시간만을 뽑아내기 위해 2번의 시간을 추가로 더 측정한다. 3번을 보는 이유는 멀티코어 시스템이 기본이 된 요즘 세상에 언어적으로 아무것도 안해줘도 알아서 멀티코어를 잘 써주는지가 궁금했기 때문이다.
-C언어 시퀀셜-
C언어로 단순 for문을 돌면서 50000!을 계산하는 코드는 앞서 프롤로그에서 썼던 것처럼 빅넘버를 표시하기 위한 별도의 라이브러를 추가로 사용해서 만들었다. 일단 코드를 먼저 보자.
#include <stdio.h>
#include <gmp.h>
void factorial(mpz_t* f, unsigned int n)
{
unsigned int i = 1;
for (i = 1; i <= n ; i++){
mpz_mul_si(*f, *f, i);
}
}
int main(int argc, char **argv)
{
mpz_t facN;
unsigned int n = 50000;
clock_t start, end;
double runtime;
mpz_init(facN);
mpz_set_ui(facN, 1L);
factorial(&facN, n);
printf("fac %u is ", n);
mpz_out_str(stdout, 10, facN);
printf("\n");
mpz_clear(facN);
}원래는 factorial() 함수의 리턴으로 mpz_t 타입을 넘겨서 보다 진정성(?)있는 타입으로 사용하고자 했으나, 뭔가 잘 안되었다. 아무래도 mpz_t 타입은 구조체일테고 구조체는 그냥 넘기기 보단 포인터로 넘기는 것이 좋다. 그런데 mpz_t 타입은 init와 clear를 명시적으로 해 줘야 하는 녀석이다. 다시 말해서 명시적으로 자원의 할당과 해제를 해 줘야 하는 녀석이다. 따라서 나는 그냥 파라메터로 포인터를 넘기기로 결정했다. 그렇게 되면 함수를 호출하는 쪽에서 자원의 할당과 해제를 책임지면 되고, 함수 내부에서는 그냥 포인터를 사용하기만 하면 되긴 때문이다.
gcc로 빌드는 아래처럼 한다.
gcc -oc_fac_seq c_factorial_gmp.c -lgmp
파일명은 c_factorial_gmp.c이고 libgmp를 사용했으므로 -lgmp를 붙였다.
상당히 간단하고 짧은 코드이지만 이 코드를 작성하기 위해서 다음의 작업을 했다.
1. C언어에서 빅넘버를 지원하는 라이브러리는 무엇인가?
-> libgmp, libbign
2. 이중 어떤게 더 유명하고 공신력이고 안정적이며 더 많이 사용하는가?
-> libgmp
3. libgmp의 tutorial이나 howto문서나 referrence menual을 검색
-> 구글 짱!
4. libgmp를 사용한 간단한 짧은 example code 검색
-> 오오!! 구글!! 오오!!
5. 검색한 내용을 바탕으로 내가 필요한 코드를 작성
6. 빌드와 테스트
이 작업을 하는데 1번에서 4번까지 거의 한 시간 넘게 소요되었고 5번과 6번 작업은 약 오 분정도 걸렸다. 구글은 위대하다.(...)
"구글이 없던 시절에 소프트웨어 개발자는 어떻게 개발했을까..? 네비 없던 시절 운전은 어떻게 했는데!?"
일단 결과값을 텍스트 파일로 저장해 놓는다. 이것은 나중에 파이썬과 얼랭으로 작성한 50000!의 결과와 비교하기 위함이다.
$ ./c_fac_seq > c_seq
그리고 소스 코드에서 결과 값을 출력하는 코드를 제거한다. 제거하는 이유는 계산 시간보다 stdout으로 결과를 출력하는 시간이 더 길기 때문에 쉘 명령어인 time 명령으로 시간을 측정할 때 stdout 출력 시간이 모두 포함되어 나오기 때문이다. 물론 코드 안에서 time 라이브러리로 실제 factorial() 함수의 수행시간만 계산하고 있기도 하지만 여러번 테스트할 때 터미널에 가득찬 숫자의 향연이 계속되면 눈이 쉽게 피로해지고 정신이 혼미해진다.
수정한 코드는 아래와 같다.
#include <stdio.h>
#include <gmp.h>
#include <time.h>
void factorial(mpz_t* f, unsigned int n)
{
unsigned int i = 1;
for (i = 1; i <= n ; i++){
mpz_mul_si(*f, *f, i);
}
}
int main(int argc, char **argv)
{
mpz_t facN;
unsigned int n = 50000;
clock_t start, end;
double runtime;
mpz_init(facN);
mpz_set_ui(facN, 1L);
start = clock();
factorial(&facN, n);
end = clock();
//printf("fac %u is ", n);
//mpz_out_str(stdout, 10, facN);
//printf("\n");
runtime = (double)(end-start) / CLOCKS_PER_SEC;
printf ("runtime is %f\n", runtime);
mpz_clear(facN);
}이제 시간을 측정해 본다. 쉘의 time 명령과 같이 사용하면 된다.
$ time ./c_fac_seq runtime is 1.360000 real 0m1.371s user 0m1.368s sys 0m0.000s
"예상보다 빠르다..."
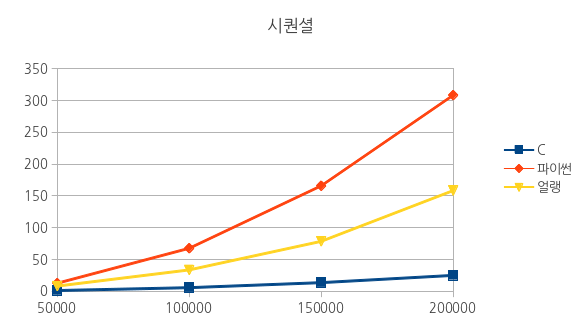
그래서 각각 50000!, 100000!, 150000!, 200000!을 수행하고 시간을 측정했다.
$ time ./c_fac_seq fac 50000! runtime is 1.360000 real 0m1.374s user 0m1.368s sys 0m0.004s ======================== $ time ./c_fac_seq fac 100000! runtime is 5.870000 real 0m5.878s user 0m5.872s sys 0m0.004s ======================== $ time ./c_fac_seq fac 150000! runtime is 13.720000 real 0m13.750s user 0m13.733s sys 0m0.000s ======================== $ time ./c_fac_seq fac 200000! runtime is 25.150000 real 0m25.480s user 0m25.134s sys 0m0.032s
당연히 숫자가 올라갈 수록 계산 시간은 길어진다. 숫자가 커질 수록 당연히 전체적으로 지수함수적인 증가세가 눈에 보인다.
그리고 각 팩토리얼을 계산할 때에 CPU를 어떻게 사용하는지 확인해 봤다. 나는 구입한지 3년이 넘어가는 코어2듀오 시스템에 우분투 리눅스를 사용하고 있다. 그래서 우분투 리눅스에 기본으로 포함되어 있는 시스템 감시 프로그램을 실행해서 CPU 사용 내용을 보면 코어가 두 개 표시된다.

코어가 두 개이긴 하지만, 프로그램 안에서 별다른 처리를 하지 않았기 때문에 나는 코어 중 한 개만 사용할 것으로 예상했다. 대체적으로 예상은 맞아 떨어졌다. 다만 신기한것은 계산 시간이 길면 두 코어가 번갈아가면서 일을 하는 양상을 보인다는 것이다. 이 역시도 어느 한 시점에서는 두 개의 코어 중 한 개가 열심히 일을 하고 있는 것으로 해석할 수 있긴 하지만, 두 코어를 알아서 번갈아 사용한다는 점이 신기했다. 커널이 알아서 해주는 것이라고 추정하고 있긴하다.
-파이썬 시퀀셜-
나는 파이썬을 좋아한다. 사..사사.. 아니 좋아합니다! 정말 꼭 반드시 파이썬이 아닌 다른 언어(C, C++, 자바 등..)로 작성해야 하는 프로그램이 아닌 이상 나는 내가 만들어야 하는 모든 프로그램을 전부 파이썬으로 작성한다. 파이썬은 쉽고 빠르고(속도가 빠르다는게 아니다. 코딩이 빠르다. 요즘은 속도도 많이 빨라진것 같다.) 편하고 만족스럽다.
일단 닥치고 코드부터 보자.
def factorial(N):
fac = 1
for i in range(1, N+1):
fac *= i
return fac
n = 50000
facN = factorial(n)
print "fac %d is %d"%(n, facN)코딩하는데 30초 정도 걸렸다. 누가봐도 직관적이고 확실한 코드이다. 파이썬은 언어 자체에서 빅넘버를 처리해주기 때문에 별다른 라이브러리 추가도 안했다. 그냥 된다. 역시 파이썬은 코딩하는 사람의 정신건강도 좋아진다.
사실 조금 더 고민했으면 위 소스는 단 한 줄 짜리로도 만들 수 있다. 하지만 하지 않았다. 왜냐하면 최대한 C언어 및 얼랭 코드와 모양 자체를 비슷하게 유지하고 싶었기 때문이다.
파이썬 코드는 뭐 더 설명할 것도 없다. 일단 값이 맞는지를 확인하자. C언어 버전과 마찬가지로 텍스트 파일에 결과를 저장한다.
$ python pytyon_factorial.py > p_seq $ diff c_seq p_seq
앞서 저장했던 C언어 시쿼셜 버전의 결과 파일인 c_seq와 방금 작성한 파이썬 시퀀셜 버전의 결과파일인 p_seq를 diff로 비교했다. 아무런 출력도 나오지 않았다. 동일하단 뜻이다. 이 결과로 다음의 결론을 내릴 수 있다.
* p_seq가 정답이고 c_seq를 검증했다.
* c_seq가 정답이고 p_seq를 검증했다.
* p_seq와 c_seq 모두 정답이다.
* p_seq와 c_seq가 모두 답이 아니지만 우연치 않게 그냥 같은 값이 나왔다.
"그냥 뻘소리다...-_-"
위 코드에서 factorial() 함수의 수행시간만 측정하기 위한 코드를 삽입하였다.
import time
def factorial(N):
fac = 1
for i in range(1, N+1):
fac *= i
return fac
n = 50000
start = time.time()
facN = factorial(n)
print "runtime is %s"%(time.time() - start)파이썬의 time 라이브러리를 import해서 사용했다. C언어에서는 clock() 함수를 사용했는데, 검색을 해 보니 파이썬에서는 time.clock() 함수보다는 time.time() 함수를 쓰는 것이 더 정확하다고 한다.
50000!의 결과를 쉘 명령어 time을 사용해서 측정한 값과 비교해봤다. stdout 출력이 없기 때문에 쉘 명령어 time의 값과 코드에서 출력하는 값의 차이는 파이썬 인터프리터(혹은 VM)의 로딩과 클로징에 소비되는 시간일 것이다.
$ time python python_factorial.py runtime is 12.8843169212 real 0m12.937s user 0m12.645s sys 0m0.164s
파이썬의 factorial() 함수를 처리하는 데에 걸린 시간은 순수하게 12.88초 정도이고, time 명령으로 측정한 real 시간이 12.93초이니 약 0.1초 정도가 파이썬 인터프리터(혹은 VM)을 로딩하는데 사용되었다고 해석할 수 있다. 그냥 이 결과로 봤을 때 파이썬은...
"C언어 보다 10배 느리다..."
오래전에 파이썬을 처음 접했을 무렵에는 파이썬이 C언어보다 100배 느리다고 했었는데, 10배 느려진것 보니 10년 동안 파이썬은 무려 10배의 속도를 개선했다! (오오!! 파이썬!! 오오!!)
마찬가지로 50000!, 100000!, 150000!, 200000!을 계산해 봤다.
time python python_factorial.py runtime is 12.8843169212 real 0m12.937s user 0m12.645s sys 0m0.164s ======================== $ time python python_factorial.py runtime is 67.7613689899 real 1m7.813s user 1m4.712s sys 0m2.832s ======================== $ time python python_factorial.py runtime is 165.921977043 real 2m45.981s user 2m36.282s sys 0m8.613s ======================== $ time python python_factorial.py runtime is 308.272175074 real 5m8.319s user 4m48.654s sys 0m18.341s
아.. 정말 C언어의 위엄이 느껴지는 기다림이었다. 마지막 200000! 계산은 무려 300초가 넘게 걸렸다. 뭔가 정확한 측정을 해야 한다는 강박관념에 이 300여초 동안 난 아무것도 안하고 모니터만 바라보고 있었다. 혹시라도 웹서핑 같은거 하다가 계산시간이 길어지거나하면 안되니까.. 5분이란 시간이 짧은 것 같지만 아무것도 안하고 있으면 꽤나 긴 시간이다.
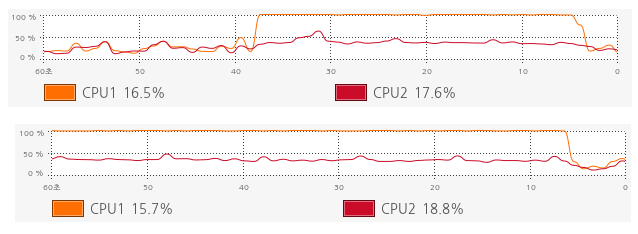
파이썬 시퀀셜 프로그램의 CPU 사용 그래프는 아래와 같다.

실험은 네 개를 했지만 그림은 두 개를 붙인 이유는 1분이 넘어가는 150000!, 200000! 모두 양상이 100000!과 같기 때문이다. C언어 시퀀셜 프로그램을 측정할 때도 나왔던 양상이지만 계산 시간이 길어지면 두 코어가 번갈아가면서 계산을 하는 모습을 볼 수 있다.
-얼랭 시퀀셜-
얼랭은 for문이 없다. 태생이 함수형 언어라 그런것 같기도 하고 전반적으로 얼랭의 언어 컨셉이 for문이 필요하지 않기도 하기 때문이다. 하지만 본 실험에서는 뭔가 for문이 필요하다. 그렇다고 for문을 만들 수도 없고.. 물론 얼랭 입문서에도 나와 있는 꼼수로 for문 비슷하게 만들 수는 있다. 하지만 그렇게 사용하는 것보다는 최대한 얼랭의 언어 특징에 맞는 방향으로 코드를 작성하고 싶었다. 더욱이 나는 얼랭을 시작한지 3일 밖에 안되어서 얼랭을 뭔가 고급스럽게 사용하질 못한다.
일단 코드를 보자.
-module(erlang_factorial_seq).
-export([start/0]).
start()->
N = 50000,
L = mk_list(N),
mul_list(L).
io:format("fac ~w is ~w~n", [N, F]).
mk_list(0)->[];
mk_list(N)->[N|mk_list(N-1)].
mul_list([])->1;
mul_list([H|T])->H*mul_list(T).최대한 시퀀셜 프로그래밍 비슷하게 하려고 작성한 코드이다. 먼저 mk_list() 함수에서 1부터 N까지 정수 값을 가지는 리스트를 만든다. 파이썬의 range(1,N+1)과 동일한 동작을 하는 것이다. 그리고 mul_list() 함수에서 배열의 각 값을 하나씩 곱한다. 최종 결과는 N!이 된다.
얼랭은 인터프리터 기반 언어임에도 실행하기 전에 컴파일을 해야 한다. 자바랑 비슷하다고 해야 하나.. 그럼 인터프리터 기반이 아니라 VM 기반이라고 해야 하나..-_-; 사실 난 이 둘을 잘 구분 안한다. -_-;; 어찌되었던 뭔가 위에 올라가서 도는 거잖아!!! 만약 이렇게 자유롭게 쓰는 글이 아니라 어디엔가에 돈을 받고 쓰는 글이라면 정확히 써야겠지만 지금은 뭐 그러고 싶지 않다. 지금 나는 내가 이 글을 왜 시작했는지 자체에 대해 후회하고 있으니까(...)
컴파일은 아래와 같이 한다.
erlc erlang_factorial_seq.erl
얼랭을 설치하는 것은 알아서 하시길 바란다. 우분투에서는 클릭 몇 번으로 아주 쉽게 했다. 다른 배포판에서도 크게 다르지 않을 것이라 추정된다. 실행은 조금 명령어가 많다.
erl -noshell -s erlang_factorial_seq start -s init stop
각 옵션의 의미에 대해서도 알아서 찾아보시길 바라며, 이 명령을 수행하면 C나 파이썬일 때와 마찬가지로 결과 값이 stdout으로 쫙~ 나온다. 그걸 이전의 C와 파이썬의 결과값과 비교해보면 제대로 계산했는지 알 수 있다.
$ erl -noshell -s erlang_factorial_seq start -s init stop > e_seq $ diff c_seq e_seq $ diff p_seq e_seq
계산 결과는 당연히 맞다. 그럼 시간을 측정해보자. 얼랭에서는 시간을 측정하기 위해 now()라는 BIF(Built In Function)과 timer 모듈의 now_diff() 함수를 사용한다.
-module(erlang_factorial_seq).
-export([start/0]).
start()->
N = 50000,
Start = now(),
L = mk_list(N),
mul_list(L),
End = now(),
Runtime = timer:now_diff(End, Start) / 1000,
io:format("fac ~w~n", [N]),
io:format("runtime is ~w~n", [Runtime]).
mk_list(0)->[];
mk_list(N)->[N|mk_list(N-1)].
mul_list([])->1;
mul_list([H|T])->H*mul_list(T).now_diff() 함수의 결과값이 마이크로 초이기 때문에 1000으로 나눠서 밀리초로 보이게 했다. 결과는 다음과 같다.
$ time erl -noshell -s erlang_factorial_seq start -s init stop fac 50000 runtime is 8357.16 real 0m9.552s user 0m8.505s sys 0m0.028s
약 8.3초 정도 나온다. 어라! 파이썬보다 빠르다.(...) 이럴 수가! 믿었던 파이썬이.. 50000!에서 파이썬이 거의 12.88초로 거의 13초 가까이 나왔던 것에 비해 얼랭은 8.3초가 나왔다.
"얼랭이 파이썬보다 빠르구나.."
그럼 마찬가지로 숫자를 늘려서 50000!, 100000!, 150000!, 200000!을 계산해 보겠다.
$ time erl -noshell -s erlang_factorial_seq start -s init stop fac 50000 runtime is 8357.16 real 0m9.552s user 0m8.505s sys 0m0.028s ======================== $ time erl -noshell -s erlang_factorial_seq start -s init stop fac 100000 runtime is 33785.222 real 0m34.988s user 0m33.726s sys 0m0.120s ======================== $ time erl -noshell -s erlang_factorial_seq start -s init stop fac 150000 runtime is 78662.255 real 1m19.867s user 1m18.229s sys 0m0.368s ======================== $ time erl -noshell -s erlang_factorial_seq start -s init stop fac 200000 runtime is 158415.692 real 2m39.624s user 2m37.450s sys 0m0.596s
우선 나는 파이썬이 얼랭보다 빠를 줄 알았다. 하지만 얼랭이 파이썬보다 거의 두 배에 가까울 정도로 빨랐다. 이점이 놀라웠다. 그리고 또 놀라운 것은 얼랭은 코어 두 개 중 한 개만 조진다는 것이었다. 아무런 병렬 처리 관련 프로그래밍을 하지 않았으니까 오히려 당연한 결과임에도 C나 파이썬은 코어가 번갈아가면서 작업하는 데, 얼랭은 코어 한 개만 주구장창 작업하는 것에 대해 이유가 궁금했다. 하지만 찾을 수가 없었다.
혹시, 이 글을 읽는 분들 중 이유를 아는 분 계시면 답글 부탁드립니다.
"아.. 진짜 궁금하다..."
-결론-
시퀀셜 프로그램의 결과는 당연 당근 당삼 C언어가 가장 빨랐고, 그다음이 얼랭, 그 다음이 파이썬이었다. 파이썬 인터프리터(혹은 VM?)이 많이 속도를 개선했다고는 하지만 그래도 많이 느렸다. 의외로 얼랭이 빨랐다. 오.. 얼랭 끌리는 걸?
하지만 속도가 전부는 아니다. libgmp 때문이긴 하지만 C언어 프로그램을 작성하는데는 한 시간 가까이 걸렸다. 내가 만약 libgmp의 사용법을 알고 있는 사람이라고 하여도 아마 최소 2~3분 정도는 걸렸을 것이다. 파이썬은 아무런 의심도 의문도 없이 일사천리, 전광석화와 같은 코딩으로 1분이 안걸렸다. 얼랭은 구성에 대한 고민과 아직 익숙치 못한 문법 때문에 약 10여분 가량이 걸렸다. 이후에 내가 얼랭에 익숙해 진다 하여도 코딩 자체에 걸리는 시간이나 프로그래밍을 위하여 코드의 골격을 잡는 시간등을 고려했을 때 역시 파이썬이 가장 쉬운 언어라고 볼 수 있다.
-다음 이야기 예고-
다음 편에는 리컬시브 프로그램을 비교할 예정이다. 왠지 오늘의 결론과 크게 다를 것 같진 않지만, 그래도 그냥 해 본다.
아.. 괜히 시작했어...
| 첨부 | 파일 크기 |
|---|---|
| 47.77 KB | |
| 25.57 KB | |
| 22.49 KB | |
| 19.89 KB |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
댓글
앗.. 1등~방금 전 글 보고.. 와 재밌다 하고
앗.. 1등~
방금 전 글 보고..
와 재밌다 하고 있었는데.. 그 담글이 바로 올라왔네요..
또 그 다음글이 와방 기대 됩니다. >ㅁ<)
--------------------------------------------
:: 누구보다 빠르게 남들과는 다르게
글 잘 읽었습니다. 역시 c 언어가 빠르긴 합니다만,
글 잘 읽었습니다. :) 역시 c 언어가 빠르긴 합니다만, 저도 파이썬 유저로써 빠르게 작성할 수 있는 파이썬이 더 좋은 것 같습니다. :D
그런데 파이썬 2를 쓰시는 것 같은데, range 보다는 xrange를 사용해보세요. range는 리스트를 만들지만 xrange는 객체를 따로 생성해서 메모리 점유 측면이나 속도 측면에서 더 좋은 걸로 알고 있습니다.
(http://docs.python.org/library/functions.html#xrange)
(그래서 파이썬3 에서는 range 작동이 xrange 작동으로 바뀌고, 파이썬2 range를 쓰러면 list(xrange())를 써야 합니다...)
위에서 같은 코드로 range와 xrange 차이만 두고 해보니까 200000!일 경우에 range는 28.248 초, xrange는 27.873 초 가 나오네요.
성능이 약간 좋아서? 별로 차이가 안나보이는데, 예전에 1000000! 을 해볼 때는 차이가 좀 났었습니다.
ps2. 참고로 cpu는 2.26GHz 코어2듀어 펜린입니다.
/*** Signature ******************
* blog: http://blog.bluekyu.me/ *
********************************/
재밌습니다. 얼랭과 파이썬에 대해 궁금했는데 재밌게
재밌습니다.
얼랭과 파이썬에 대해 궁금했는데 재밌게 읽을 수 있어서 아주 좋습니다.
Thanks for being one of those who care for people and mankind.
I'd like to be one of those as well.
재밌습니다... 글 시작한것 후회 마시고 끝까지
재밌습니다...
글 시작한것 후회 마시고 끝까지 부탁드립니다...
나빌레라님의 너스레...
깨알같네요...
recursive를 잘 모른다부터 시작해서... ㅎㅎㅎ
--------
From Buenos Aires, Argentina
No sere feliz pero tengo computadora.... jaja
닥치고 Ubuntu!!!!!
To Serve My Lord Jesus
blog: http://sehoonpark.com.ar
http://me2day.net/sheep
저 진짜 잘 몰라요....^^; 완전
저 진짜 잘 몰라요....^^;
완전 하수임..
본문에 코드 수준만 봐도 완전 초급자 수준이잖아요...ㅎㅎ
----------------------
얇은 사 하이얀 고깔은 고이 접어서 나빌레라
python3 로 돌리니 엄청 빠릅니다.
python3 으로 돌리기 위해 print("....") 괄호만 추가했습니다.
4가지 방법
python 에서 (approximation에 의존하지 않는) 약 4가지 방법이 있는 것 같은데
1) for-loop iteration
2) recursion
3) reduce()
4) math.factorial()
50000! 에서는 다 실행시간이 거의 똑같네요. (recursion은 stack limit 때문에 30000! 정도까지밖에 안되네요)
1) 은 interpreted language 에서 loop overhead 가 크면 느리고
2) 는 stack 만드는것 때문에 느리고
3) 은 reduce 할때마다 부르는 method 가 느리면 느리고
4) 는 c로 (for-loop으로) 쓰여진 function 인데 중간에 "bigint"를 처리하는 부분이 있는데
그럼에도 불구하고 다들 속도가 비슷하단 뜻은 느린 속도의 주범이 "bigint" 를 곱하는 것 때문인듯 하군요.
그런데 python3가 빠른 것은 꽤 인상적이네요. 일반적으로 더 느리다고 들었는데 이 경우는 빠른가 보군요.
그리고 python 이나 erlang 같은 것은 병렬 버전을 만들기 쉬울텐데 병렬 버전을 만들면 속도가 얼마나 빨라질 수 있는지 비교해보는것도 좋을 것 같네요.
곱하는 순서
그리고 1부터 N 까지 곱하는 것보다 N 부터 1까지 곱하는게 빠르네요.
100000! 의 경우 제 랩탑, python 에서 1부터 곱하면 34 초가 걸리고
N부터 곱해 내려가면 27초가 걸리네요.
python 이외에 scala 에서 테스트 해봐도 비슷한 정도의 성능 향상이 있군요.
3줄짜리 Java 코드로도 가능하죠
import java.math.BigInteger;
public class Test {
public static void main(String[] args) {
BigInteger accumulator = new BigInteger("1");
for (int i = 2; i <= 50000; i++)
accumulator = accumulator.multiply(new BigInteger("" + i));
}
}
제 Machine 에서 별다른 옵션없이 실행한 결과 2.9초 정도 걸리는군요 ㅎㅎ
i3-2100 3.1GHz
Windows 7
제 노트북(i5 m540, ddr3 4GB)에서
제 노트북(i5 m540, ddr3 4GB)에서 돌려보니 파이썬으로 20000!은 19초정도 나오는데 c#으로 돌리니까 1분 하고도 14초 씩이나 걸리네요. .net 4.0에 포함된 아마도 BigInteger 타입에 성능 이슈가 있지 않나 생각하고 있습니다만, 시간 내서 이놈 소스 좀 뜯어봐야겠네요. 자바도 함 돌려봐야겠어요. 이거 뭥미~
추가. x64로 컴파일 했을 경우엔 40초 걸립니다.
테스트 해본 C# 소스코드는 다음과 같습니다.
using System; using System.Numerics; namespace ConsoleApplication1 { class Program { static void Main(string[] args) { int n = 200000; DateTimeOffset dtStart = DateTimeOffset.Now; BigInteger fac = Factorial(n); Console.WriteLine(DateTimeOffset.Now - dtStart); } public static BigInteger Factorial(int n) { BigInteger fac = 1; for (int i = 1; i <= n; i++) { fac = fac * i; } return fac; } } }후회하셔도 어쩔 수 없습니다.
후회하셔도 어쩔 수 없습니다. 재밌습니다!!!
곁다리로, 프로세스가 이 CPU 저 CPU를 오가는 건 사악한 운영체제 스케줄러의 짓입니다. 너무 오래 도는 프로세스가 있으면 일단 중지시켰다가, 달리 실행할 다른 프로세스가 없으니 그 넘을 다시 실행하려 하는데 그 순간 어느 CPU를 쓸지는 그때 그때 상황에 따라 달라지기 때문입니다. 다음 코드를 넣어서 현재 CPU에서만 줄창 실행되게 하는 것도 가능합니다.
이렇게 하면 CPU를 갈아탈 때 발생하는 캐시 미스로 인한 성능 저하를 막을 수 있으므로 아주... 아주 약간 성능이 향상됩니다.
얼랭에서 한 CPU만 조지는 것처럼 보이는 건 우연일 수도 있겠고, 아니면 다중 프로세서 친화적인 얼랭 인터프리터에서 CPU 친화성을 신경써줘서일 수도 있겠네요.
결론적으로, 다음 편 기다리고 있겠습니다. /o.o/ \o.o\
$PWD `date`
이건좀... -_-
파이썬에서도 gmp를 이용하면 속도차이 거의 없습니다.
테크닉의 문제가 아니라, 왜 C만 gmp를 사용하는겁니까? 다른 언어는 몰라도 미칠듯한 외부 라이브러리 지원이 파이썬의 장정인데.. ㅠ_ㅠ (펄의 장점이기도 합니다만)
(설치 하기 힐들거나 하면 이해하지만 그런것도 아니지 않습니까? pip install gmpy 하면 깔리는데.. ㅠ_ㅠ)
import gmpy def factorial(N): fac = gmpy.mpz(1) for i in range(1, N+1): fac *= i return fac n = 50000 facN = factorial(n)그리고 파이썬스타일이라면...
import gmpy import operator def factorial(N): return reduce(operator.mul, xrange(1, N+1), gmpy.mpz(1)) n = 100000 facN = factorial(n)파이썬이 가지는 장정중의 하나가 iterable을 깔끔하게 지원하는 건데 그걸 while 구문 처럼 써버리시면.. ㅠ_ㅠ
개인적으로 잘못된 생각을 무차별적으로 전파하는 성향때문에 이런글을 대단히 싫어합니다.
따지고 보면 어차피 C, C++에서는 64비트이상의 숫자를 다둘수 조차없습니다. 그러나 이글을 보는 대부분의 사람들을 역시 C가 빠르네 하는 잘못된 선입견을 가져버릴 수 있습니다.
파이썬은 언어 자체에서 빅넘버를 지원하기 때문에
파이썬은 언어 자체에서 빅넘버를 지원하기 때문에 gmp가 따로 있을거란 생각 자체를 안했습니다. (사실 실력이 없어서...)
언어 자체에서 인터프리터 수준에서 gmp 바인딩이 되거나 내부에서 스트링으로 처리하거나.. 등 알아서 할 것이라고 생각한거죠.
그래서 얼랭에서도 아무것도 안했습니다.
C언어는 64비트 이상을 다룰 수 없기 때문에 어쩔 수 없이 쓴것이고, 파이썬이나 얼랭이나 내부에서 gmp 바인딩을 하는 것이라면
C에서 gmp를 쓰는 것이 C에 특별히 유리하다는 이유가 없으니까요.
만약 C언어도 언어에서 빅넘버를 처리했다면 gmp 따위 찾아보지도 않았을 겁니다.
따라서 제가 파이썬에서 gmp를 할 생각 조차를 안한건 전 당연하다고 생각합니다.
전 언어 자체만 두고 실험해 보려고 했으니까요. (떨어지는 실력에 대한 핑계가 이것 밖에 없네요.)
좋은 의견 감사합니다. 오늘 퇴근하고 실험해 봐야겠네요.
그런데요...
vamf12님의 댓글에서 뭍어나오는 말투가요....
"파이썬에도 gmp가 있답니다~"가 아니라
"파이썬에도 gmp가 있는데 왜 그걸 안쓰고 비교해서 부정확한 사실을 유포하고 있어!!!" 이런식으로 읽혀서,
다음글을 쓰고자하는 의지가 꺽이네요.
조금더 Positive하게 문장을 써 주시길 고개숙여 부탁드립니다.
----------------------
얇은 사 하이얀 고깔은 고이 접어서 나빌레라
선입견이라고 하기에도 뭐한게 C가 빠른건
선입견이라고 하기에도 뭐한게 C가 빠른건 사실이니까요.^^;
안그럼 리눅스도 다른걸로 만들었겠죠?
새해 복 많이 받으세요..
오류에 대한 지적은 좋은 것 같습니다.
그런데 좋은 시도 자체를 폄하하는 것은 좋지 않은 것 같습니다.
오류가 있었더라도 시도가 좋았고 많은 사람들이 애정을 가지고 지켜보고 있었으니까요.
어떤 이론이든 논문이든 오류가 있을 수 있고 그럼 그 공개된 부분의 오류를 지적하고 고쳐가면서 발전할 수 있는 것 아닌가 해서요.
오류 자체는 나쁘지 않고 (오히려 당연하죠. 돈받고 하는 것도 아니고요)
좋은 시도는 오히려 권장할만 한 것 아닌가 싶습니다.
오류에 대한 지적 역시 아주 중요하고 큰 역할을 한다고 봅니다.
하지만 이런 시도 자체를 폄하하는 것은 좀 심하지 않을까요?
저는 그냥 눈팅만 하는 입장이지만 말입니다.
부디 아무도 마음 상하지 않으시길 바랍니다.
새해 복 많이 받으시구요..
안녕하세요 잘 읽었습니다.
얼랭은 OS 커널 기반으로 돌지 않습니다.
얼랭 소스에 멀티코어 처리를 하고, 멀티 코어 환경에서 테스트 해본다면
드라마틱한 성능 향상 효과가 있을 겁니다..
잘 보았습니다 ^^
요즘 Erlang을 배우고 있어, 검색하다가 들렀어요.
재미있는 실험 같습니다.
그런데 C가 저렇게 빠른 언어였나요?
제 경우는 gmp 이런것도 처음보고, 파이썬이란건 아예 알지도 못하는 초보라..ㅎ
C가 5만 팩토리얼을 1초에 해내는 결과를 보고 갸우뚱 하네요.
아 그런데.. Erlang은 소스를 조금 수정하시는 것이 어떨까 싶어요.
파이썬을 보면 for문만 가지고 1~5만을 곱하는데,
작성하신 Erlang 소스를 보면 mk_list로 1~5만의 리스트를 먼저 구하고
그 다음에 mul_list로 곱셈 연산을 수행하기 때문에 시간이 더 걸려 공평하지 못한 실험조건이 되는 게 아닌가 생각합니다.
제 경우는 아래처럼 하여 tail recursion으로 구성을 하니 연산시간이 반 이하로 줄더라고요 ㅎ
-module(fact).
-export([fact_tr/1]).
fact_tr(0) -> 1;
fact_tr(N) when N>0 -> fact_tr(N, 1);
fact_tr(1, X) -> X;
fact_tr(X1, X2) -> fact_tr(X1-1, X1*X2).
그럼 좋은 하루 되세요~
댓글 달기